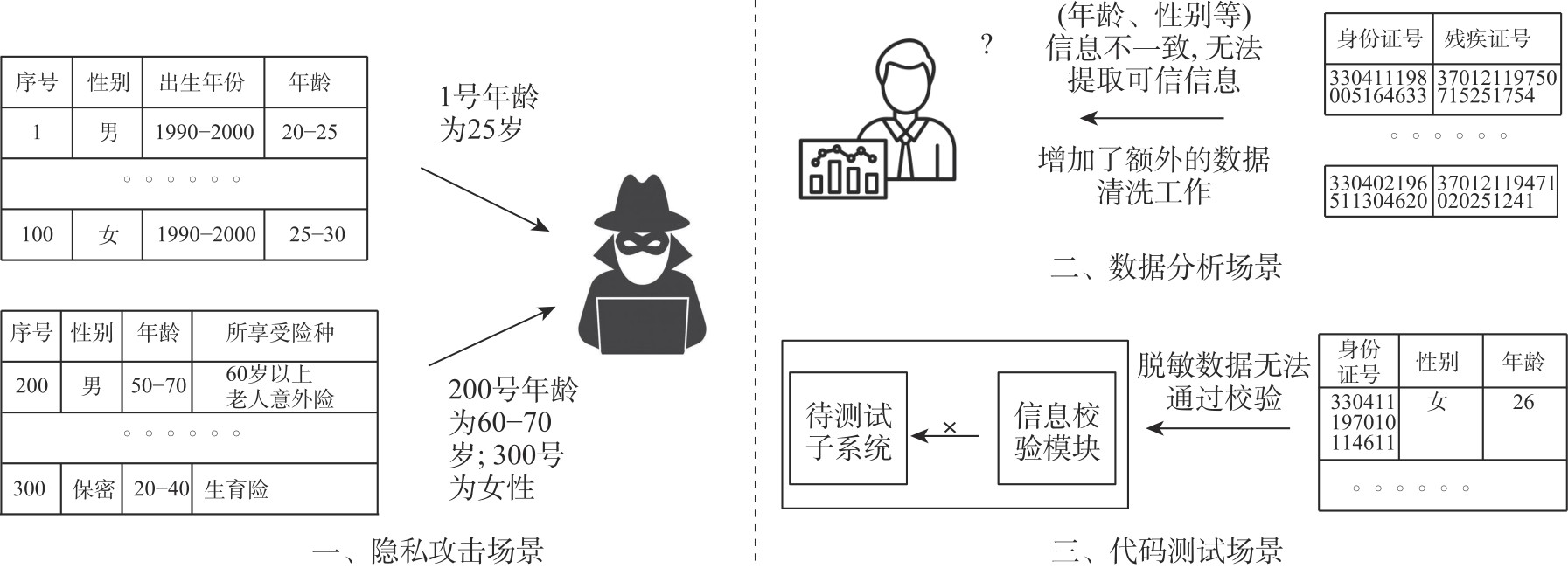
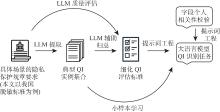
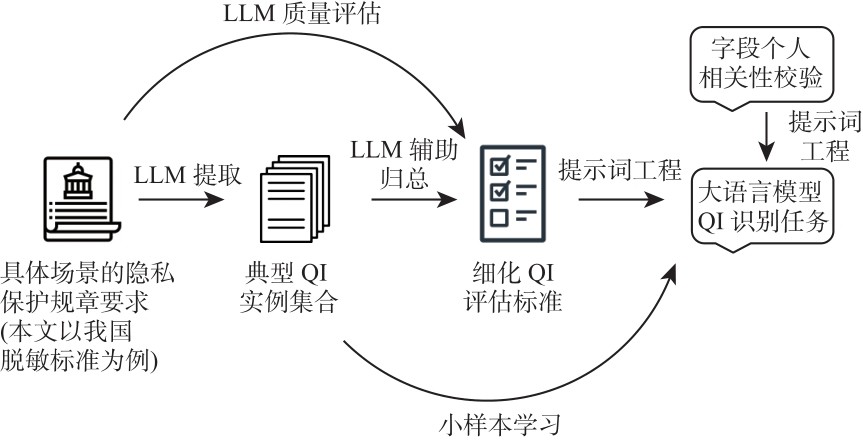
| [1] |
WOOD A, ALTMAN M, BEMBENEK A, et al. Differential privacy: A primer for a non-technical audience[J]. Vanderbilt Journal of Entertainment & Technology Law, 2018, 21: 209.
