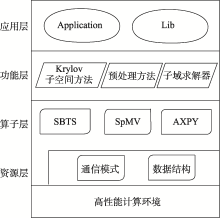
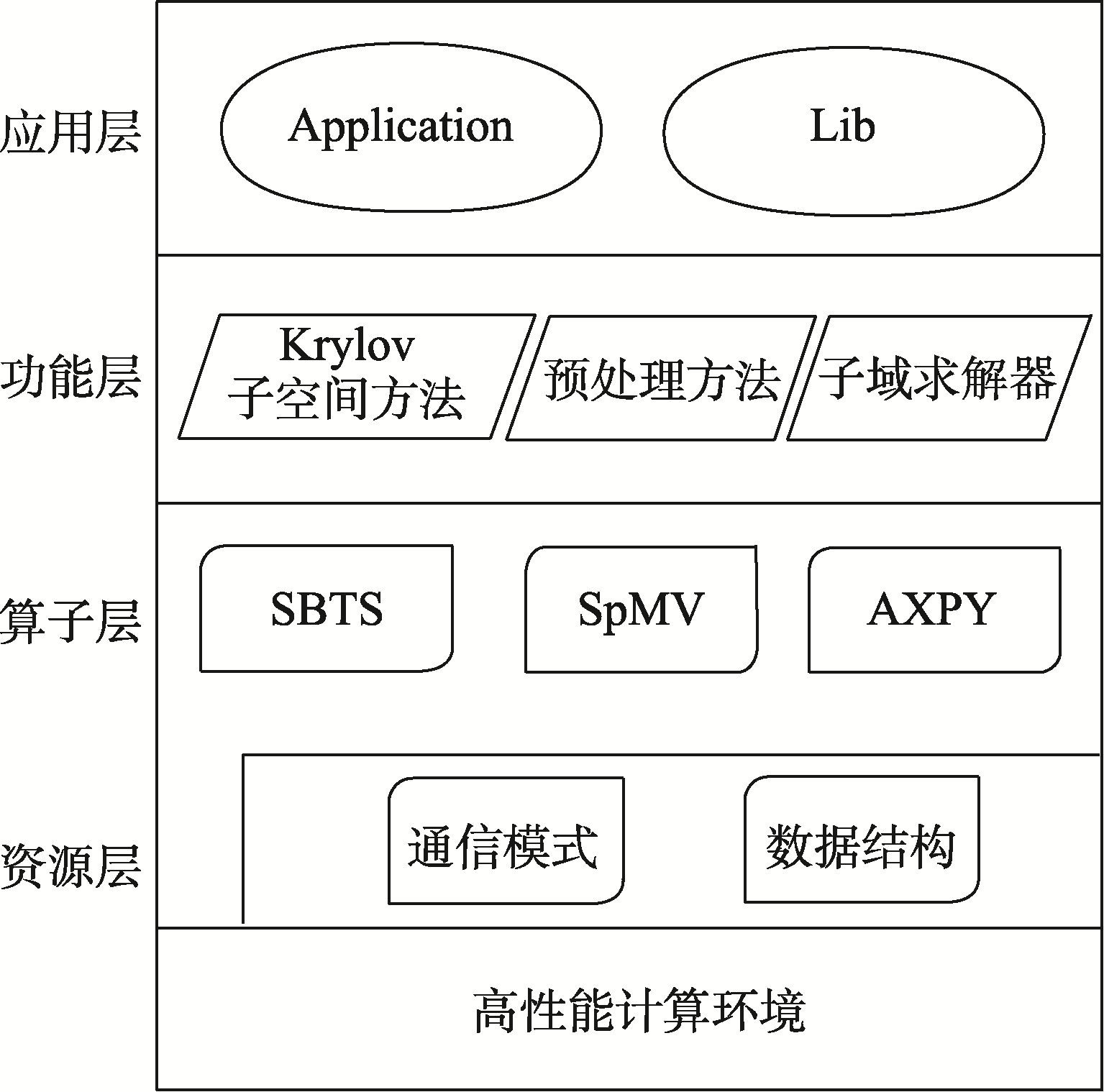
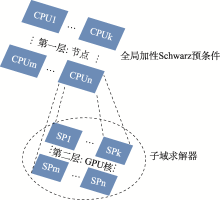
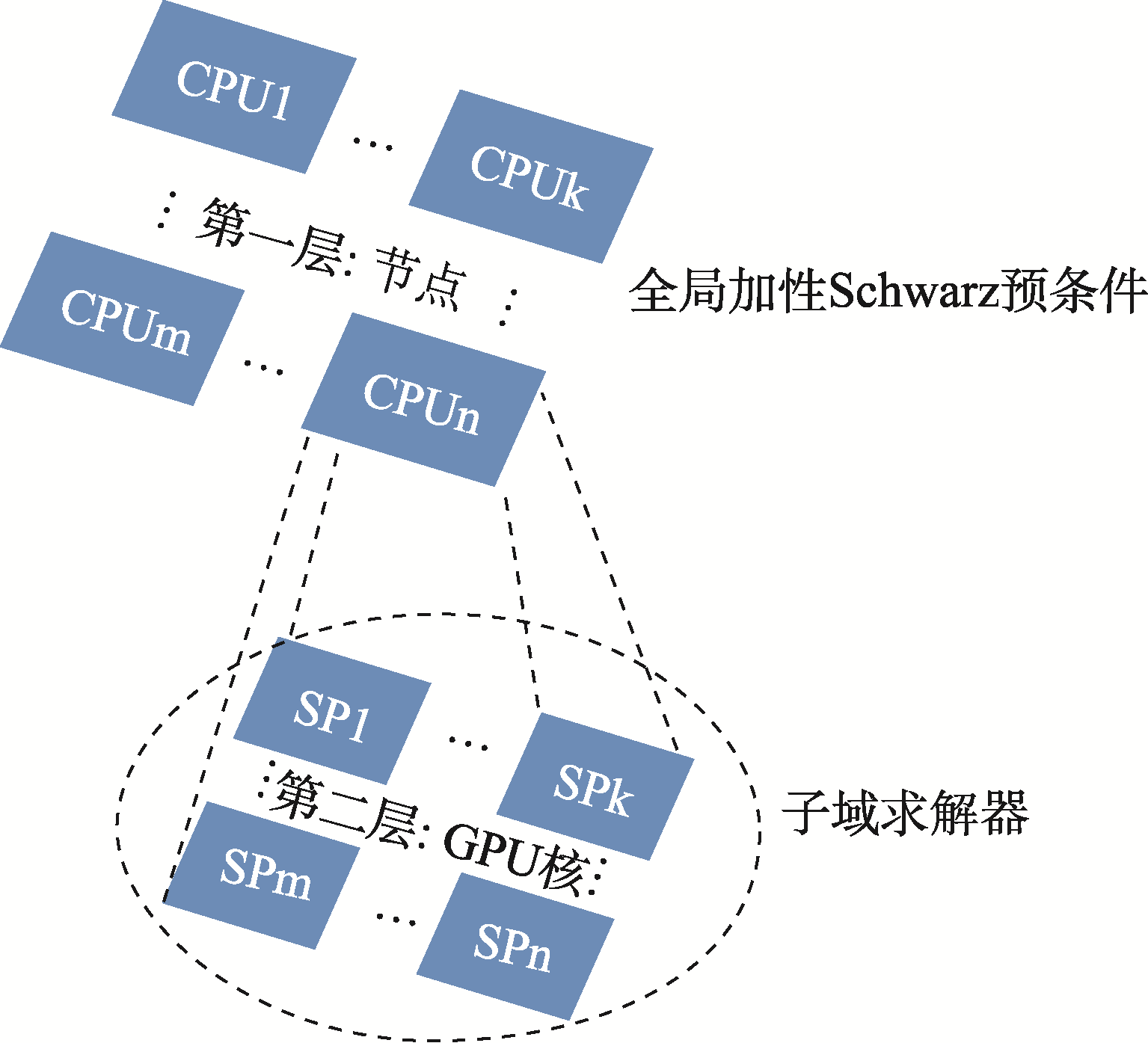
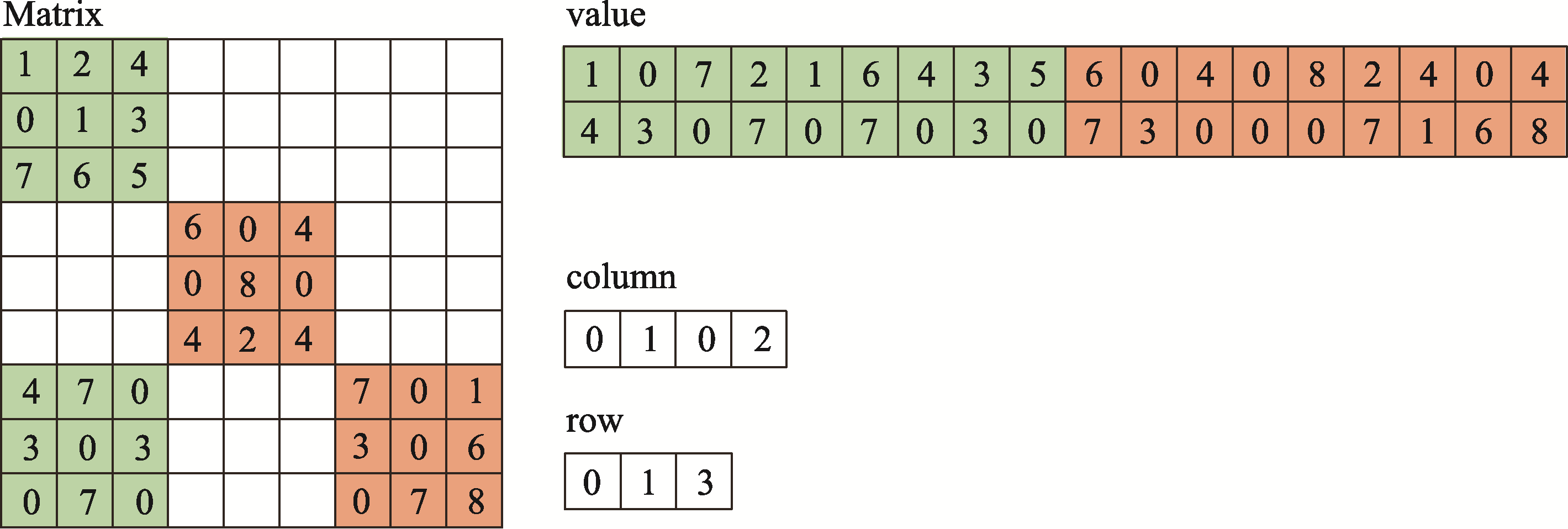
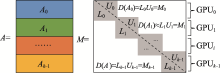
