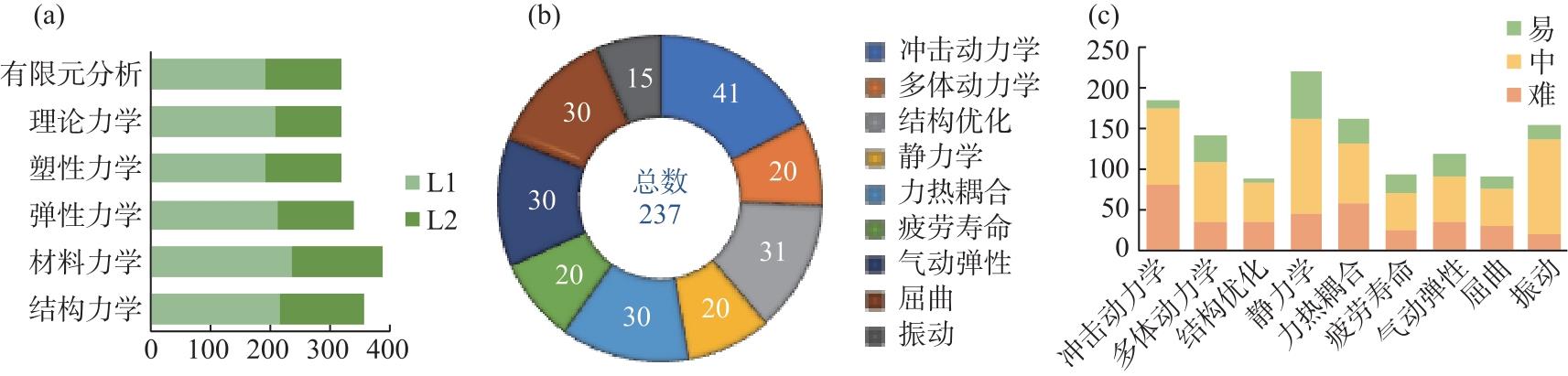
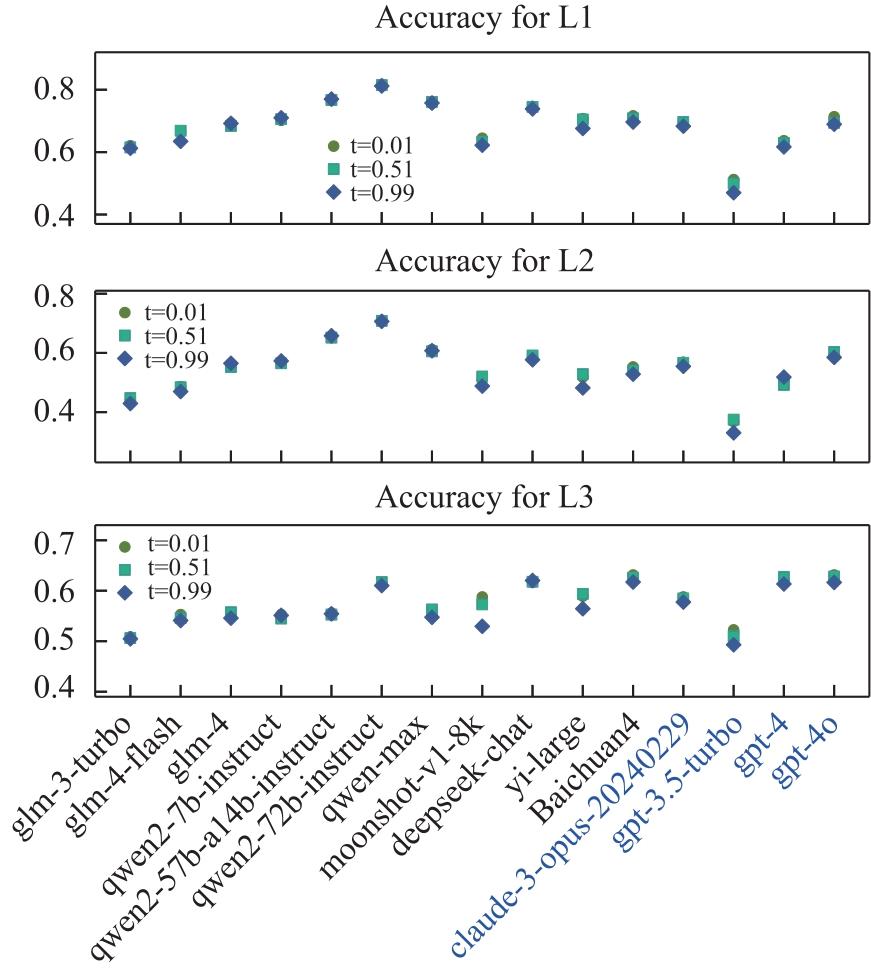
| [1] |
桑基韬, 于剑. 从ChatGPT看AI未来趋势和挑战[J]. 计算机研究与发展, 2023, 60(6): 1191-1201.
