数据与计算发展前沿 ›› 2024, Vol. 6 ›› Issue (5): 111-125.
CSTR: 32002.14.jfdc.CN10-1649/TP.2024.05.011
doi: 10.11871/jfdc.issn.2096-742X.2024.05.011
郑巳明1,2( ),朱明宇3,袁鑫3,杨小渝1,2,*()
),朱明宇3,袁鑫3,杨小渝1,2,*()
收稿日期:2023-04-03
出版日期:2024-10-20
发布日期:2024-10-21
通讯作者:
* 杨小渝(E-mail: 作者简介:郑巳明,博士生,就读于中国科学院计算机网络信息中心,专业方向为计算机应用技术,目前主要研究方向为深度学习、机器学习、计算成像,高光谱成像。
ZHENG Siming1,2(),ZHU Mingyu3,YUAN Xin3,YANG Xiaoyu1,2,*()
Received:2023-04-03
Online:2024-10-20
Published:2024-10-21
摘要:
【目的】为视频单曝光压缩成像(Snapshot Compressive Imaging,SCI)设计一种对原始压缩比例、调制掩模和测量分辨率等超参数具有较高鲁棒性的统一模型。【方法】本文基于弹性权重巩固(EWC)对所提出的模型进行训练,该模型具有结合了Transformer和卷积神经网络两种网络结构的特殊设计,在此基础上本文在初始化阶段引入广义交替投影进一步增加了模型对于不同掩码的鲁棒性。【结果】广泛的实验结果表明,本文提出的统一模型可以很好地适应不同的压缩比、调制掩膜和测量分辨率,同时实现了最先进的结果。实验结果在PSNR、SSIM方面表现优于之前的SOTA算法,其中平均PSNR涨幅超过5 dB。【局限】尽管本文提出的模型在适应性和平均PSNR指标上优于之前的SOTA算法,但引入了EWC的模型在特定单一任务上的结果可能不会优于针对该特定任务训练的模型。【结论】通过引入广义交替投影和EWC以及对于网络结构的特殊设计,本文提出的具有高度适应性的模型为解决其他复杂场景下的压缩感知重建任务提供了新的思路和方法。
郑巳明, 朱明宇, 袁鑫, 杨小渝. 基于弹性权重巩固的视频单曝光压缩成像算法研究[J]. 数据与计算发展前沿, 2024, 6(5): 111-125.
ZHENG Siming, ZHU Mingyu, YUAN Xin, YANG Xiaoyu. Video Snapshot Compressive Imaging Based on Elastic Weight Consolidation[J]. Frontiers of Data and Computing, 2024, 6(5): 111-125, https://cstr.cn/32002.14.jfdc.CN10-1649/TP.2024.05.011.
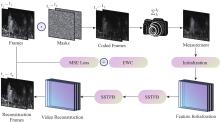
图1
视频单曝光压缩成像(Video Snapshot Compressive Imaging)框架图解"
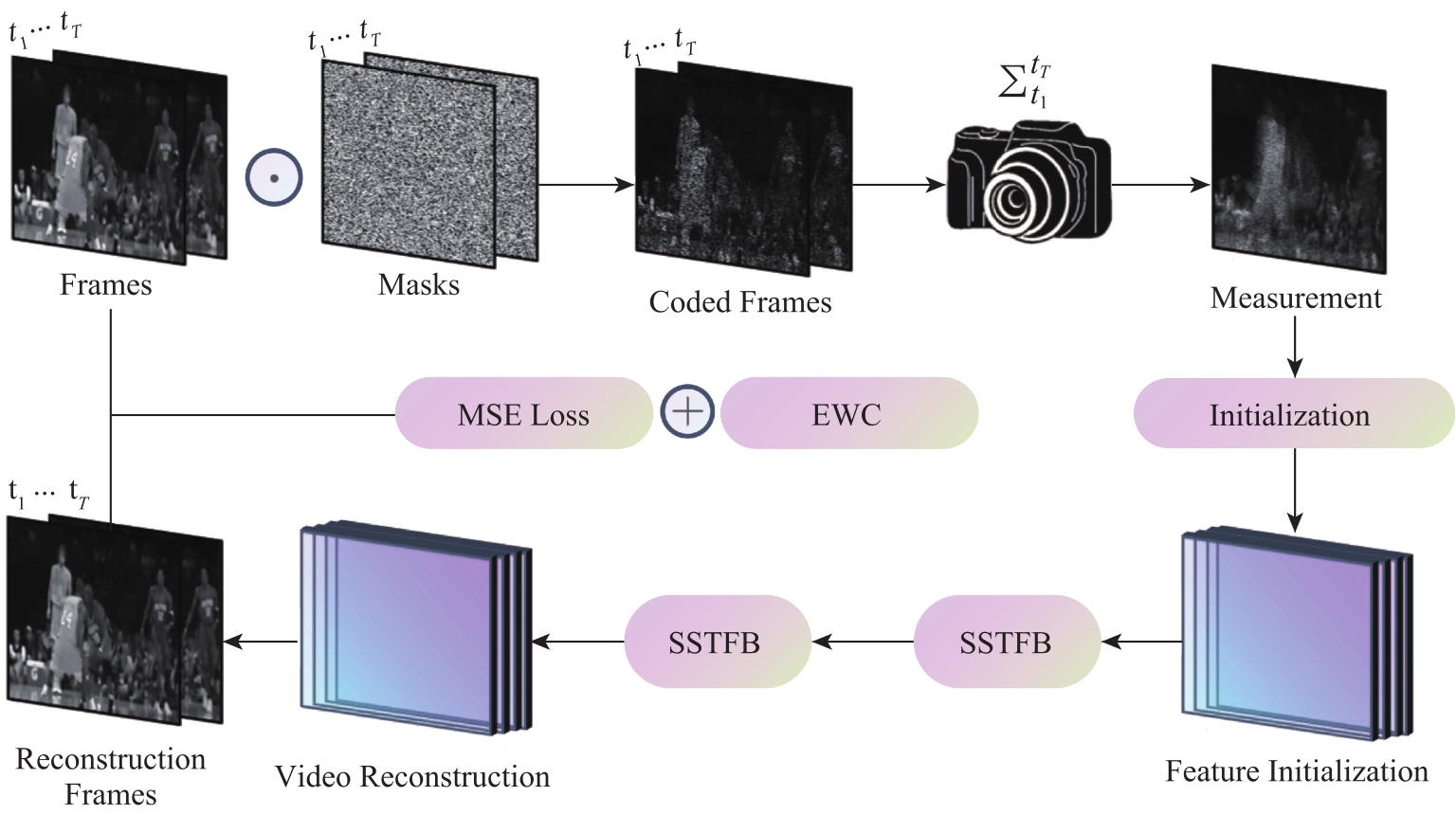
图2
模型基于EWC灵活地适应不同的调制掩码压缩比"
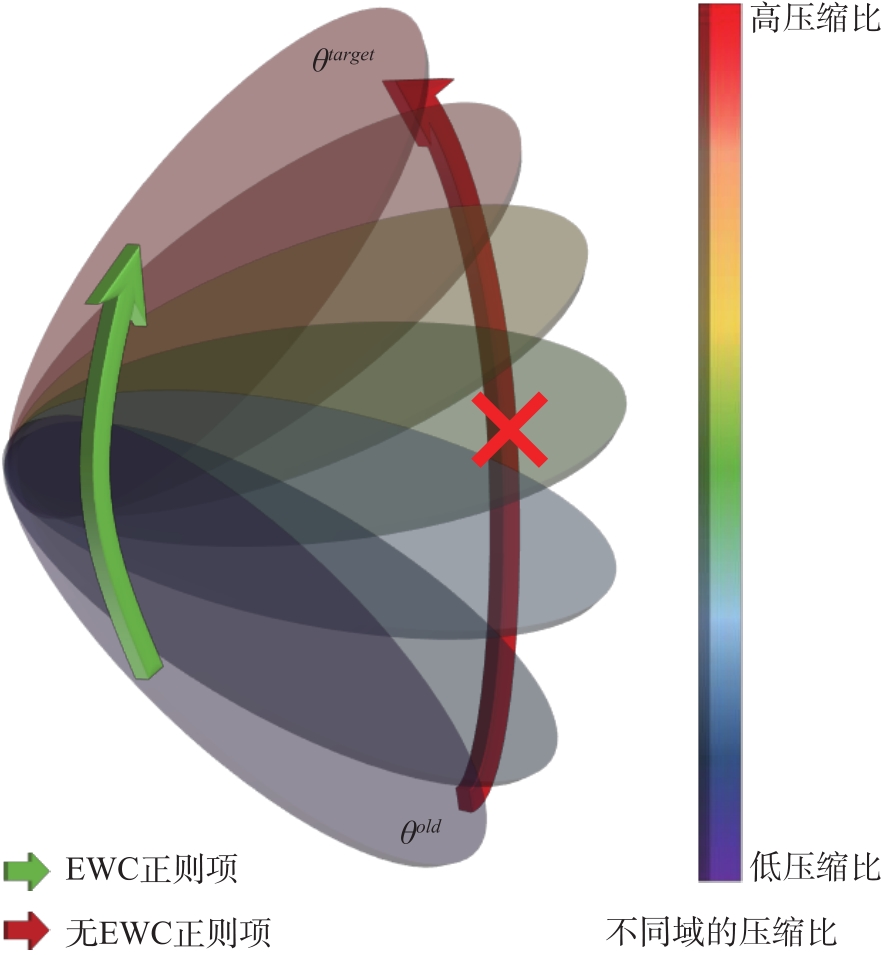
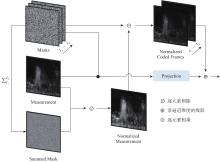
图3
网络输入的初始化"
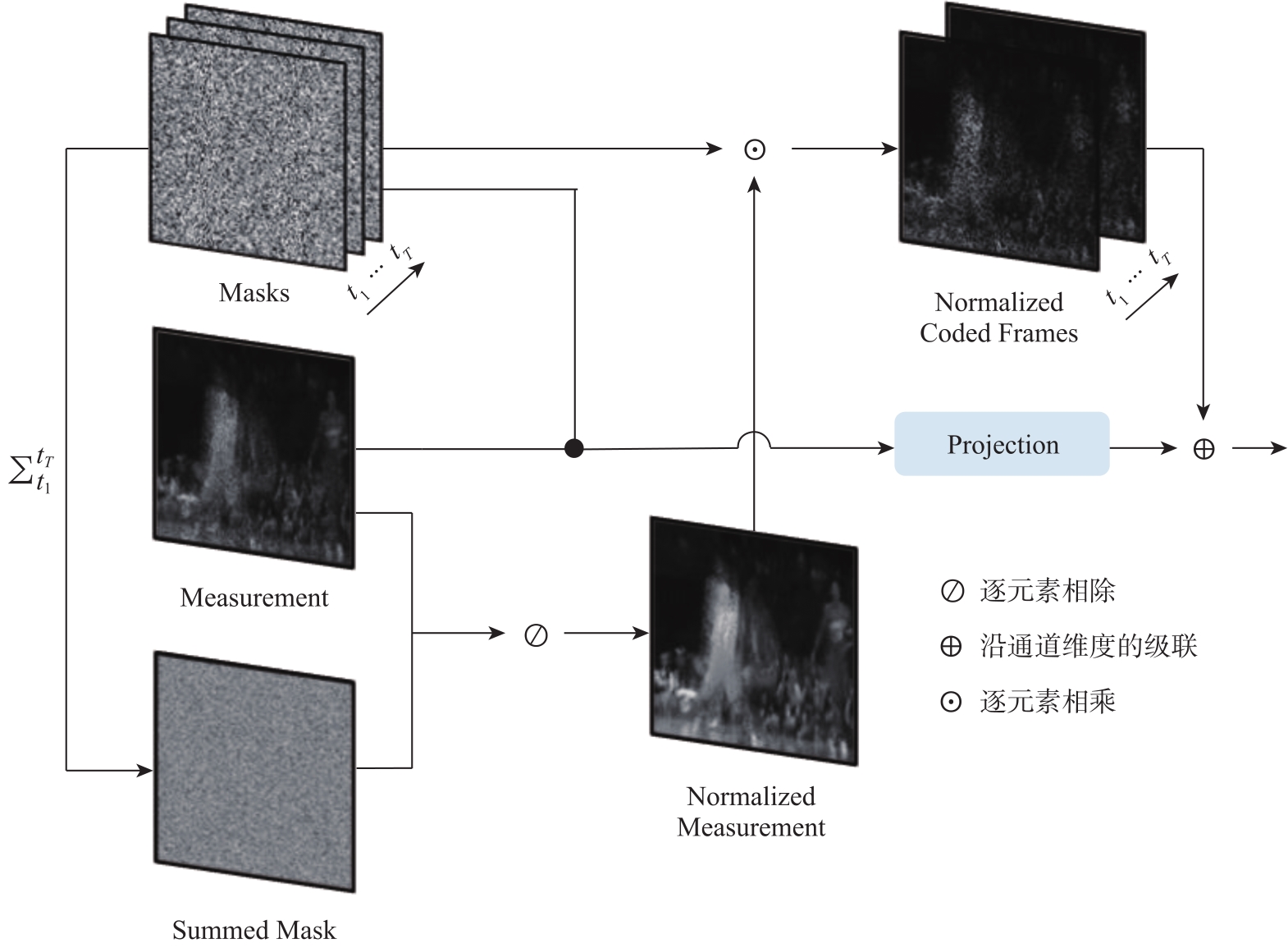
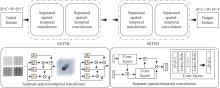
图4
相互独立的时空前向推理模块(SSTFB)的结构示意图"
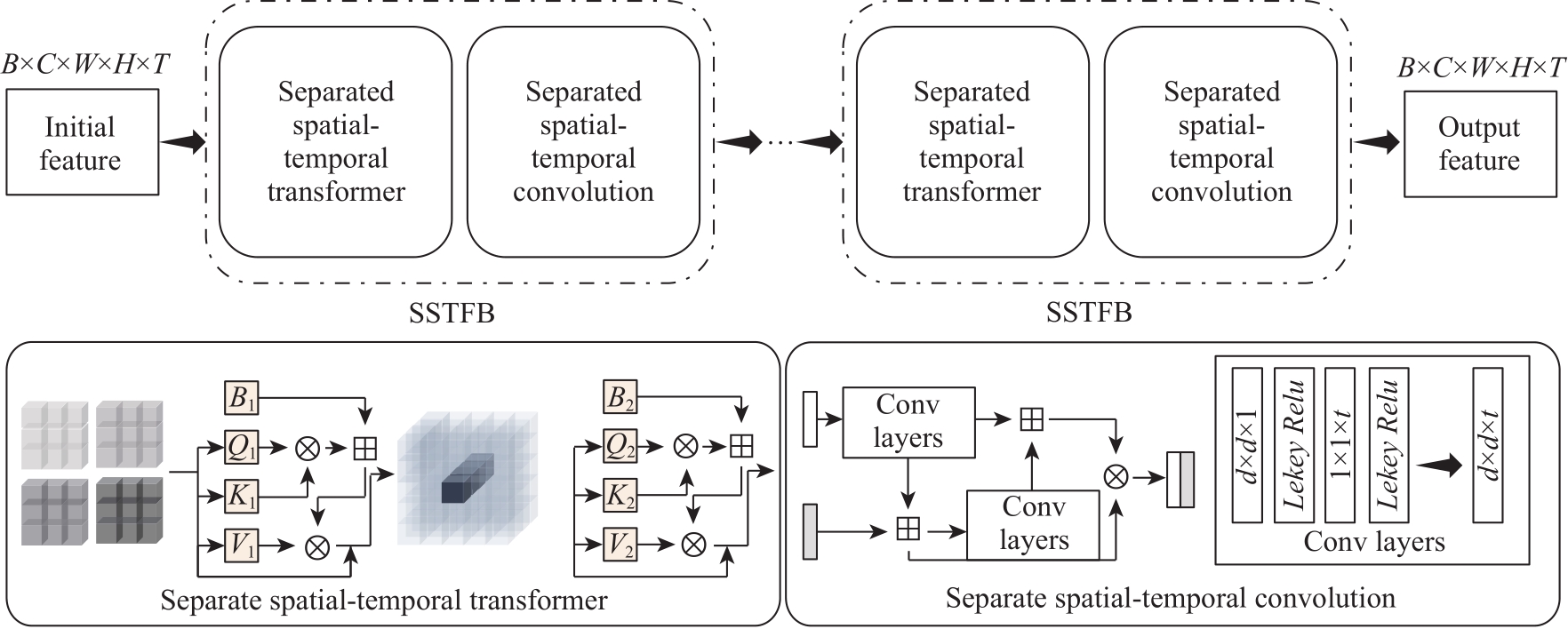
表1
灰度SCI系统不同算法的定量比较"
| 数据集 | Kobe | Traffic | Runner | Drop | Aerial | Crash | Average | 运行时间 |
|---|---|---|---|---|---|---|---|---|
| 评价指标 | PSNR SSIM | PSNR SSIM | PSNR SSIM | PSNR SSIM | PSNR SSIM | PSNR SSIM | PSNR SSIM | 秒(s) |
| GAP-TV[ | 26.45 0.845 | 20.90 0.715 | 28.48 0.899 | 33.81 0.963 | 25.03 0.828 | 24.82 0.838 | 26.58 0.848 | 4.2 |
| E2E-CNN[ | 27.79 0.807 | 24.62 0.840 | 34.12 0.947 | 26.56 0.949 | 27.18 0.869 | 26.43 0.882 | 29.45 0.882 | 0.0312 |
