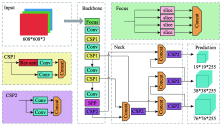
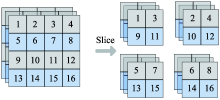
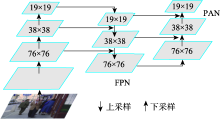
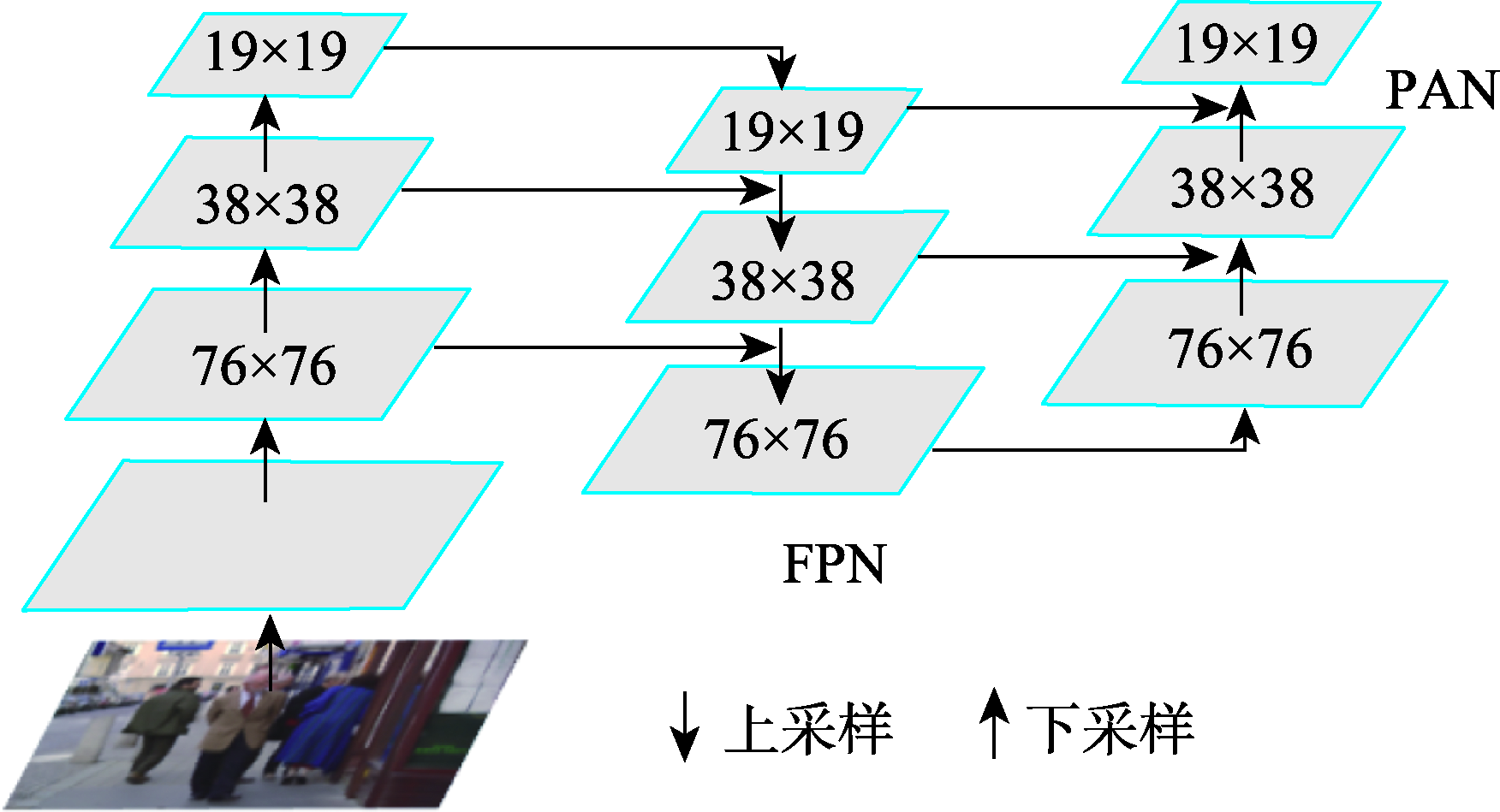