|
| [2] |
KOCAMAN V, TALBY D, HAK H U. RWD143 Beyond Accuracy: Automated De-Identification of Large Real-World Clinical Text Datasets[J]. Value in Health, 2023, 26(12): S532.
|
| [3] |
LAMPLE G, BALLESTEROS M, SUBRAMANIAN S, et al. Neural Architectures for Named Entity Recognition[C]// Proceedings of NAACL-HLT. 2016: 260-270.
|
| [4] |
SHYAMASUNDAR R K, MAURYA M K. Anonymization of bigdata using ARX tools[C]// 2024 15th International Conference on Information and Communication Systems (ICICS). IEEE, 2024: 1-6.
|
| [5] |
JUNG J, PARK P, LEE J, et al. A determination scheme for quasi-identifiers using uniqueness and influence for de-identification of clinical data[J]. Journal of Medical Imaging and Health Informatics, 2020, 10(2): 295-303.
doi: 10.1166/jmihi.2020.2966
|
| [6] |
HUA Y, LI Z, SHENG H, et al. A Method for Finding Quasi-identifier of Single Structured Relational Data[C]// 2021 7th IEEE Intl Conference on Big Data Security on Cloud (BigDataSecurity), IEEE Intl Conference on High Performance and Smart Computing,(HPSC) and IEEE Intl Conference on Intelligent Data and Security (IDS). IEEE, 2021: 93-98.
|
| [7] |
OLATUNJI I E, RAUCH J, KATZENSTEINER M, et al. A review of anonymization for healthcare data[J]. Big Data, 2024, 12(6): 538-555.
doi: 10.1089/big.2021.0169
|
| [8] |
SWEENEY L. Achieving k-anonymity privacy protection using generalization and suppression[J]. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 2002, 10(5): 571-588.
doi: 10.1142/S021848850200165X
|
| [9] |
国家市场监督管理总局, 中国国家标准化管理委员会. GB/T 37964-2019 信息安全技术个人信息去标识化指南[S]. 北京: 中国标准出版社.
|
| [10] |
SONG Y, WANG T, CAI P, et al. A comprehensive survey of few-shot learning: Evolution, applications, challenges, and opportunities[J]. ACM Computing Surveys, 2023, 55(13s): 1-40.
|
| [11] |
SLIJEPČEVIĆ D, HENZL M, KLAUSNER L D, et al. k-anonymity in practice: How generalisation and suppression affect machine learning classifiers[J]. Computers & Security, 2021, 111: 102488.
doi: 10.1016/j.cose.2021.102488
|
| [12] |
姚思诚, 陈海粟, 廖佳纯. 公共数据开发中个人信息识别挑战[J]. 信息安全研究, 2024, 10(E2): 240.
|
| [13] |
ARSLAN M, GHANEM H, MUNAWAR S, et al. A Survey on RAG with LLMs[J]. Procedia Computer Science, 2024, 246: 3781-3790.
doi: 10.1016/j.procs.2024.09.178
|
| [14] |
WEI J, WANG X, SCHUURMANS D, et al. Chain-of-thought prompting elicits reasoning in large language models[J]. Advances in Neural Information Processing Systems, 2022, 35: 24824-24837.
|
 ),廖佳纯*(
),廖佳纯*(