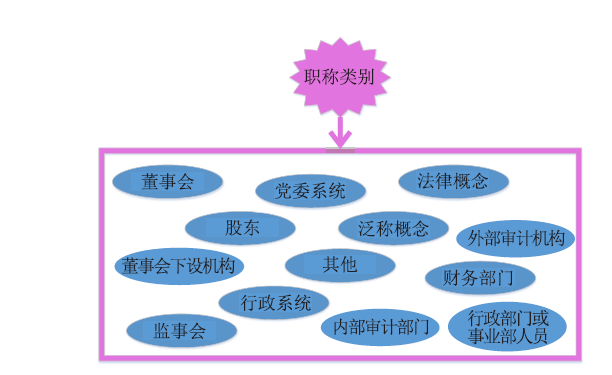
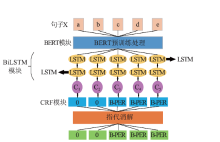
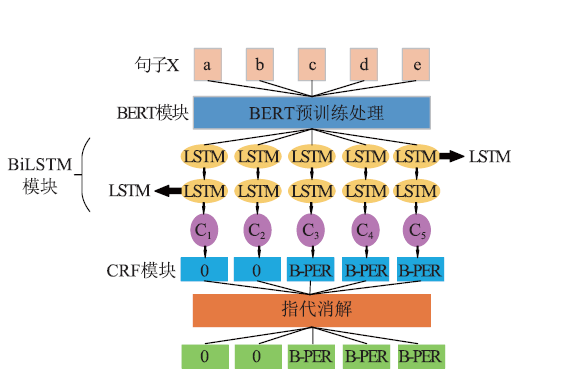
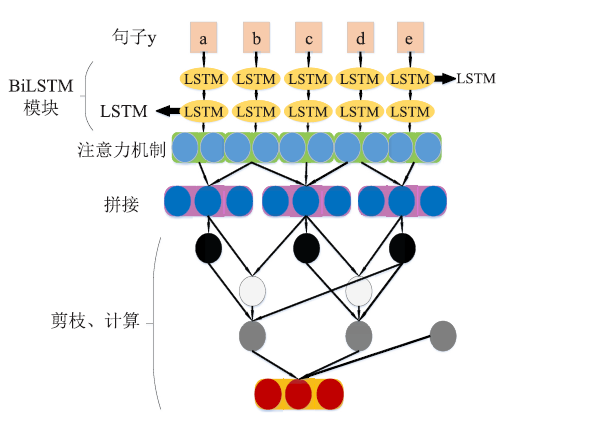
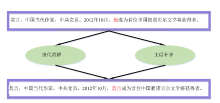
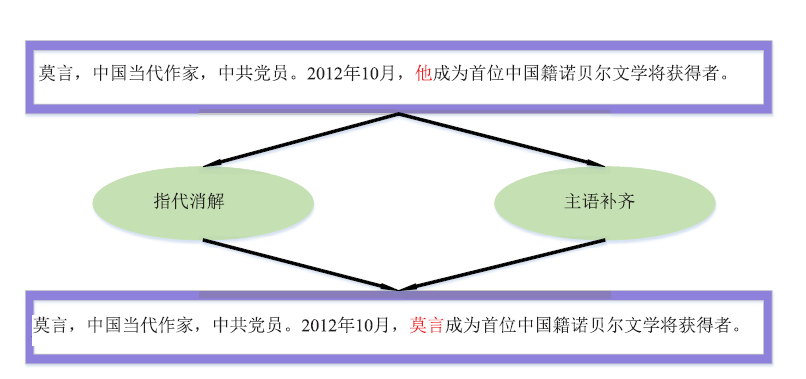
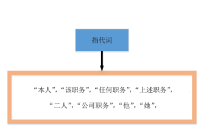
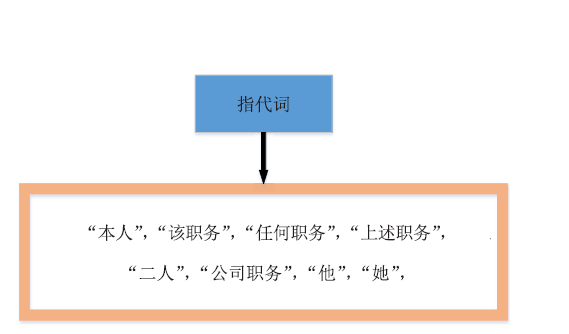
| [1] |
徐新峰. 基于循环神经网络的中文人名识别的研究[D]. 大连理工大学, 2016.
