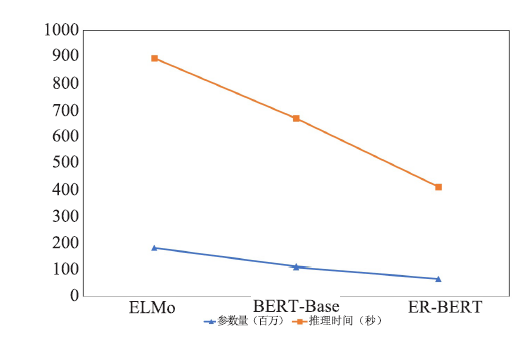
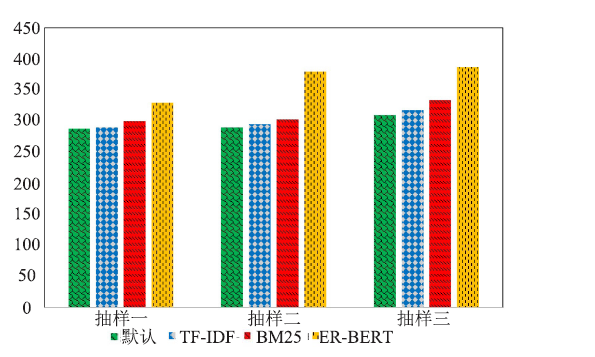
| [1] |
牟智佳, 俞显, 武法提. 国际教育数据挖掘研究现状的可视化分析:热点与趋势[J]. 电化教育研究, 2017, 38(4):108-114.
|
| [2] |
漆桂林, 高桓, 吴天星. 知识图谱研究进展[J]. 情报工程, 2017, 3(1):4-25.
|
| [3] |
李涛, 王次臣, 李华康. 知识图谱的发展与构建[J]. 南京理工大学学报, 2017, 41(1):22-34.
|
| [4] |
魏涛, 孟方园, 袁平, 等. 开源搜索引擎Elasticsearch和Solr对比和分析[J]. 现代计算机(专业版), 2018(06):60-63.
|
| [5] |
刘琼茹. 基于Lucene的搜索排序算法研究与实现[J]. 无线互联科技, 2017(4):143-146.
|
| [6] |
张金鹏. 基于语义的文本相似度算法研究及应用[D]. 重庆理工大学, 2014.
|
| [7] |
Elkahky A M, Song Y, He X. A Multi-View Deep Learn-ing Approach for Cross Domain User Modeling in Rec-ommendation Systems[C]// the 24th International Confer-ence. International World Wide Web Conferences Steer-ing Committee, 2015: 278-288.
|
| [8] |
Guo J, Fan Y, Ai Q, et al. A deep relevance matching model for ad – hoc retrieval[C]// Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, 2016: 55-64.
|
| [9] |
Pang L, Lan Y, Guo J, et al. Text matching as image recognition[J]. arXiv preprint arXiv: 1602. 06359, 2016.
|
| [10] |
BERT: Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
|
| [11] |
方子卿, 陈一飞. 基于BERT的短文本相似度判别模型[J]. 电脑知识与技术, 2021, 17(5):14-18.
|
| [12] |
word2vec: Mikolov T, Sutskever I, Chen K, et al. Dist-ributed representations of words and phrases and their compositionality[C]// Advances in neural information processing systems, 2013: 3111-3119.
|
| [13] |
ELMO: Peters M, Neumann M, Iyyer M, et al. Deep Contextualized Word Representations[C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), 2018: 2227-2237.
|
| [14] |
transformer: Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]// Advances in neural informa-tion processing systems, 2017: 5998-6008.
|
| [15] |
Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training[EB/OL]. , 2018.
|
| [16] |
Huang Y, Zhang Y, Elachqar O, et al. INSET: Sentence Infilling with INter-SEntential Transformer[C]// Procee-dings of the 58th Annual Meeting of the Association for Computational Linguistics, 2020: 2502-2515.
|
| [17] |
Yao C, D Cai, Bu J, et al. Pre-training the deep generative models with adaptive hyperparameter optimization[J]. Neurocomputing, 2017, 247:144-155.
doi: 10.1016/j.neucom.2017.03.058
|
| [18] |
Hinton G, Vinyals O, Dean J. Distilling the Knowledge in a Neural Network[J]. Computer Science, 2015, 14(7):38-39.
|
| [19] |
DistilBert: Sanh V, Debut L, Chaumond J, et al. Dis-tilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter[J]. arXiv preprint arXiv:1910.01108, 2019.
|
| [20] |
Jiao X, Y Yin, Shang L, et al. TinyBERT: Distilling BERT for Natural Language Understanding[C]// Findings of the Association for Computational Linguistics: EMNLP 2020, 2020.
|
| [21] |
Liu X, Chen Q, Deng C, et al. Lcqmc: A large-scale chinese question matching corpus[C]// Proceedings of the 27th International Conference on Computational Lingui-stics, 2018: 1952-1962.
|
 ),苏晨阳(
),苏晨阳(