| DeSCI[ | 33.25 0.952 | 28.72 0.925 | 38.76 0.969 | 43.22 0.993 | 25.33 0.860 | 27.04 0.909 | 32.72 0.935 | 6180 |
| PnP-FFDNet[ | 30.47 0.926 | 24.08 0.833 | 32.88 0.938 | 40.87 0.988 | 24.02 0.814 | 24.32 0.836 | 29.44 0.889 | 3.0 |
| PnP-FastDVDNet[ | 32.73 0.946 | 27.95 0.932 | 36.29 0.962 | 41.82 0.989 | 27.98 0.897 | 27.32 0.925 | 32.35 0.942 | 18 |
| BIRNAT[ | 32.71 0.950 | 29.33 0.942 | 38.70 0.976 | 42.28 0.992 | 28.99 0.927 | 27.84 0.927 | 33.31 0.951 | 0.16 |
| GAP-Unet-S12 | 32.09 0.944 | 28.19 0.929 | 38.12 0.975 | 42.02 0.992 | 28.88 0.914 | 27.83 0.931 | 32.86 0.947 | 0.0072 |
| MetaSCI[ | 30.12 0.907 | 26.95 0.888 | 37.02 0.967 | 40.61 0.985 | 28.31 0.904 | 27.33 0.906 | 31.72 0.926 | 0.025 |
| RevSCI[ | 33.72 0.957 | 30.03 0.949 | 39.40 0.977 | 42.93 0.992 | 29.35 0.924 | 28.12 0.937 | 33.92 0.956 | 0.19 |
| DUN-3DUnet[ | 35.00 0.969 | 31.76 0.966 | 40.90 0.983 | 44.46 0.994 | 30.64 0.943 | 29.35 0.955 | 35.32 0.968 | 1.35 |
| ELP-Unfolding[ | 24.41 0.966 | 31.58 0.962 | 41.16 0.986 | 44.99 0.995 | 30.68 0.943 | 29.65 0.960 | 35.41 0.969 | 0.24 |
| Ours | 35.48 0.985 | 31.95 0.979 | 41.17 0.994 | 45.12 0.998 | 31.41 0.968 | 30.95 0.978 | 36.02 0.984 | 1.15 |

图5
不同算法在仿真基准测试集中的部分重建结果"

表2
掩码灵活度:不同算法对SCI系统使用不同掩码情况下的定量比较。选择PSNR (dB)和SSIM作为评估指标"
| 算法 | Ours | DUN-3DUnet | MetaSCI |
|---|---|---|---|
| 评价指标 | PSNR SSIM | PSNR SSIM | PSNR SSIM |
| 训练中使用掩码 | 36.02 0.985 | 35.26 0.968 | 31.72 0.926 |
| 新任务1 | 36.01 0.985 | 31.74 0.937 | 31.71 0.926 |
| 新任务2 | 36.03 0.985 | 31.66 0.937 | 31.68 0.925 |
表3
大尺度数据(压缩比:8):现有算法可应用于大尺度数据的定量比较。最优的结果以粗体显示,次优的结果以下划线显示。选择PSNR和SSIM作为评估指标"
| 数据尺寸 | 算法 | Beauty | Bosphorus | HoneyBee | Jockey | ShakeNDry | Average | 运行时间 |
|---|---|---|---|---|---|---|---|---|
| 评价指标 | PSNR SSIM | PSNR SSIM | PSNR SSIM | PSNR SSIM | PSNR SSIM | PSNR SSIM | PSNR SSIM | 秒(s) |
| 512x512 | GAP-TV[ | 32.13 0.857 | 29.18 0.934 | 31.40 0.887 | 31.01 0.940 | 32.52 0.882 | 31.25 0.900 | 44.67 |
| PnP-FFDNet[ | 30.70 0.855 | 35.36 0.952 | 31.94 0.872 | 34.88 0.955 | 30.72 0.875 | 32.72 0.902 | 14.22 | |
| MetaSCI[ | 35.10 0.901 | 38.37 0.950 | 34.27 0.913 | 36.45 0.962 | 33.16 0.901 | 35.47 0.925 | 0.12 | |
