| [1] |
白皓然, 孙伟浩, 金宁, 等. 基于改进Bi-LSTM-CRF的农业问答系统研究[J]. 中国农机化学报, 2023, 44(2): 99-105.
|
| [2] |
王东升, 王卫民, 王石, 等. 面向限定领域问答系统的自然语言理解方法综述[J]. 计算机科学, 2017, 44(8): 1-8.
doi: 10.11896/j.issn.1002-137X.2017.08.001
|
| [3] |
GUU K, LEE K, TUNG Z, et al. Retrieval augmented language model pre-training[C]// Proceedings of the 37th International Conference on Machine Learning, Vienna. New York: PMLR, 2020: 3929-3938.
|
| [4] |
CHOWDHERY A, NARANG S, DEVLIN J, et al. PaLM: scaling language modeling with pathways[J/OL]. arXiv:2204.02311, 2022. [2023.11.20]https://doi.org/10.48550/arXiv.2204.02311.
|
| [5] |
WEI J, TAY Y, BOMMASANI R, et al. Emergent abilities of large language models[J/OL]. arXiv:2206. 07682, 2022. [2023-11-20] https://doi.org/10.48550/arXiv.2206.07682.
|
| [6] |
RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving language understanding by generative pre-training[J/OL]. Preprint, 2018. [2023-11-20] https://api.semanticscholar.org/CorpusID:49313245.
|
| [7] |
RADFORD A, WU J, CHILD R, et al. Language models are unsupervised multitask learners[J]. OpenAI Blog, 2019, 1(8): 9.
|
| [8] |
BROWN T, MANN B, RYDER N, et al. Language models are few-shot learners[J]. Advances in neural information processing systems, 2020, 33: 1877-1901.
|
| [9] |
DEVLIN J, CHANG M W, LEE K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J/OL]. arXiv preprint arXiv:1810.04805, 2018. [2023-11-20] https://doi.org/10.48550/arXiv.1810.04805.
|
| [10] |
SONG K, TAN X, QIN T, et al. Mass: Masked sequence to sequence pre-training for language generation[J/OL]. arXiv preprint arXiv:1905.02450, 2019. [2023-11-20] https://doi.org/10.48550/arXiv.1905.02450.
|
| [11] |
LEWIS M, LIU Y, GOYAL N, et al. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension[J/OL]. arXiv preprint arXiv:1910.13461, 2019. [2023-11-20] https://doi.org/10.48550/arXiv.1910.13461.
|
| [12] |
BI B, LI C, WU C, et al. Palm: Pre-training an autoencoding&autoregressive language model for context-conditioned generation[J/OL]. arXiv preprint arXiv:2004.07159, 2020. [2023-11-20] https://doi.org/10.48550/arXiv.2004.07159.
|
| [13] |
MAYNEZ J, NARAYAN S, BOHNET B, et al. On faithfulness and factuality in abstractive summarization[J/OL]. arXiv:2005.00661, 2020. [2023-11-20] https://doi.org/10.48550/arXiv.2005.00661.
|
| [14] |
HU E J, SHEN Y, WALLIS P, et al. Lora: Low-rank adaptation of large language models[J/OL]. arXiv preprint arXiv:2106.09685, 2021. [2023-11-20] https://doi.org/10.48550/arXiv.2106.09685.
