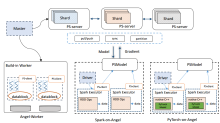
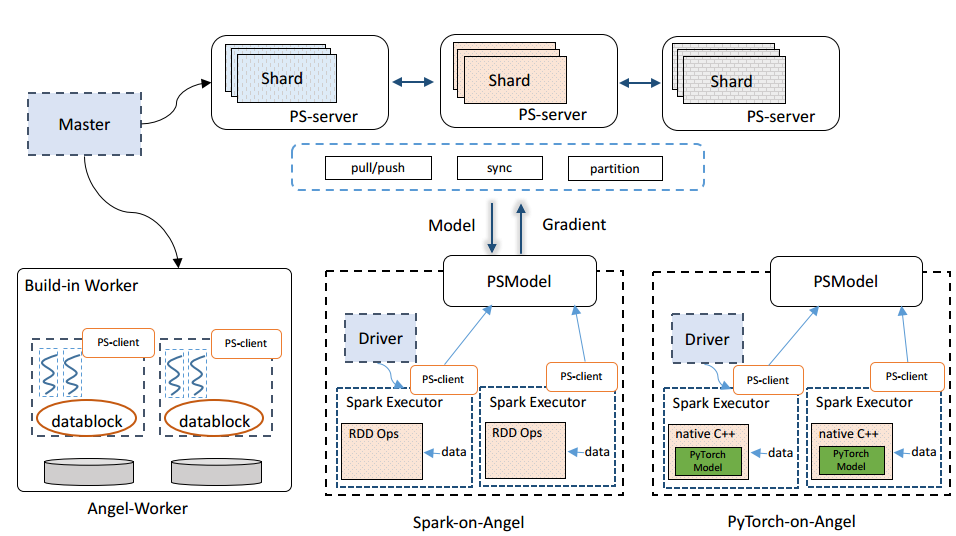
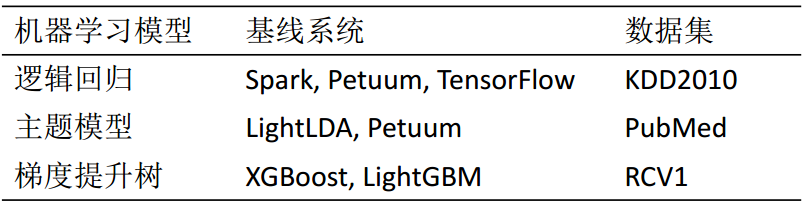
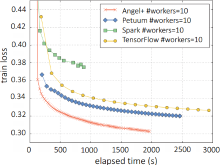
| [1] |
Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, Manjunath Kudlur, Josh Levenberg, Rajat Monga, Sherry Moore, Derek Gordon Murray, Benoit Steiner, Paul A. Tucker, Vijay Vasudevan, Pete Warden, Martin Wicke, Yuan Yu, Xiaoqiang Zheng : TensorFlow: A System for Large-Scale Machine Learning[C]. OSDI 2016, 265-283.
|
| [2] |
Tianqi Chen, Mu Li, Yutian Li, Min Lin, Naiyan Wang, Minjie Wang, Tianjun Xiao, Bing Xu, Chiyuan Zhang, Zheng Zhang : MXNet: A Flexible and Efficient Machine Learning Library for Heterogeneous Distributed Systems[C]. CoRRabs/1512.01274.
|
| [3] |
Eric P. Xing, Qirong Ho, Wei Dai, Jin Kyu Kim, Jinliang Wei, Seunghak Lee, Xun Zheng, Pengtao Xie, Abhimanu Kumar, Yaoliang Yu : Petuum: A New Platform for Distributed Machine Learning on Big Data[C]. KDD 2015, 1335-1344.
|
| [4] |
Tianqi Chen , Carlos Guestrin: XGBoost: A Scalable Tree Boosting System[C]. KDD 2016, 785-794.
|
| [5] |
Jie Jiang, Lele Yu, Jiawei Jiang, Yuhong Liu, Bin Cui : Angel: A new large scale machine learning system[J], NSR 2017, 1-21 .
|
| [6] |
Mu Li, David G. Andersen, Jun Woo Park, Alexander J. Smola, Amr Ahmed, Vanja Josifovski, James Long, Eugene J.Shekita, Bor-Yiing Su : Scaling Distributed Machine Learning with the Parameter Server[C]. OSDI 2014, 583-598.
|
| [7] |
Zhipeng Zhang, Bin Cui, Yingxia Shao, Lele Yu, Jiawei Jiang, Xupeng Miao : PS2: Parameter Server on Spark[C], SIGMOD 2019, 376-388.
|
| [8] |
Zhipeng Zhang, Jiawei Jiang, Wentao Wu, Ce Zhang, Lele Yu, Bin Cui : MLlib*: Fast Training of GLMs Using Spark MLlib [C], ICDE 2019, 1778-1789.
|
| [9] |
Jiawei Jiang, Fangcheng Fu, Tong Yang and Bin Cui : SketchML: Accelerating Distributed Machine Learning with Data Sketches [C], SIGMOD 2018, 1269-1284.
|
| [10] |
Jiawei Jiang, Bin Cui, Ce Zhang and Lele Yu : Heterogeneity-aware Distributed Parameter Servers [C], SIGMOD 2017, 463-478.
|
| [11] |
Matei Zaharia, Mosharaf Chowdhury, Michael J. Franklin, Scott Shenker, Ion Stoica : Spark: Cluster Computing with Working Sets [C]. HotCloud 2010.
|
| [12] |
Lele Yu, Ce Zhang, Yingxia Shao and Bin Cui : LDA*: A Robust and Large-scale Topic Modeling System [C], VLDB 2017, 1406-1417.
|
| [13] |
Jinhui Yuan, Fei Gao, Qirong Ho, Wei Dai, Jinliang Wei, Xun Zheng, Eric Po Xing, Tie-Yan Liu, Wei-Ying Ma : LightLDA: Big Topic Models on Modest Computer Clusters [C]. WWW 2015, 1351-1361.
|
| [14] |
Jiawei Jiang, Bin Cui, Ce Zhang and Fangcheng Fu : DimBoost: Boosting Gradient Boosting Decision Tree to Higher Dimensions [C], SIGMOD 2018, 1363-1376.
|
| [15] |
Fangcheng Fu, Jiawei Jiang, Yingxia Shao, Bin Cui : An Experimental Evaluation of Large Scale GBDT Systems [C], VLDB 2019.
|
| [16] |
Jie Jiang, Jiawei Jiang, Bin Cui and Ce Zhang : TencentBoost: A Gradient Boosting Tree System with Parameter Server [C], ICDE 2017, 281-284.
|
| [17] |
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, Tie-Yan Liu : LightGBM: A Highly Efficient Gradient Boosting Decision Tree[C]. NIPS 2017: 3146-3154.
|