数据与计算发展前沿 ›› 2024, Vol. 6 ›› Issue (4): 96-105.
CSTR: 32002.14.jfdc.CN10-1649/TP.2024.04.008
doi: 10.11871/jfdc.issn.2096-742X.2024.04.008
• 专刊:面向国家科学数据中心的基础软件栈及系统 • 上一篇 下一篇
郭学兵1,2,*( ),朱小杰3,唐新斋1,杨刚3,侯艳飞1,2,何洪林1,2
),朱小杰3,唐新斋1,杨刚3,侯艳飞1,2,何洪林1,2
GUO Xuebing1,2,*(),ZHU Xiaojie3,TANG Xinzhai1,YANG Gang3,HOU Yanfei1,2,HE Honglin1,2
摘要:
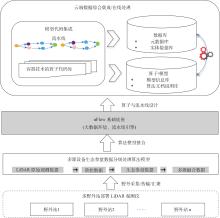
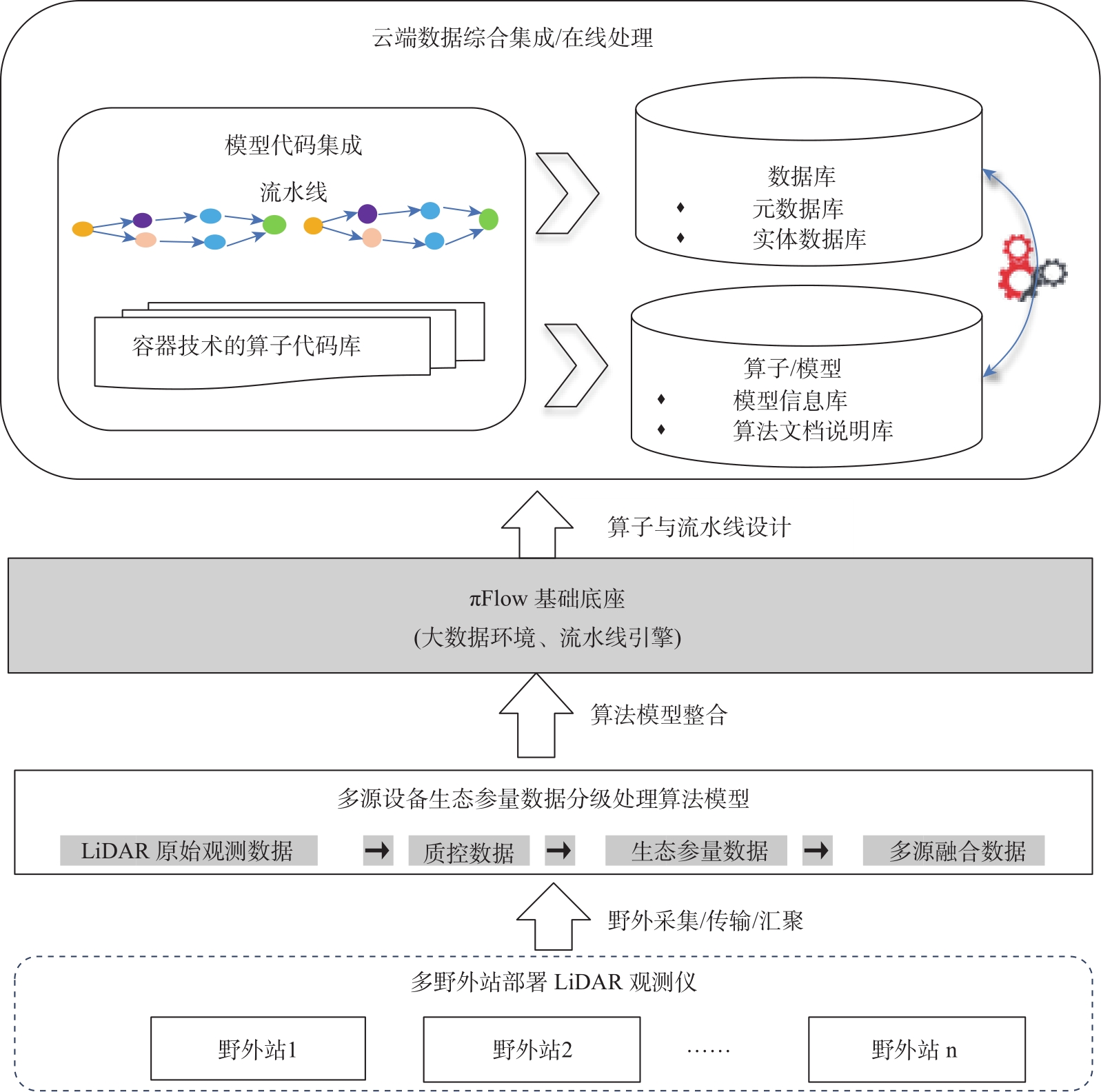
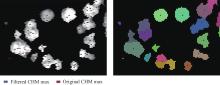
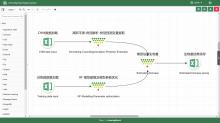
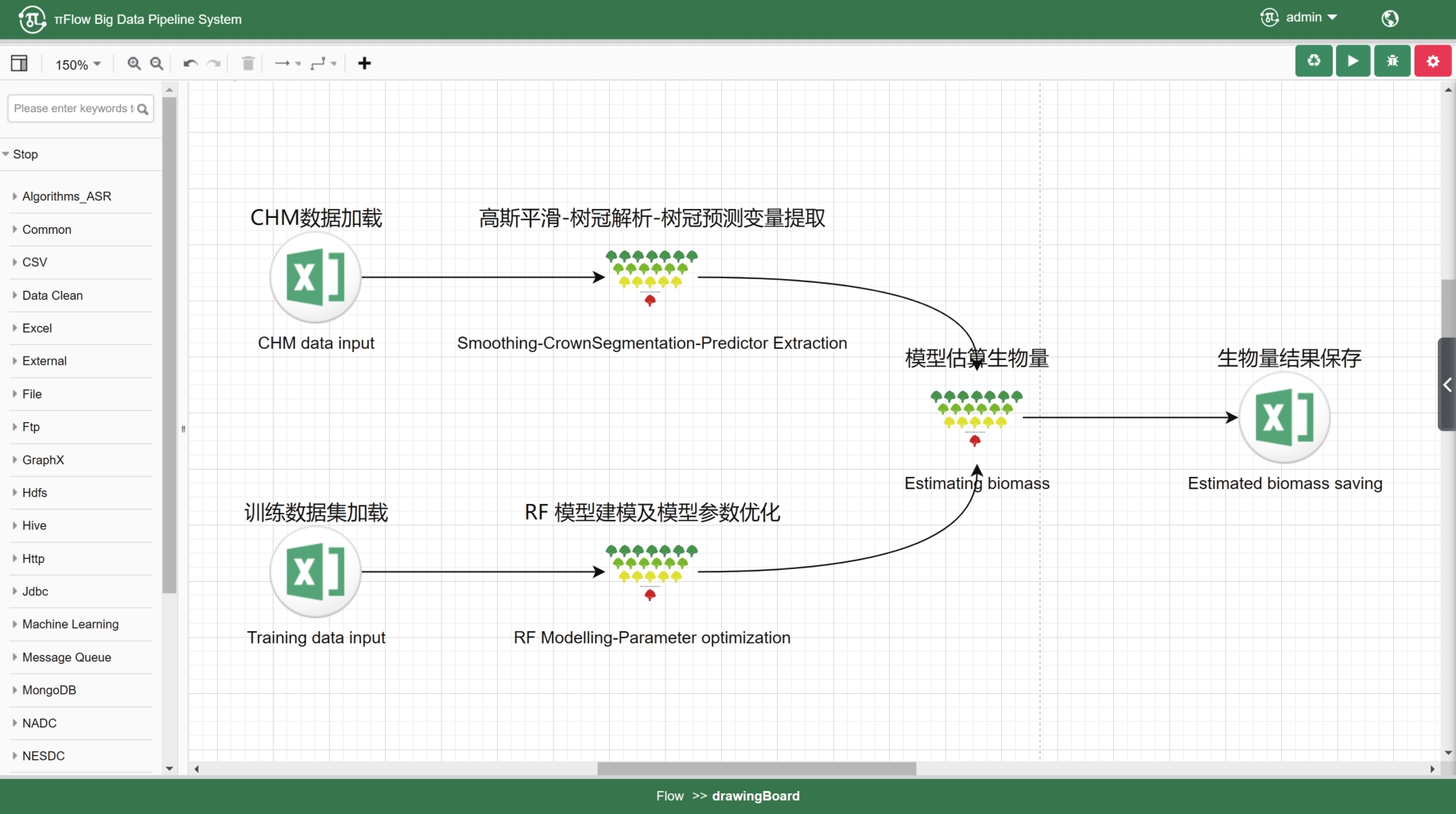
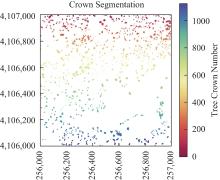
