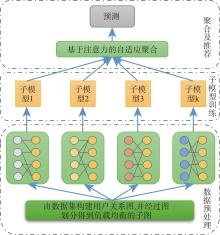
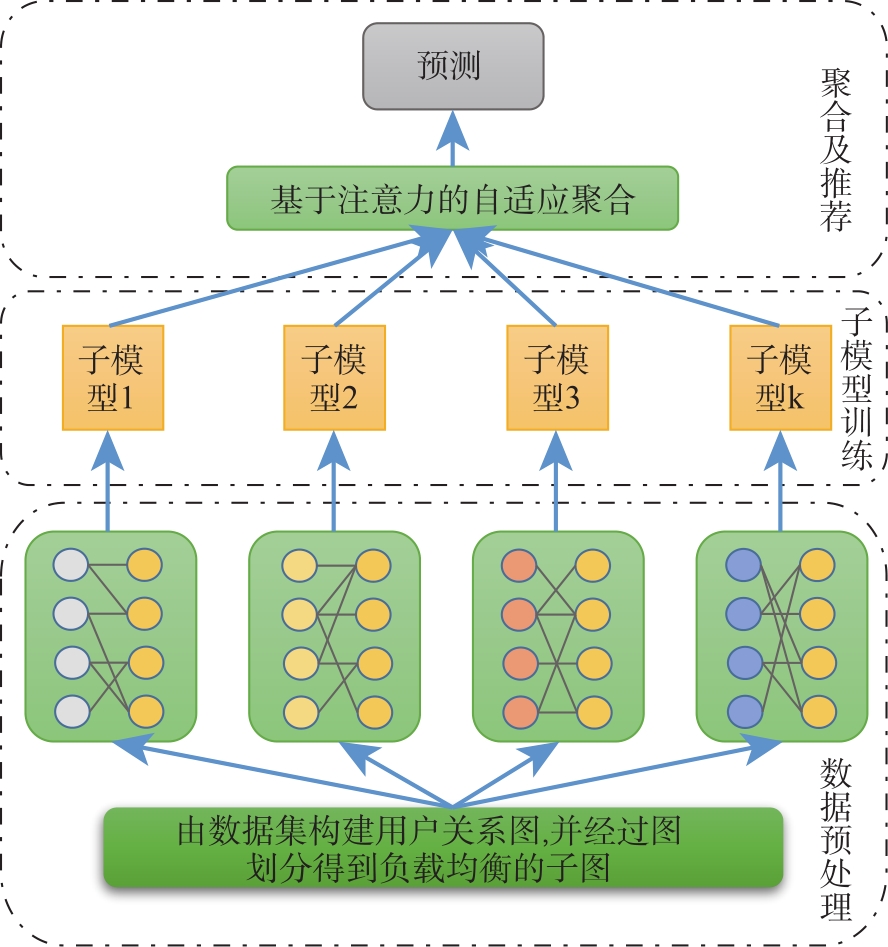
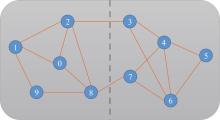
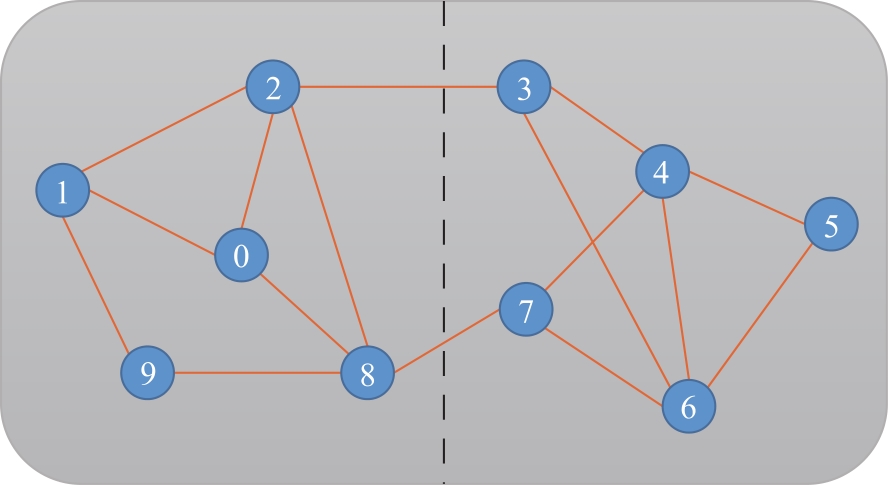
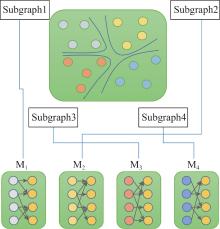
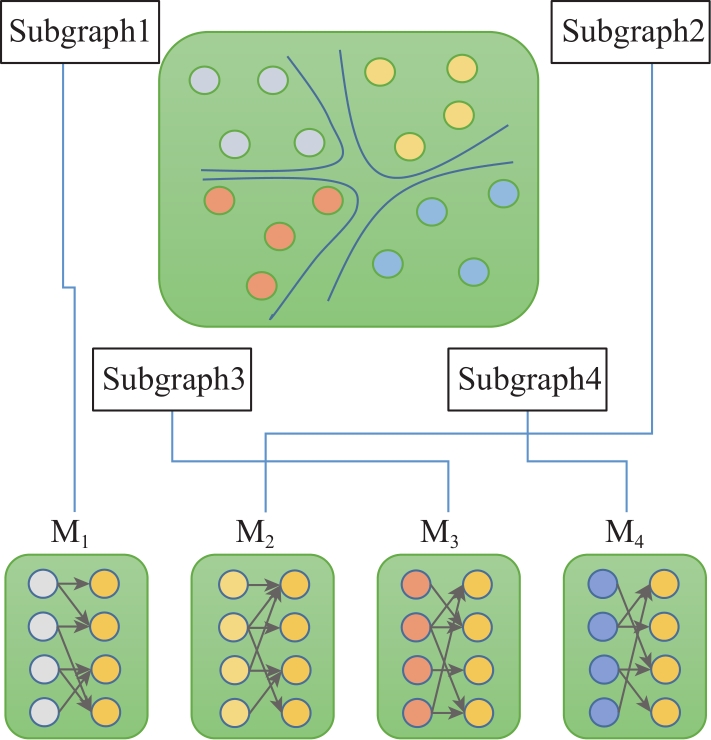
| [1] |
GRECHANIK M, FU C, XIE Q, et al. A search engine for finding highly relevant applications[C]// Acm/ieee International Conference on Software Engineering. ACM, 2010: 475-484.
|
| [2] |
JIE L, DIANSHUANG W, MINGSONG M Z, et al. Recommender system application developments: A survey[J]. Decision Support Systems, 2015, 74: 12-32.
|
| [3] |
FUYU L, TAIWEI J, CHANGLONG Y, et al. SDM: Sequential Deep Matching Model for Online Large-scale Recommender System[C]// Conference on Information and Knowledge Management, 2019: 2635-2643.
|
| [4] |
COVINGTON P, ADAMS J, SARGIN E. Deep Neural Networks for YouTube Recommendations[C]// Acm Conference on Recommender Systems. ACM, 2016: 191-198.
|
| [5] |
SHUMPEI O, YUKIHIRO T, SHINGO O, et al. Embedding-based News Recommendation for Millions of Users[C]// Knowledge Discovery and Data Mining, 2017: 1933-1942.
|
| [6] |
MCLAUGHLIN M R, HERLOCKER J L. A collaborative filtering algorithm and evaluation metric that accurately model the user experience[C]// International Acm Sigir Conference on Research & Development in Information Retrieval. ACM, 2004: 329-336.
|
| [7] |
KOREN Y, BELL R, VOLINSKY C. Matrix Factorization Techniques for Recommender Systems[J]. IEEE, 2009, 42(8): 30-37.
|
| [8] |
HE X, DENG K, WANG X, et al. LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation[C]// International ACM SIGIR Conference on Research and Development in Information Retrieval, 2020: 639-648.
