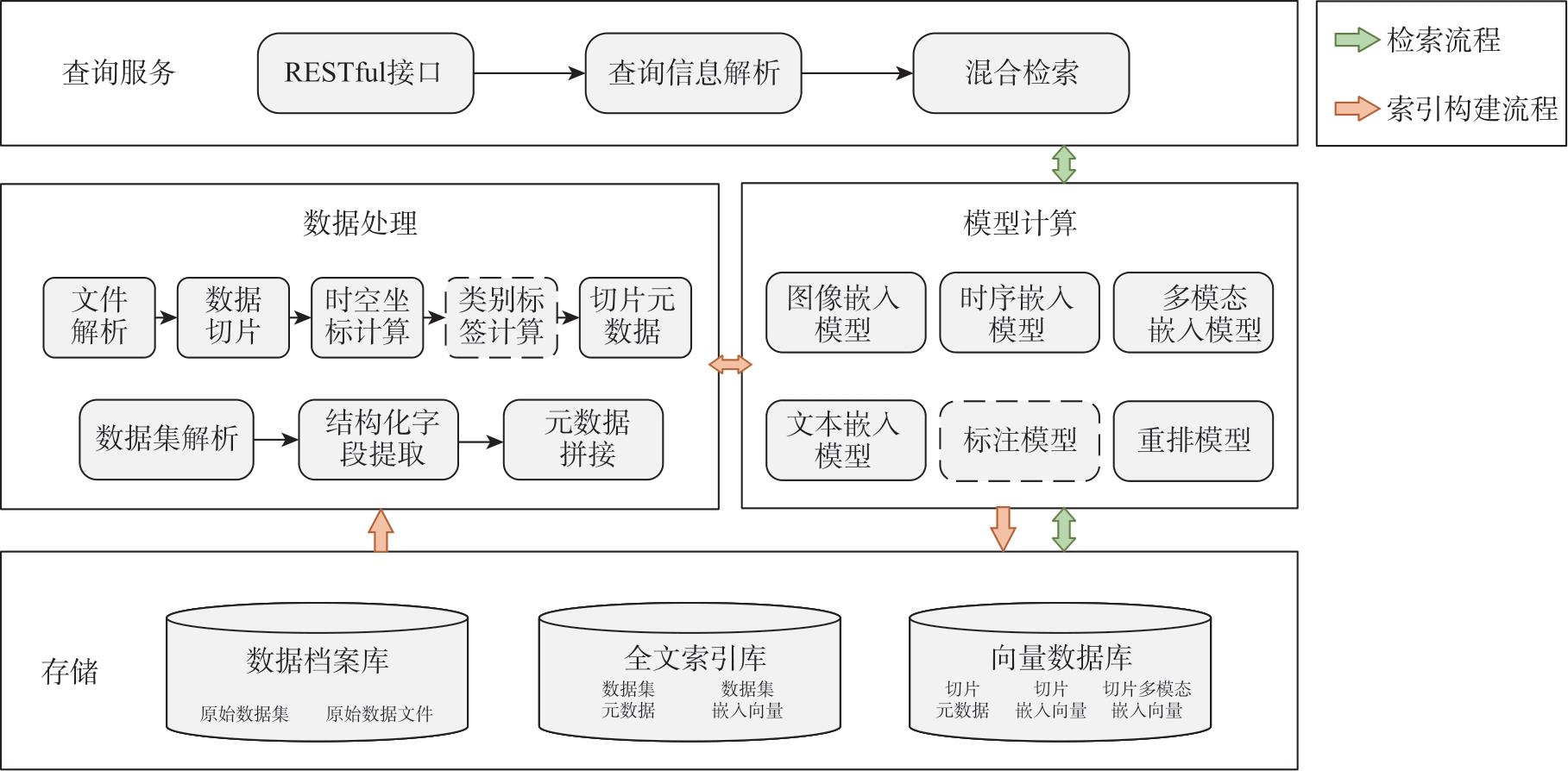
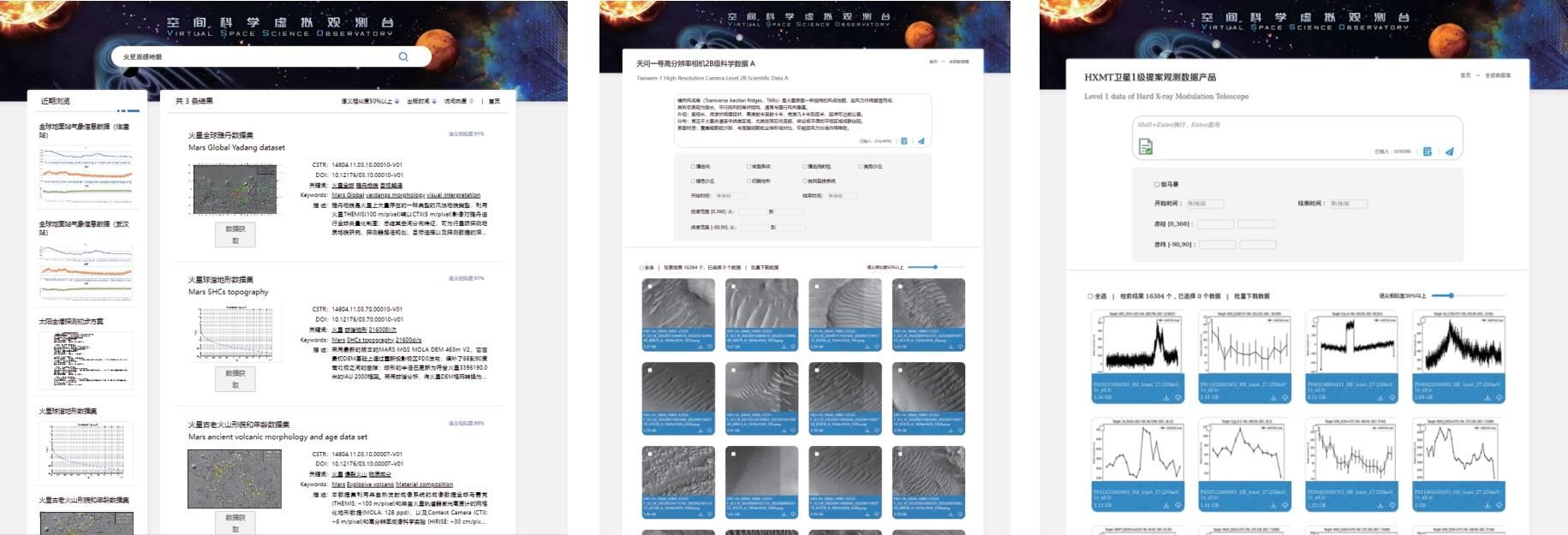
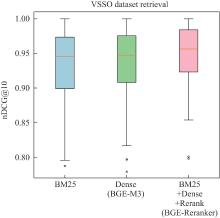
| [1] |
Space Physics Data Facility[DB/OL]. [2025-04-27]. https://spdf.gsfc.nasa.gov/.