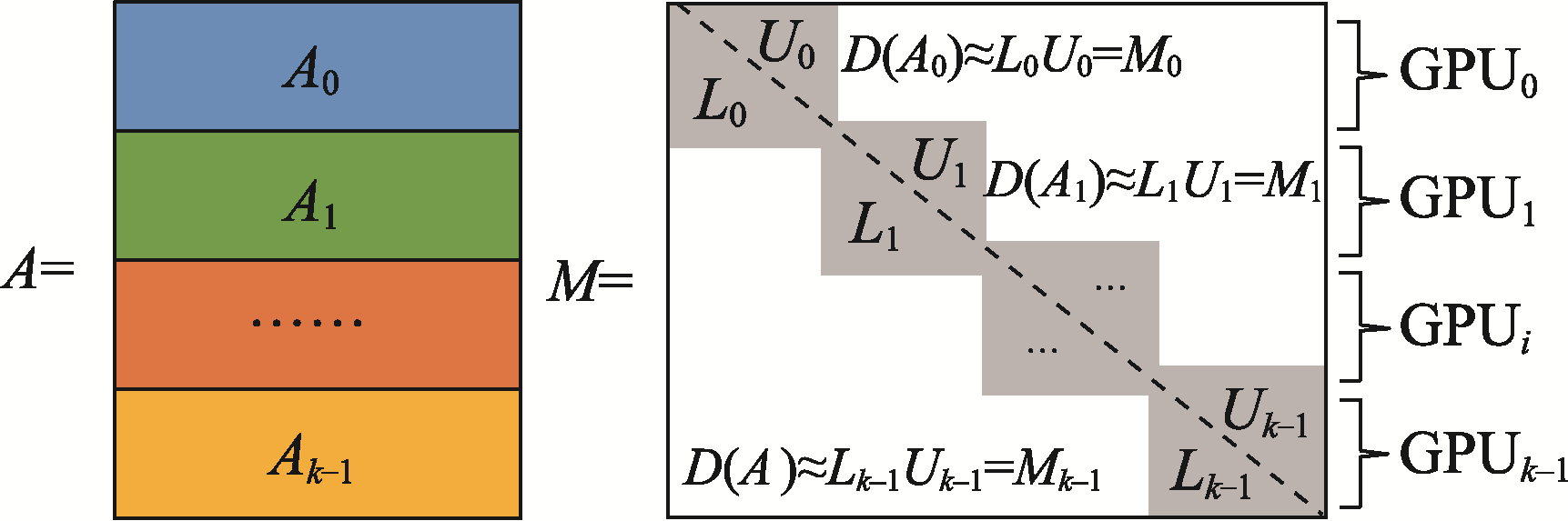
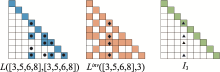
| [1] |
WILLIAM H. Numerical recipes in C++: the art of scientific computing (第2版)[M]. New York: Cambridge University Press, 2002: 234-236.
|
| [2] |
ANDERSON J. Computational Fluid Dynamics[M](第1版). MHS, 1995: 325-340.
|
| [3] |
谷同祥, 安恒斌. 迭代方法和预处理技术[M](第4版). 北京: 科学出版社, 2004: 79-80.
|
| [4] |
刘夏真. 并行流场软件-CCFDv3.0设计及面向国产异构平台的实现[D]. 北京: 中国科学院大学, 2021.
|
| [5] |
LAPACK-Linear Algebra PACKage[EB/OL]. [2020-8-6]. http://www.netlib.org/lapack/.