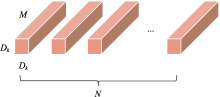
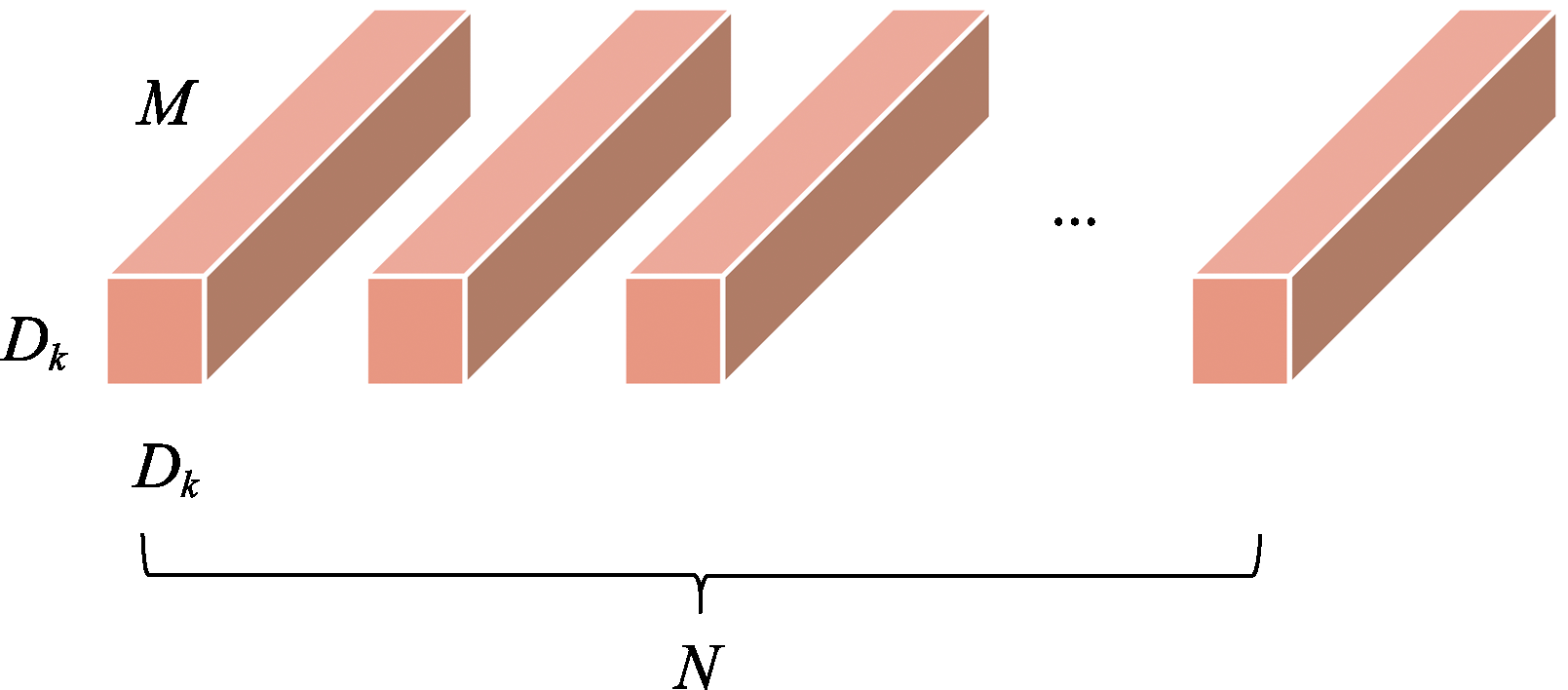
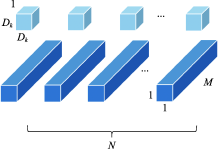
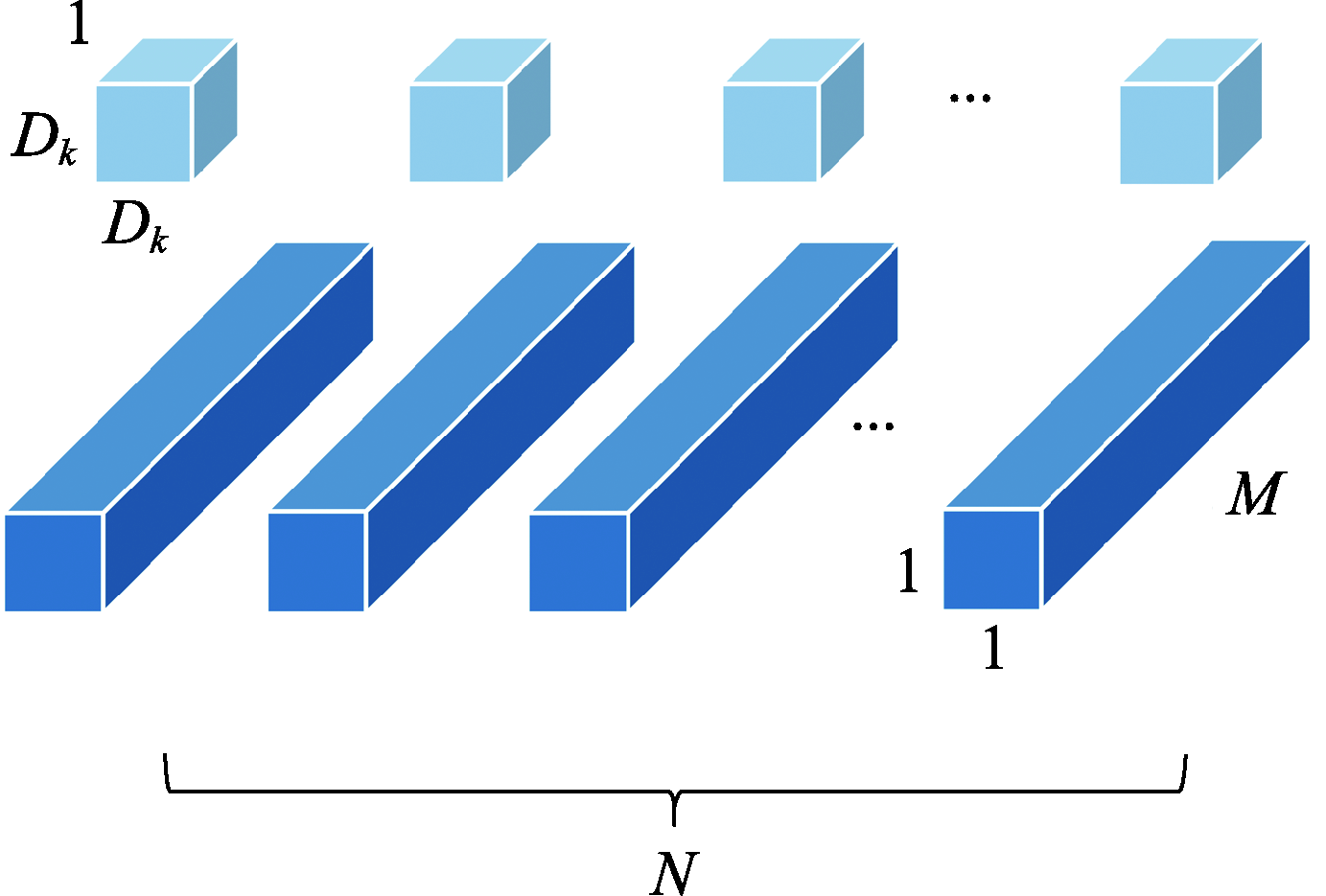
