数据与计算发展前沿 ›› 2024, Vol. 6 ›› Issue (6): 123-129.
CSTR: 32002.14.jfdc.CN10-1649/TP.2024.06.012
doi: 10.11871/jfdc.issn.2096-742X.2024.06.012
纪鹏1,2,*( ),牛铁1,危婷1,彭亮1
),牛铁1,危婷1,彭亮1
JI Peng1,2,*(),NIU Tie1,WEI Ting1,PENG Liang1
摘要:
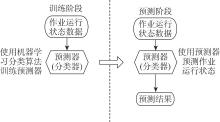
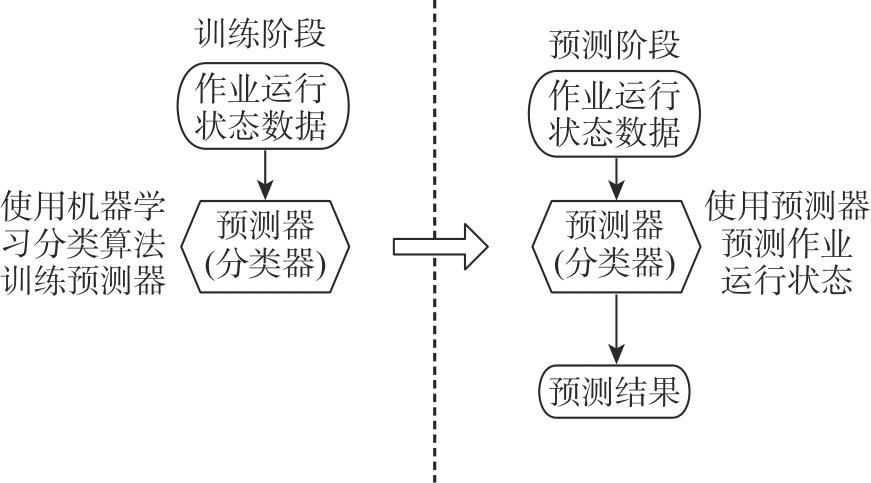