|
| [6] |
MKL-Intel, Math Kernel Library[EB/OL]. [2020-7-6]. https://www.osc.edu/book/export/.
|
| [7] |
ROCmSoftwarePlatform/rocALUTION[EB/OL]. [2022-4-23]. https://github.com/ROCmSoftwarePlatform/roc-ALUTION.
|
| [8] |
HYPRE: Scalable Linear Solvers and Multigrid Methods[EB/OL]. [2020-2-19]. https://computing.llnl.gov/projects/hypre-scalable-linear-solvers-multigrid-methods.
|
| [9] |
Trilinos Home Page[EB/OL]. [2019-5-23]. https://trilinos.github.io/.
|
| [10] |
PETSc, the Portable Extensible Toolkit for Scientific Computation[EB/OL]. [2021-12-19]. https://petsc.org/release/.
|
| [11] |
汪云婷. 面向分布式异构众核计算系统的稀疏矩阵解法器库[D]. 北京: 中国科学院大学, 2020.
|
| [12] |
PanguLU, an open source software package that uses a block sparse structure to solve linear systems[EB/OL]. [2021-10-19]. https://gitee.com/ssslab/pangulu.
|
| [13] |
MA W P, YUAN W, LIU X Z. A Comparative Study of Block Incomplete Sparse Approximate Inverses Preconditioning on Tesla K20 and V100 GPUs[J]. Algorithms, 2021, 14(7): 204-225.
doi: 10.3390/a14070204
|
| [14] |
WILLIAMS S. Optimization of Sparse Matrix-Vector Multiplication on Emerging Multicore Platforms[J]. Parallel Computing, 2016, 46(1): 22-36.
|
| [15] |
CAI X C, SARKIS M. A restricted additive Schwarz preconditioner for general sparse linear systems[J]. Siam journal on scientific computing, 1999, 21(2): 792-799.
doi: 10.1137/S106482759732678X
|
| [16] |
KIM S W, YUN J H. Block ILU factorization preconditioners for a block-tridiagonal H matrix[J]. Linear Algebra and its Applications, 2000, 37(3): 103-125.
doi: 10.1016/0024-3795(81)90171-3
|
| [17] |
LUO L X, EDWARDS J R, LUO H. A fine-grained block ILU scheme on regular structures for GPGPUs[J]. Computers &Fluids, 2015, 119(2): 149-161.
doi: 10.1016/j.compfluid.2015.07.005
|
| [18] |
SAAD Y, ZHANG J. BILUTM: a domain-based multilevel block ILUT preconditioner for general sparse matrices[J]. Journal on Matrix Analysis and Applications, 1999, 21(1): 279-299.
|
| [19] |
Accelerating Matrix Multiplication with Block Sparse Format and NVIDIA Tensor Cores[EB/OL]. [2022-2-8]. https://developer.nvidia.com/blog/accelerating-matrix-multiplication-with-block-sparse-format-and-nvidia-tensor-cores.
|
| [20] |
cuSPARSE: Basic Linear Algebra for Sparse Matrices on NVIDIA GPUs[EB/OL]. [2022-4-23]. https://developer.nvidia.com/cusparse/.
|
| [21] |
MA W P, CAI X C. Point-block incomplete LU preconditioning with asynchronous iterations on GPU for multiphysics problems[J]. The International Journal of High Performance Cpmputing Applications, 2020 (67): 24-35.
|
| [22] |
LI R P, SAAD Y. GPU-Accelerated Preconditioned Iterative Linear Solvers[J]. The Journal of Supercomputing, 2013, 63(2): 443-466.
doi: 10.1007/s11227-012-0825-3
|
| [23] |
MA W P, HU Y W, YUAN W, et al. GPU Preconditioning for Block Linear Systems Using Block Incomplete Sparse Approximate Inverses[J]. Mathematical Problems in Engineering, 2021, 205(1):75-88.
|
| [24] |
ANZT H, HUCKLE T K, BRÄCKLE. Incomplete Sparse Approximate Inverses for Parallel Preconditioning[J]. Parallel Computing, 2018, 71(1): 22-36.
|
| [25] |
BERTACCINI D, FILIPPONE S. Sparse approximate inverse preconditioning algorithm on GPU[J]. Concurrency and Computation Practice and Experience, 2013, 71(3): 693-715.
|
| [26] |
NAUMOV M. Parallel solution of sparse triangular linear systems in the preconditioned iterative methods on the GPU[J]. NVIDIA Technical Report, 2011, 85(9): 196-216.
|
| [27] |
ANZT H, HEUVELINE V. Mixed Precision Iterative Refinement Methods for Linear Systems: Convergence Analysis Based on Krylov Subspace Methods[J]. Applied Parallel and Scientific Computing, 2010, 255(9): 52-65.
|
 ),马文鹏3,*(
),马文鹏3,*(