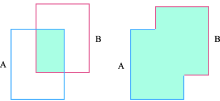
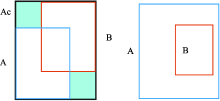
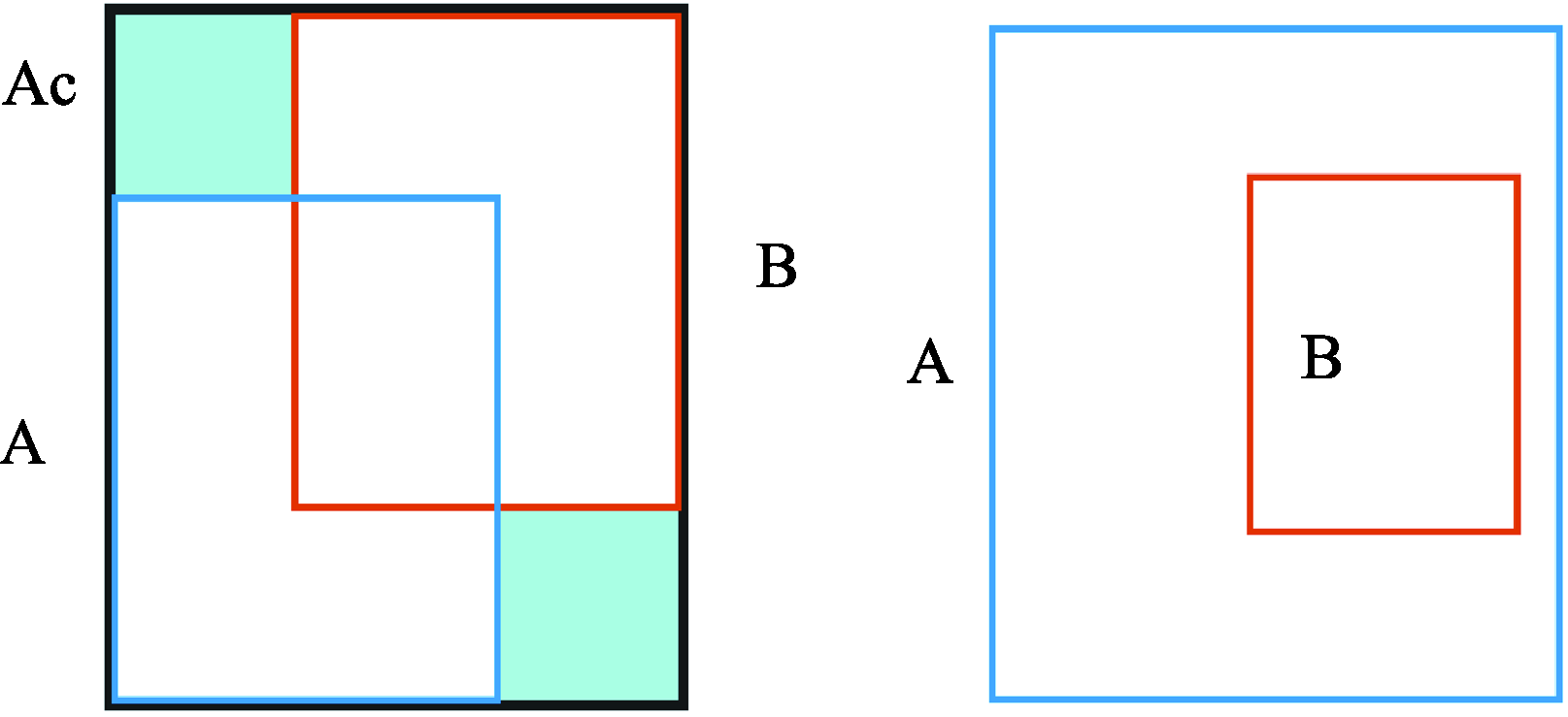
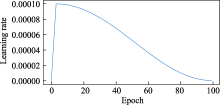
| [1] |
DALAL N, TRIGGS B. Histograms of oriented gradients for human detection[C]// 2005 IEEE computer society conference on computer vision and pattern recognition (CVPR'05), Ieee, 2005, 1: 886-893.