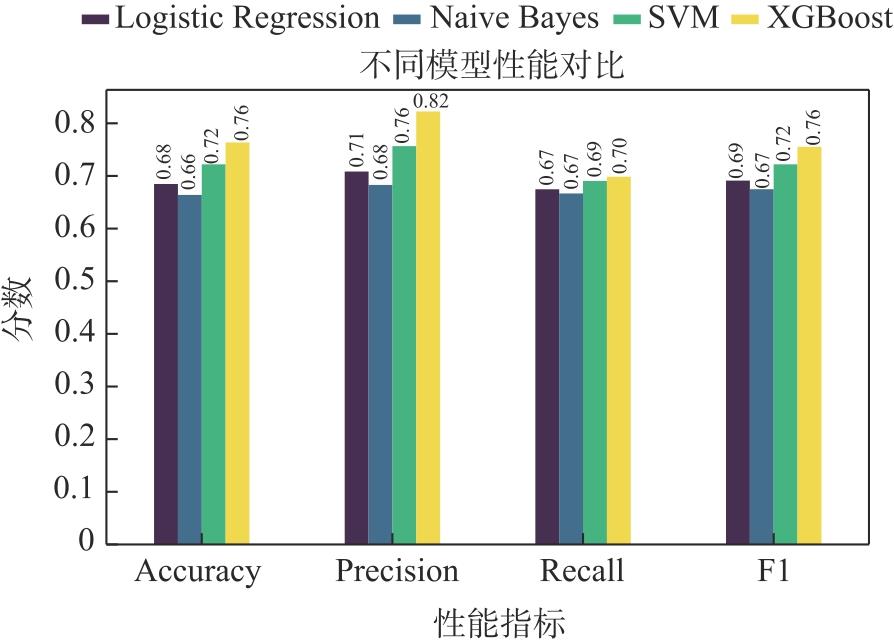
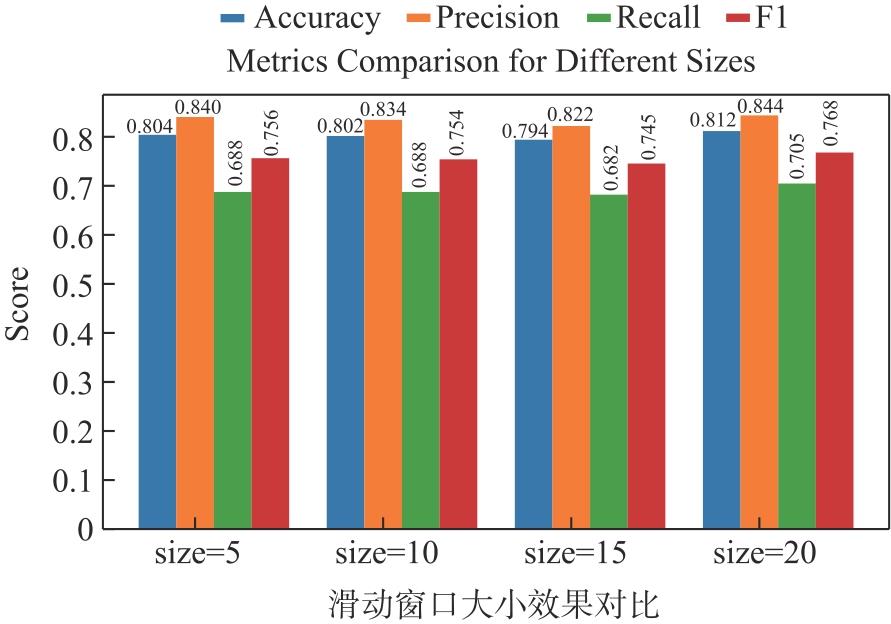
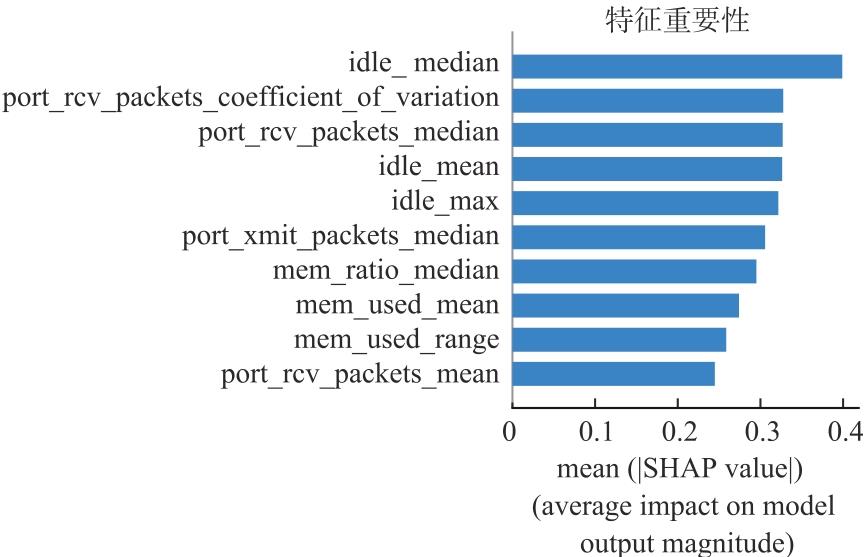
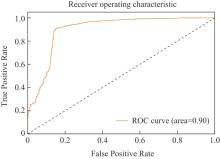
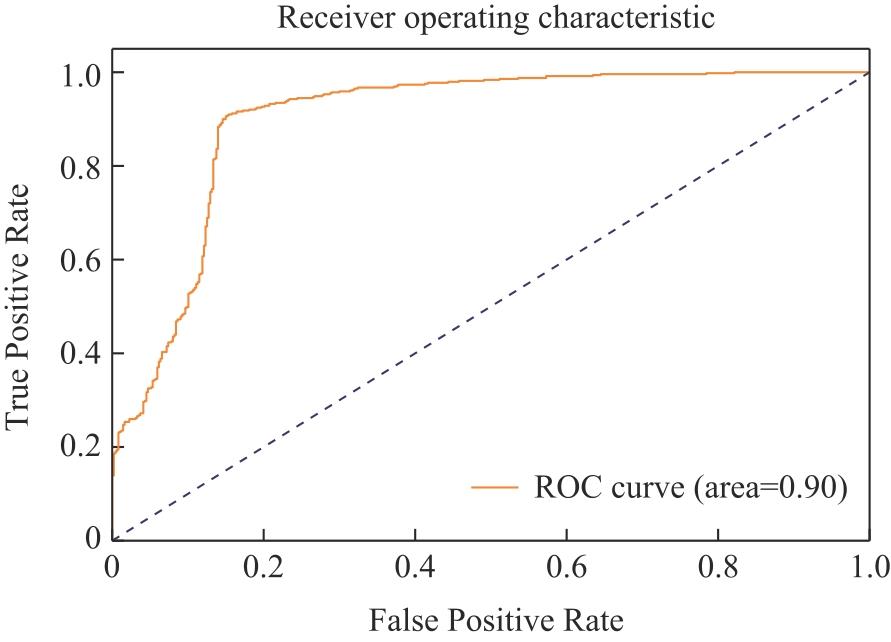
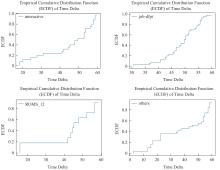
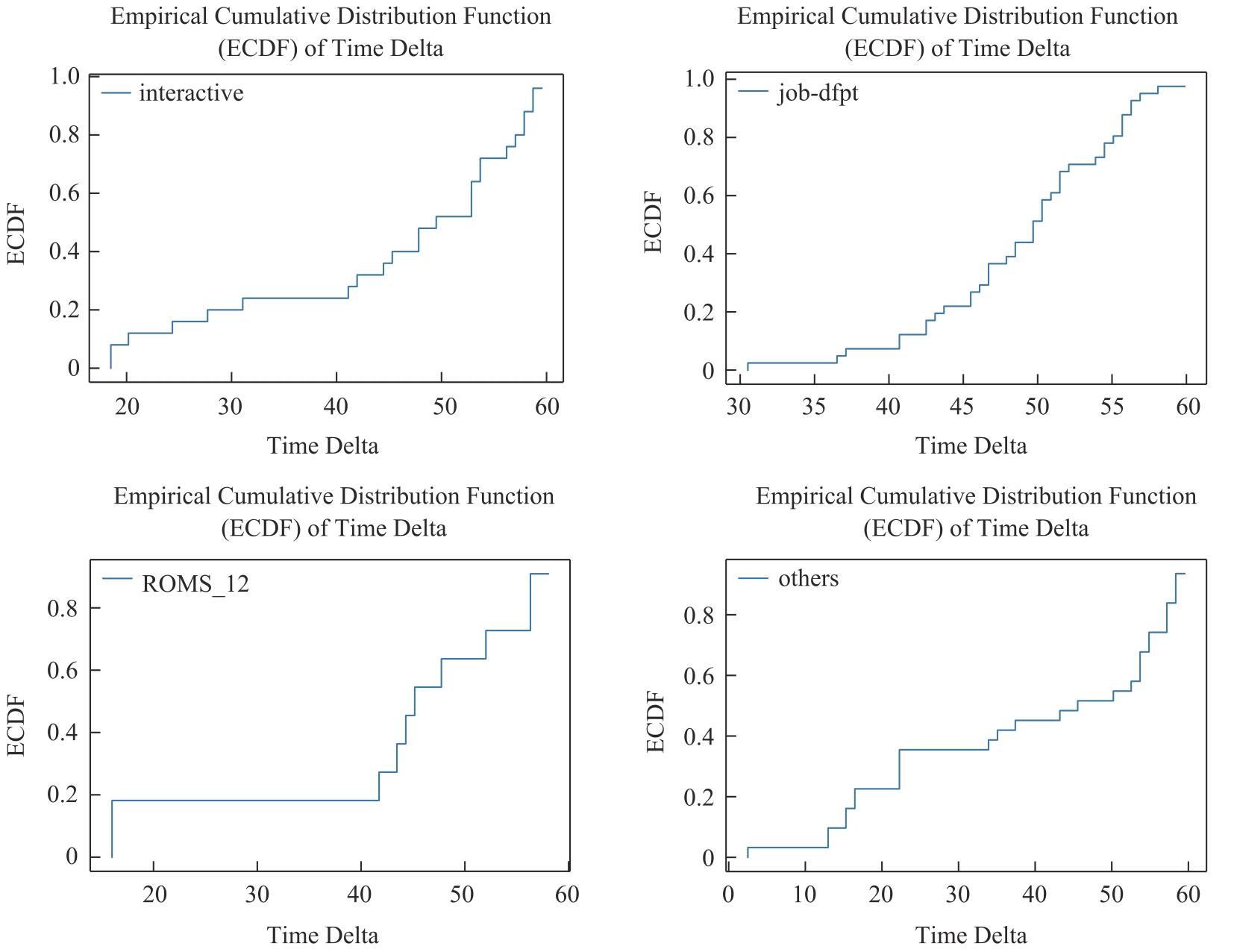
【背景】在高性能计算系统中,作业运行一段时间后可能失败或者异常退出,导致计算资源被占用但未得到满意结果。【目的】对计算作业异常运行状态的检测和预警可以帮助用户、管理人员提前介入干预,减少资源浪费,更早和更好地跟踪分析异常原因。【方法】本文基于大型超级计算集群真实监控数据,从作业运行状态和特征的角度,采用XGBoost算法对各类型作业的运行状态进行异常检测,并对作业是否失败进行预测。【结果】通过对算法的比较和分析,发现XGBoost能够较准确地预测作业失败。【结论】本文研究为高性能计算作业的异常检测和预警拓展了一种新的研究思路,对帮助用户更高效使用昂贵的超级计算资源具有积极意义。