| Ours | 41.32 0.983 | 42.04 0.989 | 43.62 0.991 | 41.57 0.988 | 37.25 0.965 | 41.16 0.983 | 4.67 | |
| 数据尺寸 | 算法 | Beauty | Bosphorus | HoneyBee | Jockey | ShakeNDry | Average | 测试时间 |
| 1024x1024 | GAP-TV[ | 33.59 0.852 | 33.27 0.971 | 33.86 0.913 | 27.49 0.948 | 24.39 0.937 | 30.52 0.924 | 178.11 |
| PnP-FFDNet[ | 32.36 0.857 | 35.25 0.976 | 32.21 0.902 | 31.87 0.965 | 30.77 0.967 | 32.49 0.933 | 52.47 | |
| MetaSCI[ | 35.23 0.929 | 37.15 0.978 | 36.06 0.939 | 33.34 0.973 | 32.68 0.955 | 34.89 0.955 | 0.59 | |
| Ours | 40.38 0.979 | 42.15 0.989 | 39.04 0.978 | 40.09 0.989 | 37.53 0.982 | 39.84 0.983 | 19.93 | |
| 数据尺寸 | 算法 | City | Kids | Lips | RaceNight | RiverBank | Average | 测试时间 |
| 2048x2048 | GAP-TV[ | 21.27 0.902 | 26.05 0.956 | 26.46 0.890 | 26.81 0.875 | 27.74 0.848 | 25.67 0.894 | 764.75 |
| PnP-FFDNet[ | 29.31 0.926 | 30.01 0.966 | 27.99 0.902 | 31.18 0.891 | 30.38 0.888 | 29.77 0.915 | 205.62 | |
| MetaSCI[ | 32.63 0.930 | 32.31 0.965 | 30.90 0.895 | 33.86 0.893 | 32.77 0.902 | 32.49 0.917 | 2.38 | |
| Ours | 40.07 0.982 | 40.15 0.984 | 35.55 0.934 | 36.53 0.956 | 36.80 0.970 | 37.82 0.965 | 79.71 |
表4
不同算法的参数量"
| 算法 | Ours | ELP-Unfolding | DUN-3DUnet |
|---|---|---|---|
| 参数量 | 34.06M | 565.60M | 61.89M |
表5
本文提出的模型在不同压缩比下的量化结果比较。选择PSNR (dB)和SSIM作为评估指标"
| 压缩比 | 8 | 16 | 24 | 32 | 平均值 |
|---|---|---|---|---|---|
| 评价指标 | PSNR SSIM | PSNR SSIM | PSNR SSIM | PSNR SSIM | PSNR SSIM |
| 压缩比为8的模型 | 36.02 0.985 | 23.38 0.847 | 21.30 0.785 | 20.16 0.747 | 25.22 0.841 |
| 引入EWC的模型 | 31.64 0.964 | 30.84 0.955 | 30.81 0.950 | 30.06 0.940 | 30.83 0.952 |
| 压缩比为32的模型 | 30.13 0.955 | 30.52 0.952 | 30.64 0.948 | 30.01 0.939 | 30.32 0.948 |

图 6
本文模型在不同压缩比的条件下的部分重建结果"

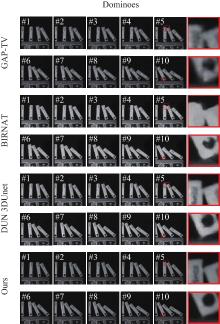
图7
真实数据Dominoes的部分视频重建帧"
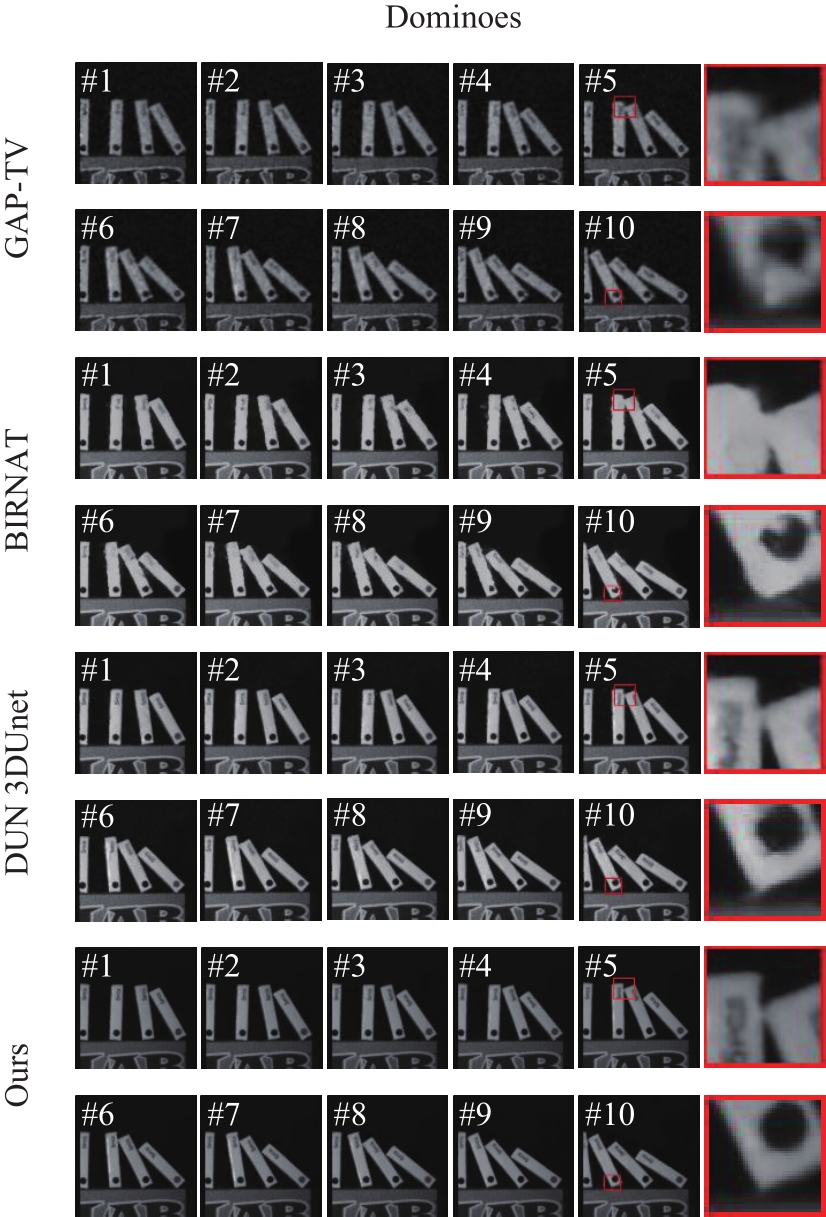

图8
真实数据Water Balloon的部分视频重建帧"

| [1] |
LLULL P, LIAO X, YUAN X, et al. Coded aperture compressive temporal imaging[J]. Optics express, 2013, 21(9): 10526-10545.
doi: 10.1364/OE.21.010526 pmid: 23669910 |
| [2] | YUAN X, LLULL P, LIAO X, et al. Low-cost compressive sensing for color video and depth[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2014: 3318-3325. |