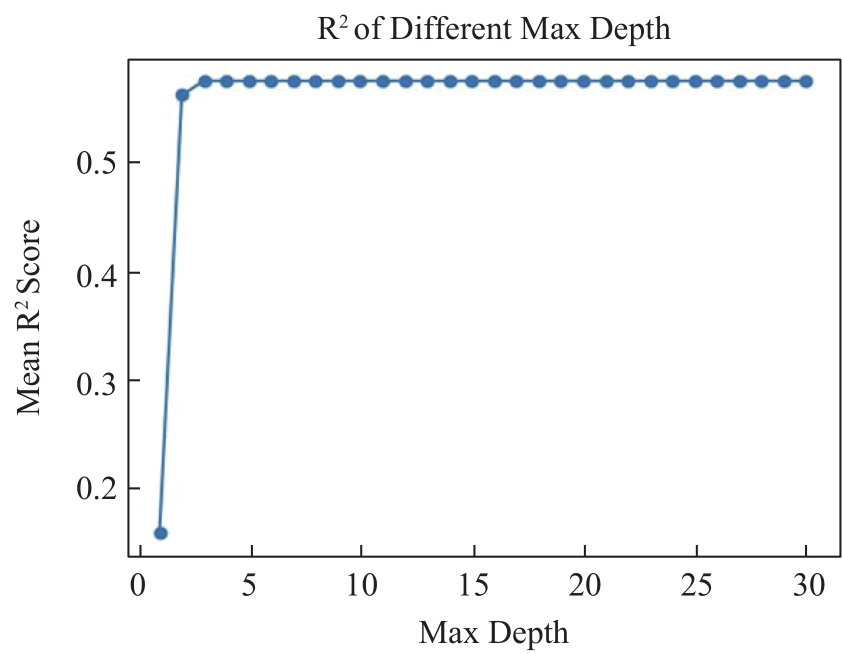
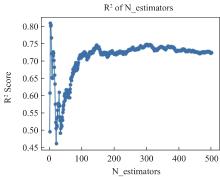
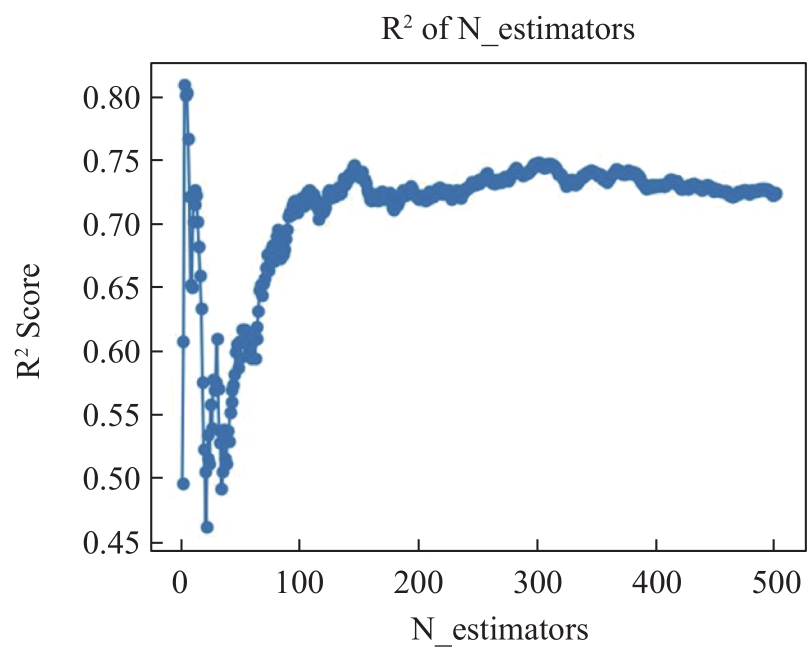
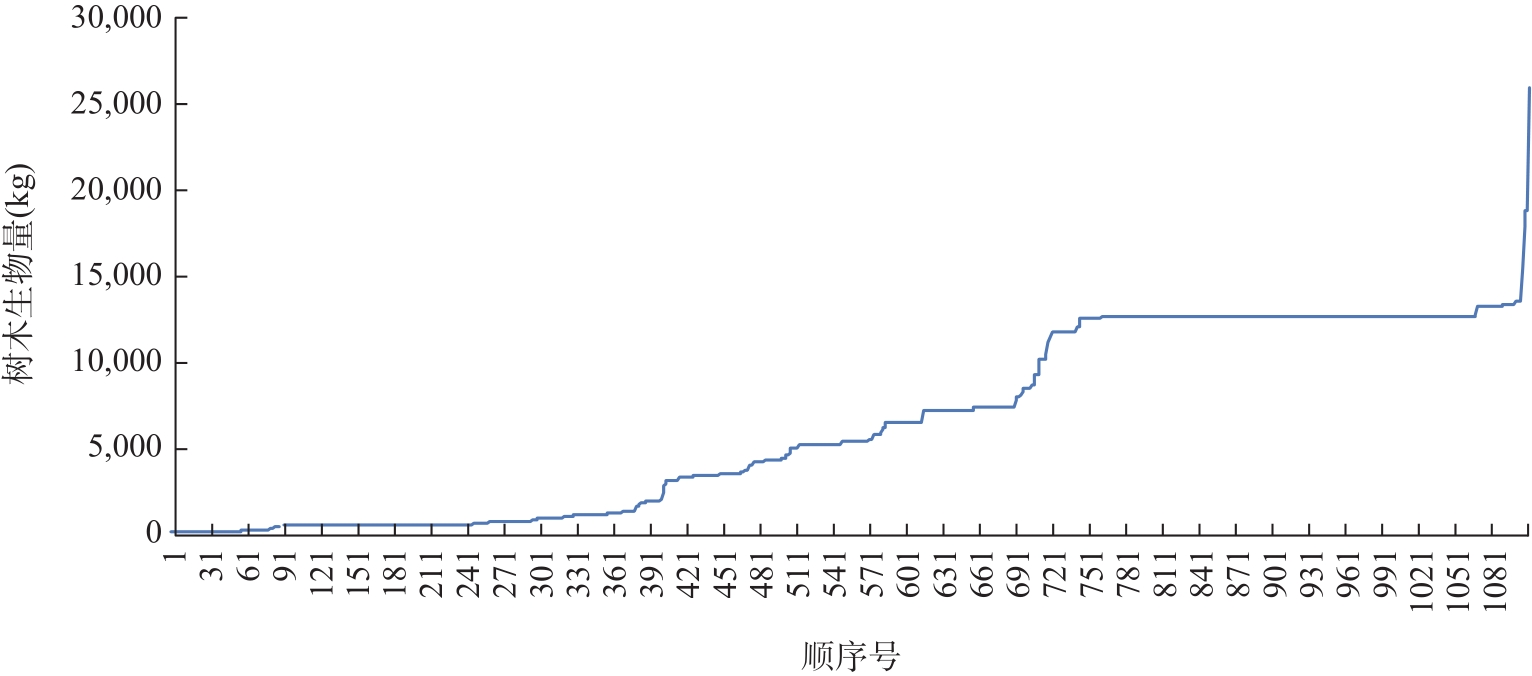
【背景】 激光雷达(LiDAR)数据在森林资源分析利用方面有着广泛应用,科研人员研制了很多涉及大数据管理和人工智能的专业算法模型,这些算法模型目前多数散落在研究人员手里,尚缺乏新型信息化平台对其进行整合。【方法】 大数据流水线系统πFlow软件具有大数据管理能力和大数据算法集成能力,并可以所见即所得方式构建流水线并调度运行流水线,适合于LiDAR数据复杂算法模型的整合,且流水线可定制、可复用。【内容】 本文介绍了πFlow的特点和功能,并以基于LiDAR冠层高度模型(CHM)数据的树冠解析及利用机器学习方法估测树木生物量为例,介绍了将算法整合到πFlow并构建LiDAR数据分析处理流水线的方法和技术,且对流水线进行了测试运行。【结果】 利用πFlow构建的可重复信息化平台可支撑野外站观测网络的LiDAR数据生物量快速反演,为数据密集型的专业数据处理算法模型的整合提供了创新方法技术。