|
| [2] |
魏子舒, 韩越, 刘思浩, 等. 2021至2023年人工智能领域研究热点分析述评与展望[J]. 计算机研究与发展, 2024, 61(5): 1261-1275.
|
| [3] |
任天宇, 韩非, 张玲, 等. 结构损伤与断裂力学分析CAE软件发展现状[J/OL]. 计算力学学报, 1-16. http://kns.cnki.net/kcms/detail/21.1373.O3.20241025.1537.010.html.
|
| [4] |
吕成. 基于FLUENT的船用铝合金板激光焊接数值仿真分析[J]. 计算机辅助工程, 2024, 33(3): 7-12.
|
| [5] |
李睿, 孟思勤, 郝丽杰, 等. 基于金属磁量热技术的拾波线圈电磁性能仿真模拟[J]. 原子能科学技术, 2023, 57(9): 1835-1840.
doi: 10.7538/yzk.2022.youxian.0883
|
| [6] |
周烨, 温玮. Comsol有限元软件在大型水下目标声学仿真上的应用[J]. 计算机应用与软件, 2020, 37(8): 74-78+84.
|
| [7] |
于博文, 何孝天, 徐进良. 超临界CO2池式换热实验与数值模拟研究[J]. 中国科学: 技术科学, 2024, 54(04): 636-644.
|
| [8] |
吴长鹏, 谢斌, 潘锋, 等. 汽车动力总成悬置的碰撞失效模拟研究[J]. 汽车工程, 2019, 41(1): 36-41+63.
|
| [9] |
荣吉利, 宋逸博, 王玺, 等. 核爆炸对地冲击作用下土体运动特性等效模拟[J]. 兵工学报, 2021, 42(1): 56-64.
|
| [10] |
胡涛, 申立群, 田宇阳, 等. 航天复杂系统测发控流程仿真引擎设计与评价[J]. 系统工程与电子技术, 2023, 45(12): 3866-3874.
doi: 10.12305/j.issn.1001-506X.2023.12.16
|
| [11] |
王彬文, 段世慧, 聂小华, 等. 航空结构分析CAE软件发展现状与未来挑战[J]. 航空学报, 2022, 43(6): 28-51.
|
| [12] |
刘俊杰, 夏劲松, 金言, 等. 冰-水耦合作用下船舶与浮冰碰撞动响应数值仿真研究[J]. 船舶力学, 2020, 24(5): 651-661.
|
| [13] |
陈学军, 杨学文, 张永珍. 地雷爆炸作用下装甲车辆底部防护结构优化仿真研究[J]. 兵工学报, 2014, 35(S2): 353-357.
|
| [14] |
李君, 邱君降, 邵明堃, 等. 我国两化融合关键技术、产品及产业生态国际竞争力现状、制约因素及提升对策研究[J]. 计算机集成制造系统, 2019, 25(9): 2334-2343.
|
| [15] |
邵珠峰, 赵云, 王晨, 等. 新时期我国工业软件产业发展路径研究[J]. 中国工程科学, 2022, 24(2): 86-95.
doi: 10.15302/J-SSCAE-2022.02.010
|
| [16] |
李双宝, 张博. 航空轮胎着陆冲击动力学仿真与安全分析[J]. 中国民航大学学报, 2024, 42(2): 58-64.