| [3] | HITOMI Y, GU J, GUPTA M, et al. Video from a single coded exposure photograph using a learned over-complete dictionary[C]. Proceedings of the 2011 International Conference on Computer Vision, 2011: 287-294. |
| [4] | REDDY D, VEERARAGHAVAN A, CHELLAPPA R. P2C2: Programmable pixel compressive camera for high speed imaging[C]. Proceedings of the CVPR 2011, 2011: 329-336. |
| [5] | LIU Y, YUAN X, SUO J, et al. Rank minimization for snapshot compressive imaging[J]. IEEE transactions on pattern analysis and machine intelligence, 2018, 41(12): 2990-3006. |
| [6] | CHENG Z, CHEN B, LIU G, et al. Memory-efficient network for large-scale video compressive sensing[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 16246-16255. |
| [7] | YUAN X, BRADY D J, KATSAGGELOS A K. Snapshot compressive imaging: Theory, algorithms, and applications[J]. IEEE Signal Processing Magazine, 2021, 38(2): 65-88. |
| [8] | QIAO M, MENG Z, MA J, et al. Deep learning for video compressive sensing[J]. Apl Photonics, 2020, 5(3): 030801. |
| [9] | WANG Z, ZHANG H, CHENG Z, et al. Metasci: Scalable and adaptive reconstruction for video compressive sensing[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 2083-2092. |
| [10] | CHENG Z, LU R, WANG Z, et al. BIRNAT: Bidirectional recurrent neural networks with adversarial training for video snapshot compressive imaging[C]. Proceedings of the Computer Vision-ECCV 2020, 2020: 258-275. |
| [11] | SUN J, LI H, XU Z. Deep ADMM-Net for compressive sensing MRI[J]. Advances in neural information processing systems, 2016, 29. |
| [12] | YANG Y, SUN J, LI H, et al. ADMM-CSNet: A deep learning approach for image compressive sensing[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 42(3): 521-538. |
| [13] | WU Z, ZHANG J, MOU C. Dense deep unfolding network with 3d-cnn prior for snapshot compressive imaging[C]. Proceedings of the IEEE International Conference on Computer Vision, 2021: 4892-4901. |
