数据与计算发展前沿 ›› 2023, Vol. 5 ›› Issue (1): 97-103.
CSTR: 32002.14.jfdc.CN10-1649/TP.2023.01.009
doi: 10.11871/jfdc.issn.2096-742X.2023.01.009
彭亮*( ),牛铁,魏宝亮,赵毅
),牛铁,魏宝亮,赵毅
PENG Liang*(),NIU Tie,WEI Baoliang,ZHAO Yi
摘要:
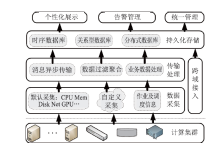
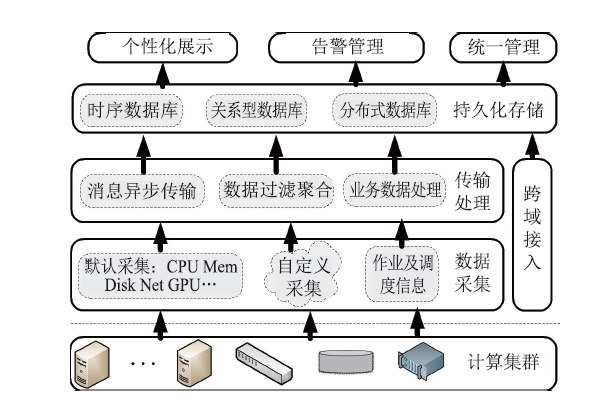
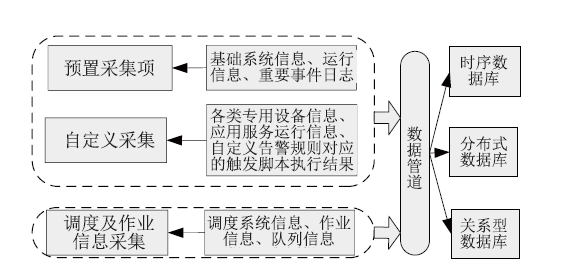
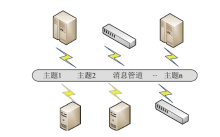
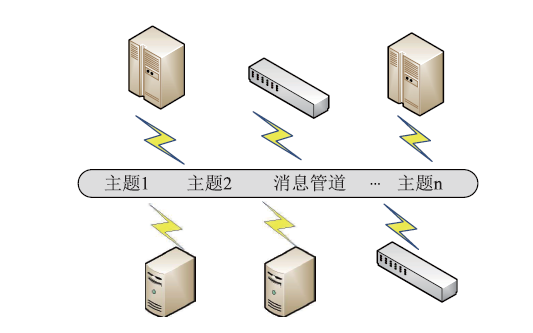
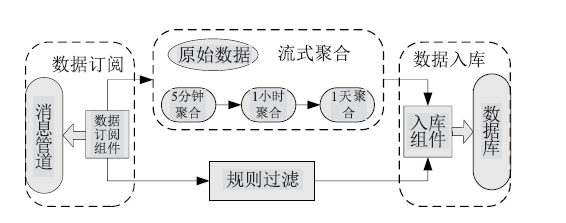
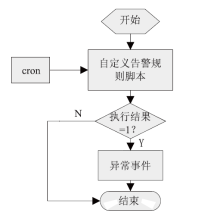
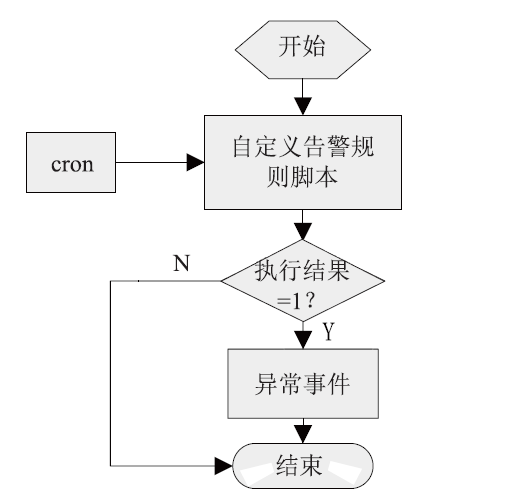
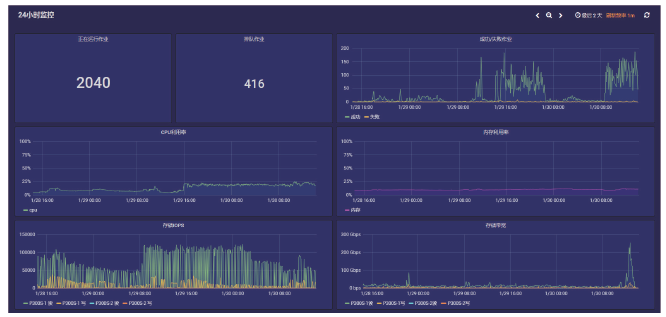
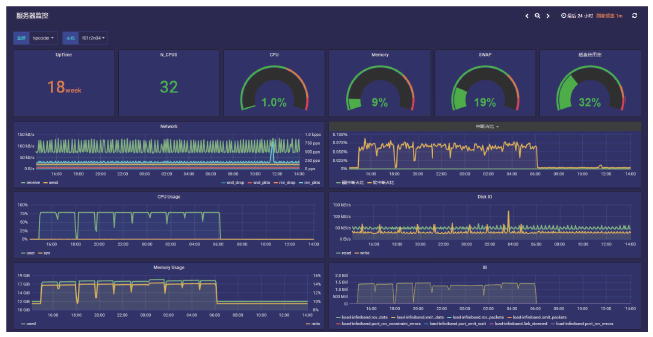
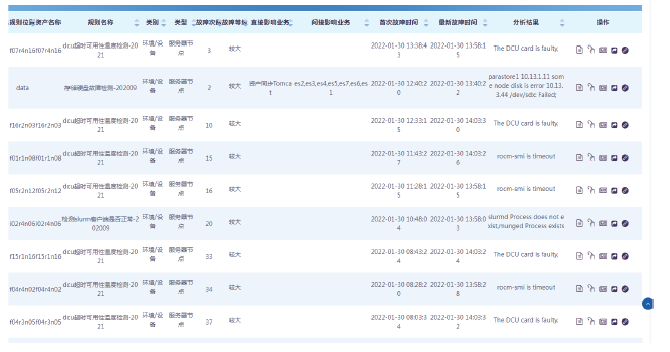
【背景】传统集群监控软件在性能、灵活性、可扩展性上无法满足超过10000节点的超大规模计算集群以及多集群系统的监控管理需求。【目的】亟需设计研发新型集群监控系统,提升超大规模计算集群和多集群的运行管理能力与效率。【方法】本文采用总分架构设计,利用消息中间件、分布式存储、REST技术实现了一种超大规模计算集群监控系统。【结果】该系统支持监控指标自定义、数据主动上发、自动告警等功能,具有良好的横向扩展能力。已部署于多套计算集群中,满足上万节点和设备的监控需求,日均采集数据逾200GB。【局限】由于监控指标繁多、监控数据量庞大,针对业务场景的数据关联分析能力有待提升。【结论】本文工作满足了超大规模计算集群及异地多集群系统的自动运管需求,采用的方法对更大规模集群甚至E级计算系统的运管工具的研发具有积极借鉴意义。