|
| [17] |
SINGHAL K, AZIZI S, TU T, et al. Large language models encode clinical knowledge[J]. Nature, 2023, 620(7972): 172-180.
|
| [18] |
裴炳森, 李欣, 蒋章涛, 等. 基于大语言模型的司法文本摘要生成与评价技术研究[J]. 数据与计算发展前沿(中英文), 2024, 6(6): 62-73.
|
| [19] |
吕仲涛. AI大模型在金融业的应用与展望——以中国工商银行为例[J]. 新金融, 2024(10): 7-9.
|
| [20] |
YU J, WANG X, TU S, et al. KoLA: Carefully Benchmarking World Knowledge of Large Language Models[C]// The Twelfth International Conference on Learning Representations. 2023.
|
| [21] |
HUANG Y, BAI Y, ZHU Z, et al. C-EVAL: a multi-level multi-discipline Chinese evaluation suite for foundation models[C]// Proceedings of the 37th International Conference on Neural Information Processing Systems. Red Hook, NY, USA: Curran Associates Inc., 2024: 62991-63010.
|
| [22] |
ZHONG W, CUI R, GUO Y, et al. AGIEval: A Human-Centric Benchmark for Evaluating Foundation Models[C]// Duh K, Gomez H, Bethard S. Findings of the Association for Computational Linguistics:NAACL 2024. Mexico City, Mexico: Association for Computational Linguistics, 2024: 2299-2314.
|
| [23] |
WANG X, HU Z, LU P, et al. SCIBENCH: evaluating college-level scientific problem-solving abilities of large language models[C]// Proceedings of the 41st International Conference on Machine Learning:Vol. 235. Vienna, Austria: JMLR.org, 2024: 50622-50649.
|
| [24] |
ZHU J, LI J, WEN Y, et al. Benchmarking Large Language Models on CFLUE - A Chinese Financial Language Understanding Evaluation Dataset[C]// Ku L W, Martins A, Srikumar V. Findings of the Association for Computational Linguistics:ACL 2024. Bangkok, Thailand: Association for Computational Linguistics, 2024: 5673-5693.
|
| [25] |
LIU M, HU W, DING J, et al. MedBench: A Comprehensive, Standardized, and Reliable Benchmarking System for Evaluating Chinese Medical Large Language Models[J/OL]. Big Data Mining and Analytics, 2024, 7(4): 1116-1128. DOI:10.26599/BDMA.2024.9020044.
|
| [26] |
KRATHWOHL D R. A Revision of Bloom’s Taxonomy: An Overview[J]. Theory Into Practice, 2002, 41(4): 212-218.
|
| [27] |
孙训方, 方孝淑, 关来泰. 材料力学(第6版)(I)[M]. 北京: 高等教育出版社, 2019:52-355.
|
| [28] |
哈尔滨工业大学理论力学教研室. 理论力学(第9版)(I)[M]. 北京: 高等教育出版社, 2023: 21-387.
|
| [29] |
OPENAI, ACHIAM J, ADLER S, et al. GPT-4 Technical Report[A/OL]. arXiv, 2024. DOI:10.48550/arXiv.2303.08774.
|
| [30] |
GLM T, ZENG A, XU B, et al. ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools[A/OL]. arXiv, 2024. DOI:10.48550/arXiv.2406.12793.
|
| [31] |
ZHENG C, ZHOU H, MENG F, et al. Large Language Models Are Not Robust Multiple Choice Selectors[A/OL]. arXiv, 2024 DOI:10.48550/arXiv.2309.03882.
|
| [32] |
SUN Y, LIU C, ZHOU K, et al. Parrot: Enhancing Multi-Turn Instruction Following for Large Language Models[C]// Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1:Long Papers), 2024: 9729-9750.
|
| [33] |
田萱, 吴志超. 基于信息检索的知识库问答综述[J]. 计算机研究与发展, 2025, 62(2): 314-335.
|
| [34] |
SCHMIRLER R, HEINZINGER M, ROST B. Fine-tuning protein language models boosts predictions across diverse tasks[J]. Nature Communications, 2024, 15(1): 7407.
doi: 10.1038/s41467-024-51844-2
pmid: 39198457
|
 )
)