| [14] | LI Y, QI M, GULVE R, et al. End-to-end video compressive sensing using anderson-accelerated unrolled networks[C]. Proceedings of the 2020 IEEE International Conference on Computational Photography (ICCP), 2020: 1-12. |
| [15] | ZHANG J, GHANEM B. ISTA-Net: Interpretable optimization-inspired deep network for image compressive sensing[C]. Proceedings of the IEEE conference on computer vision and pattern recognition, 2018: 1828-1837. |
| [16] | YUAN X. Generalized alternating projection based total variation minimization for compressive sensing[C]. Proceedings of the 2016 IEEE International conference on image processing (ICIP), 2016: 2539-2543. |
| [17] | YUAN X, LIU Y, SUO J, et al. Plug-and-play algorithms for large-scale snapshot compressive imaging[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 1447-1457. |
| [18] | YANG J, LIAO X, YUAN X, et al. Compressive sensing by learning a Gaussian mixture model from measurements[J]. IEEE Transactions on Image Processing, 2014, 24(1): 106-119. |
| [19] |
YANG J, YUAN X, LIAO X, et al. Video compressive sensing using Gaussian mixture models[J]. IEEE Transactions on Image Processing, 2014, 23(11): 4863-4878.
doi: 10.1109/TIP.2014.2344294 pmid: 25095253 |
| [20] | SHMELKOV K, SCHMID C, ALAHARI K. Incremental learning of object detectors without catastrophic forgetting[C]. Proceedings of the IEEE international conference on computer vision, 2017: 3400-3409. |
| [21] | CASTRO F M, MARíN-JIMéNEZ M J, GUIL N, et al. End-to-end incremental learning[C]. Proceedings of the European conference on computer vision (ECCV), 2018: 233-248. |
| [22] | RANNEN A, ALJUNDI R, BLASCHKO M B, et al. Encoder based lifelong learning[C]. Proceedings of the IEEE International Conference on Computer Vision, 2017: 1320-1328. |
| [23] | GUO Y, HU W, ZHAO D, et al. Adaptive orthogonal projection for batch and online continual learning[C]. Proceedings of the Proceedings of the AAAI Conference on Artificial Intelligence, 2022: 6783-6791. |
| [24] | ALJUNDI R, CHAKRAVARTY P, TUYTELAARS T. Expert gate: Lifelong learning with a network of experts[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 3366-3375. |