|
| [2] |
宋希良, 韩先培, 孙乐. 面向新类型人名识别的数据增强方法[J]. 中文信息学报, 2019, 33(06):72-79.
|
| [3] |
王双双. 面向科技文献作者检索的人名消歧方法研究[D]. 上海师范大学, 2021.
|
| [4] |
线岩团, 高凡雅, 相艳, 余正涛, 王剑. 融合多策略数据增强的低资源依存句法分析方法[J]. 计算机科学, 2022, 49(01):73-79.
|
| [5] |
陈鸿彬. 汉语句法分析中数据增强方法研究[D]. 北京交通大学, 2021.
|
| [6] |
李恒. 基于深度学习的中文指代消解关键技术研究[D]. 华中科技大学, 2020.
|
| [7] |
付健. 端到端实体指代消解及相关技术研究[D]. 苏州大学, 2019.
|
| [8] |
程志刚. 基于规则和条件随机场的中文命名实体识别方法研究[D]. 华中师范大学, 2015.
|
| [9] |
周凡坤. 面向领域的文本信息抽取方法研究[D]. 南京邮电大学, 2014.
|
| [10] |
韩普, 姜杰. HMM在自然语言处理领域中的应用研究[J]. 计算机技术与发展, 2010, 20(02):245-248+252.
|
| [11] |
刘新亮, 张梦琪, 谷情, 任延昭, 何东彬, 高万林. 基于BERT-CRF模型的生鲜蛋供应链命名实体识别[J]. 农业机械学报, 2021, 52(S1):519-525.
|
| [12] |
郑洪浩, 宋旭晖, 于洪涛, 李邵梅, 郝一诺. 基于深度学习的中文命名实体识别综述[J]. 信息工程大学学报, 2021, 22(05):590-596.
|
| [13] |
Pingchuan Ma, Bo Jiang, Zhigang Lu, Ning Li, Zhengwei Jiang. Cybersecurity Named Entity Recognition Using Bidirectional Long Short-Term Memory with Conditional Random Fields[J]. Tsinghua Science and Technology, 2021, 26(03): 259-265.
doi: 10.26599/TST.2019.9010033
|
| [14] |
邵曦, 陈明. 结合Bi-LSTM和注意力模型的问答系统研究[J]. 计算机应用与软件, 2020, 37(10):52-56.
|
| [15] |
张晓, 李业刚, 王栋, 史树敏. 基于迁移学习的社交评论命名实体识别[J]. 计算机应用与软件, 2022, 39(01):143-150.
|
| [16] |
刘卓凡, 郑庆庆, 李俊, 廖思翀, 冯宜晖. 基于注意力机制和LSTM的文本情感分析[J]. 信息与电脑(理论版), 2021, 33(18):63-65.
|
| [17] |
孙浩, 雒伟群, 赵尔平, 王伟, 崔志远. 基于BERT的Base与Large版的领域命名实体识别研究[J]. 计算机与数字工程, 2021, 49(12):2455-2461.
|
| [18] |
曾青霞, 熊旺平, 杜建强, 聂斌, 郭荣传. 结合自注意力的BiLSTM-CRF的电子病历命名实体识别[J]. 计算机应用与软件, 2021, 38(03):159-162+242.
|
| [19] |
谢腾, 杨俊安, 刘辉. 基于BERT-BiLSTM-CRF模型的中文实体识别[J]. 计算机系统应用, 2020, 29(07):48-55.
|
| [20] |
李恒. 基于深度学习的中文指代消解关键技术研究[D]. 华中科技大学, 2020.DOI: 10.27157/d.cnki.ghzku.2020.001486.
doi: 10.27157/d.cnki.ghzku.2020.001486
|
| [21] |
蒋承知. 基于深度学习的大间隔分类方法研究[D]. 电子科技大学, 2021.DOI: 10.27005/d.cnki.gdzku.2021.002589.
doi: 10.27005/d.cnki.gdzku.2021.002589
|
| [22] |
周炫余, 刘娟, 邵鹏, 罗飞, 刘洋. 基于层次过滤模型的中文指代消解[J]. 吉林大学学报(工学版), 2016, 46(04):1209-1215.
|
| [23] |
禤镇宇, 蒋盛益, 张礼明, 包睿. 基于多特征Bi-LSTM-CRF的影评人名识别研究[J]. 中文信息学报, 2019, 33(03):94-101.
|
 ),玄宇航(
),玄宇航(