|
| [15] |
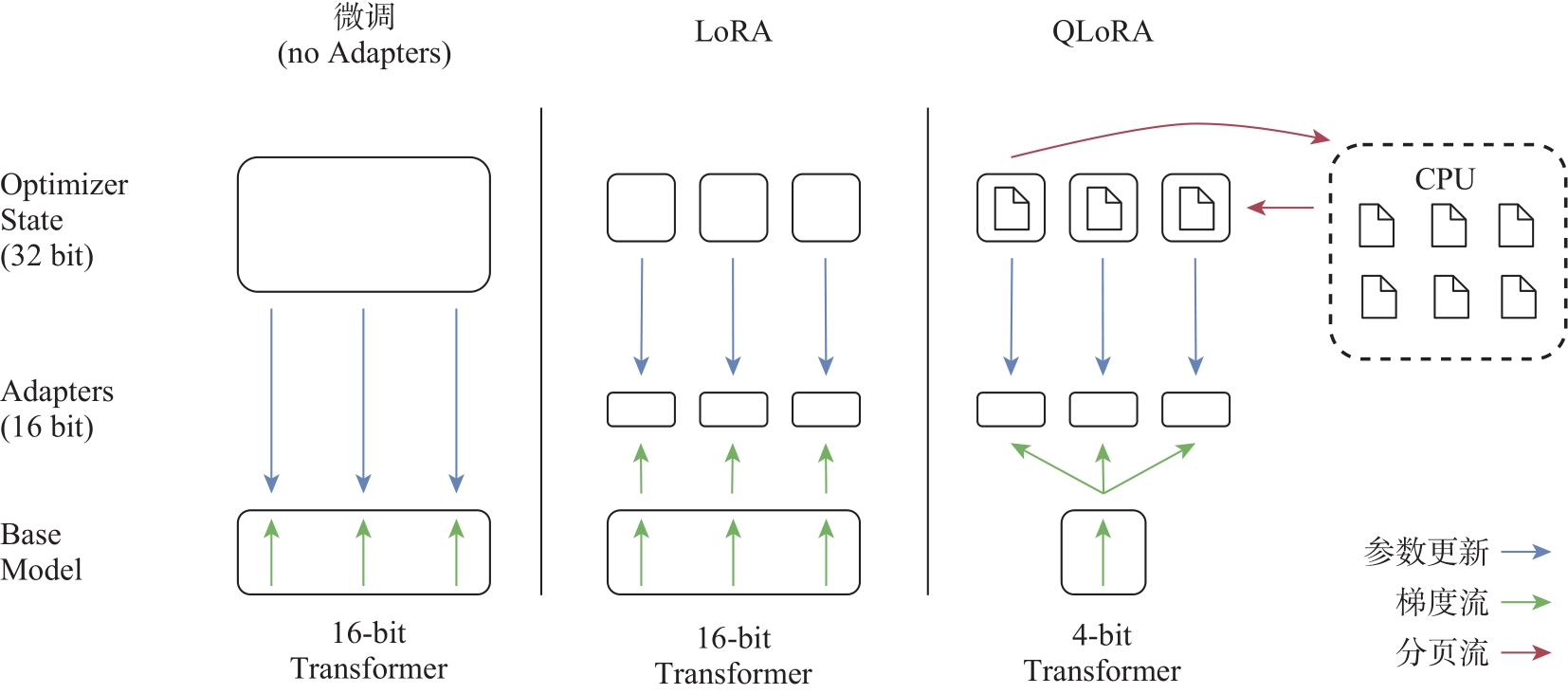
DETTMERS T, PAGNONI A, HOLTZMAN A, et al. Qlora: Efficient finetuning of quantized llms[J/OL]. arXiv preprint arXiv:2305.14314, 2023. [2023-11-20] https://doi.org/10.48550/arXiv.2305.14314.
|
| [16] |
ZENG A, LIU X, DU Z, et al. Glm-130b: An open bilingual pre-trained model[J/OL]. arXiv preprint arXiv: 2210.02414, 2022. [2023-11-20] https://doi.org/10. 48550/arXiv.2210.02414.
|
| [17] |
DU Z, QIAN Y, LIU X, et al. Glm: General language model pretraining with autoregressive blank infilling[J/OL]. arXiv preprint arXiv:2103.10360, 2021. [2023-11-20] https://doi.org/10.48550/arXiv.2103.10360.
|
 ),樊景超1,2,*(
),樊景超1,2,*(