| [25] | ZHAI M, CHEN L, TUNG F, et al. Lifelong gan: Continual learning for conditional image generation[C]. Proceedings of the IEEE/CVF international conference on computer vision, 2019: 2759-2768. |
| [26] | WU C, HERRANZ L, LIU X, et al. Memory replay gans: Learning to generate new categories without forgetting[J]. Advances in Neural Information Processing Systems, 2018, 31. |
| [27] | KIRKPATRICK J, PASCANU R, RABINOWITZ N, et al. Overcoming catastrophic forgetting in neural networks[J]. Proceedings of the national academy of sciences, 2017, 114(13): 3521-3526. |
| [28] | DE LANGE M, ALJUNDI R, MASANA M, et al. A continual learning survey: Defying forgetting in classification tasks[J]. IEEE transactions on pattern analysis and machine intelligence, 2021, 44(7): 3366-3385. |
| [29] | LEE S-W, KIM J-H, JUN J, et al. Overcoming catastrophic forgetting by incremental moment matching[J]. Advances in neural information processing systems, 2017, 30. |
| [30] | LIU X, MASANA M, HERRANZ L, et al. Rotate your networks: Better weight consolidation and less catastrophic forgetting[C]. Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), 2018: 2262-2268. |
| [31] | ZENKE F, POOLE B, GANGULI S. Continual learning through synaptic intelligence[C]. Proceedings of the International conference on machine learning, 2017: 3987-3995. |
| [32] | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]. Proceedings of the IEEE conference on computer vision and pattern recognition, 2016: 770-778. |
| [33] | HUANG G, LIU Z, VAN DER MAATEN L, et al. Densely connected convolutional networks[C]; Proceedings of the IEEE conference on computer vision and pattern recognition, 2017: 4700-4708. |
| [34] | KRIZHEVSKY A, SUTSKEVER I, HINTON G E. Imagenet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84-90. |
| [35] | LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324. |
| [36] | RONNEBERGER O, FISCHER P, BROX T. U-net: Convolutional networks for biomedical image segmentation[C]. Proceedings of the Medical Image Computing and Computer-Assisted Intervention-MICCAI 2015, 2015: 234-241. |
