数据与计算发展前沿 ›› 2019, Vol. 1 ›› Issue (1): 94-104.
doi: 10.11871/jfdc.issn.2096.742X.2019.01.010
所属专题: “数据与计算平台”专刊
刘汪根,孙元浩
Wanggen Liu,Yuanhao Sun
摘要:
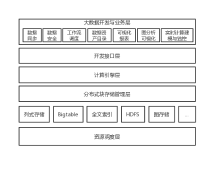
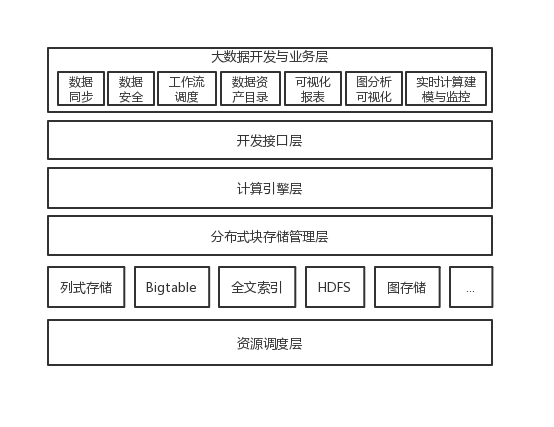
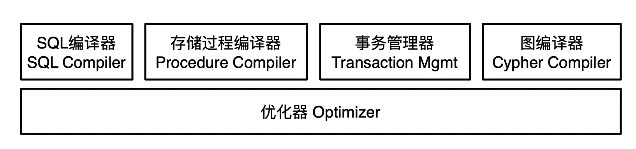
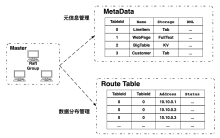
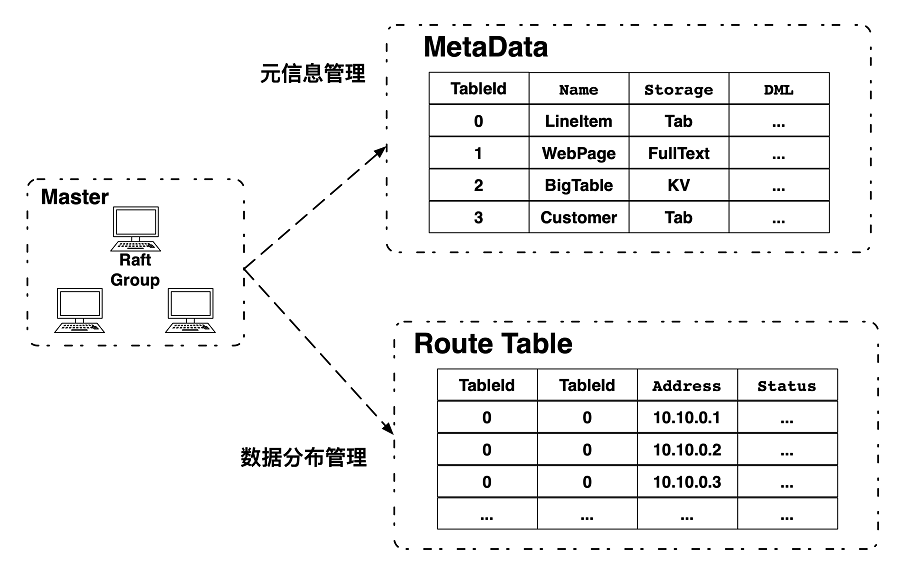
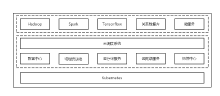
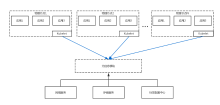
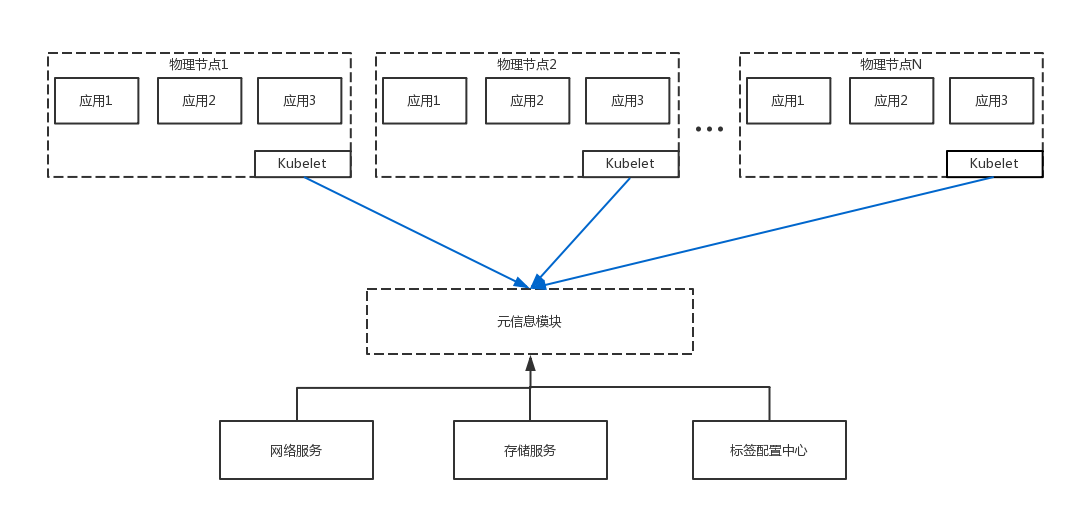
【目的】以Hadoop为代表的第一代大数据技术架构存在过于复杂、性能不足,以及与云计算不能很好结合等问题,因此星环科技重新设计了大数据技术栈。【方法】设计了资源调度层来管理各种生命周期的服务和任务;抽象出了统一存储管理层,通过插拔不同的存储引擎来实现对不同类型数据的需求;通过统一的基于DAG的计算引擎来支持多种计算负载;在开发层提供标准的SQL和Python接口。【结果】使用Kubernetes技术统一管理数据服务和容器技术实现更好的多租户能力,打通大数据和业务之间的衔接,从而更好的实现数据业务化和业务数据化,也在大规模商用中得到了验证。【结论】通过对大数据架构的重新设计,不仅有效的解决了第一代大数据实现的技术问题,而且更好的与云计算和新型硬件技术结合,可以代表新一代大数据基础技术栈的发展方向。