|
| [2] |
DOLLÁR P, TU Z, PERONA P, et al. Integral channel features[J]. Proceedings of the British Machine Conference, 2009, 91: 1-11.
|
| [3] |
LIU W, ANGUELOV D, ERHAN D, et al. Ssd: Single shot multibox detector[C]// European conference on computer vision, Springer, Cham, 2016: 21-37.
|
| [4] |
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: Unified, real-time object detection[C]// Proceedings of the IEEE conference on computer vision and pattern recognition, 2016: 779-788.
|
| [5] |
GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]// Proceedings of the IEEE conference on computer vision and pattern recognition, 2014: 580-587.
|
| [6] |
ZHAO Y, SHI Y, WANG Z. The Improved YOLOV5 Algorithm and Its Application in Small Target Detection[C]// International Conference on Intelligent Robotics and Applications, Springer, Cham, 2022: 679-688.
|
| [7] |
WOO S, PARK J, LEE J Y, et al. Cbam: Convolutional block attention module[C]// Proceedings of the European conference on computer vision (ECCV), 2018: 3-19.
|
| [8] |
ZHANG Y F, REN W, ZHANG Z, et al. Focal and efficient IOU loss for accurate bounding box regression[J]. Neurocomputing, 2022, 506: 146-157.
doi: 10.1016/j.neucom.2022.07.042
|
| [9] |
VASSILVITSKII S, ARTHUR D. k-means++: The advantages of careful seeding[C]// Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms, 2006: 1027-1035.
|
| [10] |
KIRILLOV A, GIRSHICK R, HE K, et al. Panoptic feature pyramid networks[C]// Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019: 6399-6408.
|
| [11] |
REZATOFIGHI H, TSOI N, GWAK J Y, et al. Generalized intersection over union: A metric and a loss for bounding box regression[C]// Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019: 658-666.
|
| [12] |
CHOLLET F. Xception: Deep learning with depthwise separable convolutions[C]// Proceedings of the IEEE conference on computer vision and pattern recognition, 2017: 1251-1258.
|
| [13] |
ZHU X, CHENG D, ZHANG Z, et al. An empirical study of spatial attention mechanisms in deep networks[C]// Proceedings of the IEEE/CVF international conference on computer vision, 2019: 6688-6697.
|
| [14] |
SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-cam: Visual explanations from deep networks via gradient-based localization[C]// Proceedings of the IEEE international conference on computer vision, 2017: 618-626.
|
| [15] |
YU J, JIANG Y, WANG Z, et al. Unitbox: An advanced object detection network[C]// Proceedings of the 24th ACM international conference on Multimedia, 2016: 516-520.
|
| [16] |
AGARWAL N, GOEL S, ZHANG C. Acceleration via fractal learning rate schedules[C]// International Conference on Machine Learning, PMLR, 2021: 87-99.
|
| [17] |
TANG S, GOTO S. Histogram of template for human detection[C]// 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, IEEE, 2010: 2186-2189.
|
| [18] |
REN S, HE K, GIRSHICK R, et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(06): 1137-1149.
|
| [19] |
LI J, LIANG X, SHEN S M, et al. Scale-aware fast R-CNN for pedestrian detection[J]. IEEE transactions on Multimedia, 2017, 20(4): 985-996.
|
| [20] |
GIRSHICK R. Fast r-cnn[C]// Proceedings of the IEEE international conference on computer vision, 2015: 1440-1448.
|
| [21] |
WANG X, XIAO T, JIANG Y, et al. Repulsion loss: Detecting pedestrians in a crowd[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 7774-7783.
|
| [22] |
LIU W, LIAO S, HU W. Efficient Single-Stage Pedestrian Detector by Asymptotic Localization Fitting and Multi-Scale Context Encoding[J]. IEEE Transactions on Image Processing, 2019, 29(99): 1413-1425.
doi: 10.1109/TIP.83
|
| [23] |
LIU W, HASAN I, LIAO S. Center and Scale Prediction: Anchor-free Approach for Pedestrian and Face Detection[J]. arXiv preprint arXiv:1904.02948, 2019.
|
 ),王国中*(
),王国中*(