| [37] | JI S, XU W, YANG M, et al. 3D convolutional neural networks for human action recognition[J]. IEEE transactions on pattern analysis and machine intelligence, 2012, 35(1): 221-231. |
| [38] | TAYLOR G W, FERGUS R, LECUN Y, et al. Convolutional learning of spatio-temporal features[C]. Proceedings of the Computer Vision-ECCV 2010, 2010: 140-153. |
| [39] | SHOU Z, WANG D, CHANG S-F. Temporal action localization in untrimmed videos via multi-stage cnns[C]. Proceedings of the IEEE conference on computer vision and pattern recognition, 2016: 1049-1058. |
| [40] | PAN Y, MEI T, YAO T, et al. Jointly modeling embedding and translation to bridge video and language[C]. Proceedings of the IEEE conference on computer vision and pattern recognition, 2016: 4594-4602. |
| [41] | MOLCHANOV P, YANG X, GUPTA S, et al. Online detection and classification of dynamic hand gestures with recurrent 3d convolutional neural network[C]. Proceedings of the IEEE conference on computer vision and pattern recognition, 2016: 4207-4215. |
| [42] | TRAN D, BOURDEV L, FERGUS R, et al. Learning spatiotemporal features with 3d convolutional networks[C]. Proceedings of the IEEE international conference on computer vision, 2015: 4489-4497. |
| [43] | TRAN D, WANG H, TORRESANI L, et al. A closer look at spatiotemporal convolutions for action recognition[C]. Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2018: 6450-6459. |
| [44] | WANG X, GIRSHICK R, GUPTA A, et al. Non-local neural networks[C]. Proceedings of the IEEE conference on computer vision and pattern recognition, 2018: 7794-7803. |
| [45] | YIN M, YAO Z, CAO Y, et al. Disentangled non-local neural networks[C]. Proceedings of the Computer Vision-ECCV 2020, 2020: 191-207. |
| [46] | HAN K, XIAO A, WU E, et al. Transformer in transformer[J]. Advances in Neural Information Processing Systems, 2021, 34: 15908-15919. |
| [47] | TOUVRON H, CORD M, DOUZE M, et al. Training data-efficient image transformers & distillation through attention[C]. Proceedings of the International conference on machine learning, 2021: 10347-10357. |
| [48] | WANG W, XIE E, LI X, et al. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions[C]. Proceedings of the IEEE/CVF international conference on computer vision, 2021: 568-578. |