|
| [2] |
Planetary Data System[DB/OL]. [2025-04-27]. https://pds.nasa.gov/
|
| [3] |
Mikulski Archive for Space Telescopes[DB/OL]. [2025-04-27]. https://archive.stsci.edu/.
|
| [4] |
空间科学虚拟观测台[DB/OL]. [2025-04-27]. https://www.nssdc.ac.cn/nssdc_zh/html/index.html.
|
| [5] |
PDS Image Atlas[DB/OL]. [2025-04-27]. https://pds-imaging.jpl.nasa.gov/search/.
|
| [6] |
Heliophysics Events Knowledgebase[DB/OL]. [2025-04-27]. https://www.lmsal.com/hek/.
|
| [7] |
BERRIMAN G B. The international virtual observatory alliance (IVOA) in 2020[J/OL]. arXiv preprint, 2020: arXiv:2012.05988.
|
| [8] |
SAWARKAR K, MANGAL A, SOLANKI S R.Blended rag: Improving rag (retriever-augmented generation) accuracy with semantic search and hybrid query-based retrievers[C]// In 2024 IEEE 7th International Conference on Multimedia Information Processing and Retrieval (MIPR). 2024: 155-161.
|
| [9] |
CHEN J, XIAO S, ZHANG P, et al. Bge m3-embedding:Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation[J/OL]. arXiv preprint, 2024: arXiv:2402.03216.
|
| [10] |
LI C, LIU Z, XIAO S, et al. Making large language models a better foundation for dense retrieval[J/OL]. arXiv preprint, 2023: arXiv:2312.15503.
|
| [11] |
OQUAB M, DARCET T, MOUTAKANNI T, et al. DINOv2: Learning Robust Visual Features without Supervision[J]. Transactions on Machine Learning Research Journal, 2024, 11:1-31.
|
| [12] |
DARCET T, OQUAB M, MAIRAL J, et al. Vision transformers need registers[J/OL]. arXiv preprint, 2023:arXiv:2309.16588.
|
| [13] |
RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C] // In International conference on machine learning. 2021, 1: 8748-8763.
|
| [14] |
ZHOU J, LIU Z, XIAO S, et al. VISTA: Visualized Text Embedding For Universal Multi-Modal Retrieval[C] // In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics. 2024, 1: 3185-3200.
|
| [15] |
YUE Z, WANG Y, DUAN J, et al. Ts2vec: Towards universal representation of time series[C] // In Proceedings of the AAAI conference on artificial intelligence. 2022, 36(8): 8980-8987.
|
| [16] |
WU H, HU T, LIU Y, et al. Timesnet: Temporal 2d-variation modeling for general time series analysis[J]. arXiv preprint, 2022:arXiv:2210.02186.
|
| [17] |
LIU Y, QIN G, HUANG X, et al. Timer-XL: Long-Context Transformers for Unified Time Series Forecasting[J]. arXiv preprint, 2024: arXiv:2410.04803.
|
| [18] |
KWON W, LI Z, ZHUANG S, et al. Efficient memory management for large language model serving with paged attention[C] // In Proceedings of the 29th Symposium on Operating Systems Principles. 2023: 611-626.
|
| [19] |
YANG A, LI A, YANG B, et al. Qwen3 technical report[J]. arXiv preprint, 2025:arXiv:2505.09388.
|
| [20] |
DORAN G, DUNKEL E, LU S, et al. Mars orbital image (HiRISE) labeled data set version 3.2[DB/OL]. [2025-05-21]. https://zenodo.org/records/4002935.
|
| [21] |
GASTEL R V. Finetuning DINOv2 with LoRA for Image Segmentation[CP/OL]. [2025-06-17].https://github.com/RobvanGastel/dinov2-finetune.
|
 ),焦琦融1,王慈枫2,邹自明1,*(
),焦琦融1,王慈枫2,邹自明1,*(