|
| [9] |
CHEN M, LIHENG M, YINGXUE Z, et al. Memory Augmented Graph Neural Networks For Sequential Recommendation[C]// National Conference on Artificial Intelligence, 2020, 34: 5045-5052.
|
| [10] |
DONG H K, CHANYOUNG P, JINOH O, et al. Convolutional Matrix Factorization for Document Context-Aware Recommendation[C]// Conference on Recommender Systems, 2016: 233-240.
|
| [11] |
STEFFEN R, CHRISTOPH F, ZENO G, et al. BPR: Bayesian personalized ranking from implicit feedback[C]// Uncertainty in Artificial Intelligence, 2012: 452-461.
|
| [12] |
ZHANG W, WANG J Y, FENG W. Combining latent factor model with location features for event-based group recommendation[M]. Knowledge Discovery and Data Mining, 2013: 910-918.
|
| [13] |
GUO Q Y, ZHUANG F Z, QIN C, et al. A Survey on Knowledge Graph-Based Recommender Systems[J]. IEEE Annals of the History of Computing, 2022, 34(8): 3549-3568.
|
| [14] |
WU Z H, PAN S R, CHEN F W, et al. A Comprehensive Survey on Graph Neural Networks[J]. IEEE Transactions on Neural Networks and Learning Systems, 2021, 32(1): 4-24.
|
| [15] |
GEORGE K, VIPIN K. A Fast and High Quality Multilevel Scheme for Partitioning Irregular Graphs[J]. SIAM Journal on Scientific Computing, 1999, 20(1): 359-392.
|
| [16] |
MAXWELL H F, JOSEPH A K. The MovieLens Datasets: History and Context[J]. ACM transactions on interactive intelligent systems, 2016, 5(4): 1-19.
|
| [17] |
JOHN C D, ELAD H, YORAM S. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization[J]. Journal of Machine Learning Research, 2011, 12(61): 2121-2159.
|
 ),熊菲1,*(
),熊菲1,*(