| [49] | YUAN L, CHEN Y, WANG T, et al. Tokens-to-token vit: Training vision transformers from scratch on imagenet[C]. Proceedings of the IEEE/CVF international conference on computer vision, 2021: 558-567. |
| [50] | LIU Z, LIN Y, CAO Y, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]. Proceedings of the IEEE/CVF international conference on computer vision, 2021: 10012-10022. |
| [51] | LIU Z, NING J, CAO Y, et al. Video swin transformer[C]. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022: 3202-3211. |
| [52] | BERTASIUS G, WANG H, TORRESANI L. Is space-time attention all you need for video understanding?[C]. Proceedings of the ICML, 2021: 4. |
| [53] | YANG C, ZHANG S, YUAN X. Ensemble learning priors driven deep unfolding for scalable video snapshot compressive imaging[C]. Proceedings of the Computer Vision-ECCV 2022, 2022: 600-618. |
| [54] | LIAO X, LI H, CARIN L. Generalized alternating projection for weighted-2,1 minimization with applications to model-based compressive sensing[J]. SIAM Journal on Imaging Sciences, 2014, 7(2): 797-823. |
| [55] | PASZKE A, GROSS S, MASSA F, et al. Pytorch: An imperative style, high-performance deep learning library[J]. Advances in Neural Information Processing Systems, 2019, 32. |
| [56] |
WANG Z, BOVIK A C, SHEIKH H R, et al. Image quality assessment: from error visibility to structural similarity[J]. IEEE Transactions on Image Processing, 2004, 13(4): 600-612.
doi: 10.1109/tip.2003.819861 pmid: 15376593 |
| [1] | 晏直誉, 茹一伟, 孙福鹏, 孙哲南. 基于主动感知机制的视频行为识别方法研究[J]. 数据与计算发展前沿, 2024, 6(5): 66-79. |
| [2] | 宋恒, 胡楠, 耿天宝, 程维国, 张欢. 灌浆密实度冲击弹性波检测信号智能解译方法研究[J]. 数据与计算发展前沿, 2024, 6(4): 163-172. |
| [3] | 郭冠辰, 李军, 蔡程飞, 焦一平, 徐军. 基于因果约束的Transformer医学图像分割方法[J]. 数据与计算发展前沿, 2024, 6(2): 89-100. |
| [4] | 赵泽军, 范振峰, 丁博, 夏时洪. 基于增量学习的深度人脸伪造检测[J]. 数据与计算发展前沿, 2023, 5(6): 42-57. |
| [5] | 陈栋, 李明, 陈淑文. 结合Transformer和多层特征聚合的高光谱图像分类算法[J]. 数据与计算发展前沿, 2023, 5(3): 138-151. |
| [6] | 刘琦玮,李俊,顾蓓蓓,赵泽方. TSAIE:图像增强文本的多模态情感分析模型[J]. 数据与计算发展前沿, 2022, 4(3): 131-140. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||