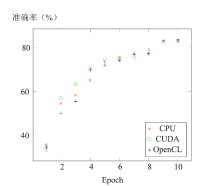
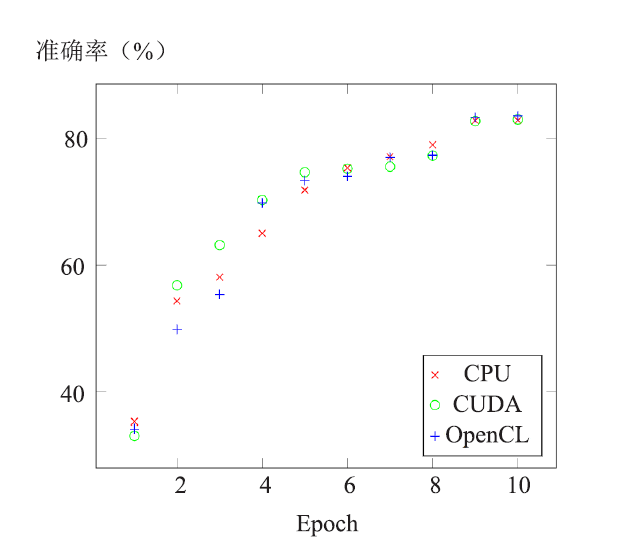
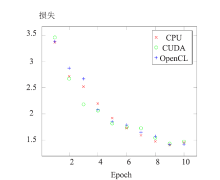
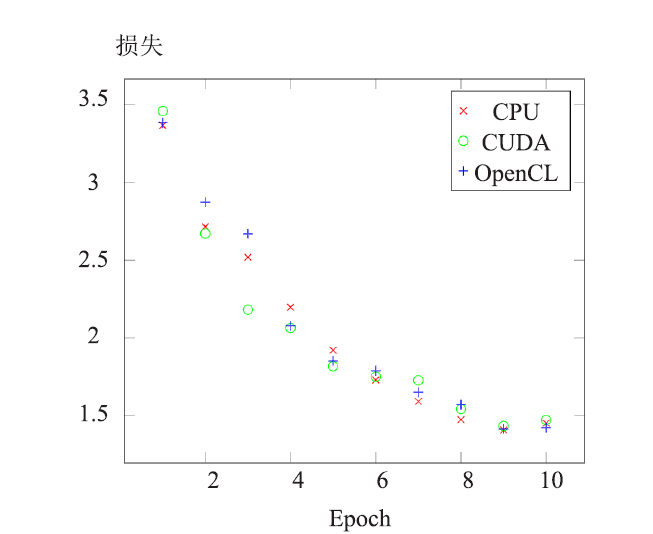
| [1] |
NVIDIA Corporation. NVIDIA CUDA编程指南[EB/OL]. [2021/11/04]. https://www.nvidia.cn/docs/IO/51635/NVIDIA_CUDA_Programming_Guide_1.1_chs.pdf.
|
| [2] |
Munshi A. The opencl specification[C]. 2009 IEEE Hot Chips 21 Symposium (HCS), IEEE, 2009: 1-314.
|
| [3] |
Abadi M, Barham P, Chen J, et al. {TensorFlow}: A Sy-stem for {Large-Scale} Machine Learning[C]. 12th US-ENIX symposium on operating systems design and implementation (OSDI 16), 2016: 265-283.
|
| [4] |
Abadi M, Agarwal A, Barham P, et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems[J]. arXiv preprint arXiv:1603.04467, 2016.
|
| [5] |
Sanders J, Kandrot E. CUDA by example: an introduction to general-purpose GPU programming[M]. Addison-Wesley Professional, 2010:14-19.
|
| [6] |
NVIDIA Corporation. Cuda toolkit | nvidia developer[EB/OL]. [2021/11/04]. https://developer.nvidia.cn/zh-cn/cuda-toolkit.
|
| [7] |
The Khronos® Group Inc. Opencl overview - the khro-nos group inc[EB/OL]. [2021/11/04]. https://www.kh-ronos.org/opencl/.
|
| [8] |
Perkins H. CUDA-on-CL: a compiler and runtime for running NVIDIA® CUDA™ C++ 11 applications on OpenCL™ 1.2 Devices[C]// Proceedings of the 5th Inter-national Workshop on OpenCL, 2017: 1-4.
|
| [9] |
hughperkins. tf-coriander - OpenCL 1.2 implementation for Tensorflow[EB/OL]. [2021/11/04]. https://github.com/hughperkins/tf-coriander.
|
| [10] |
The Khronos® Group Inc. SYCL Overview - The Khr-onos Group Inc[EB/OL]. [2021/11/04]. https://www.khronos.org/sycl/.
|
| [11] |
Goli M, Iwanski L, Richards A. Accelerated machine learning using TensorFlow and SYCL on OpenCL Dev-ices[C]// Proceedings of the 5th International Workshop on OpenCL, 2017: 1-4.
|
| [12] |
Goli M, Iwanski L, Lawson J, et al. OpenCL Acceleration for TensorFlow[J]. arXiv preprint arXiv:1605.02688, 2018: 1-3.
|
| [13] |
Codeplay Developer. Home - ComputeCpp CE - Pro-ducts[EB/OL]. [2021/11/04]. https://developer.codeplay.com/products/computecpp/ce/home.
|
| [14] |
The Khronos Group Inc. SPIR Overview[EB/OL]. [2021/11/04]. https://www.khronos.org/spir/.
|
| [15] |
NVIDIA Corporation. An Easy Introduction to CUDA C and C++[EB/OL]. [2021/11/04]. https://developer.nvidia.com/blog/easy-introduction-cuda-c-and-c/.
|
| [16] |
Kondratyuk N, Nikolskiy V, Pavlov D, et al. GPU-acc-elerated molecular dynamics: State-of-art software perfor-mance and porting from Nvidia CUDA to AMD HIP[J]. The International Journal of High Performance Comput-ing Applications, 2021, 35(4): 312-324.
|
| [17] |
Keryell R, Reyes R, Howes L. Khronos SYCL for Open-CL: a tutorial[C]. Proceedings of the 3rd Inter-national Workshop on OpenCL, 2015: 1-1.
|
| [18] |
TensorFlow. Create an op | tensorflow core[EB/OL]. [2021/11/04]. https://www.tensorflow.org/guide/create_op.
|
| [19] |
KnuEdge. Constructing a fake device in tensorflow[EB/OL]. [2021/11/04]. https://github.com/knuedge/ten-sorf-low/blob/36e0cdf04f294bfd51931d4f78e291590ed0d3ec/tensorflow/g3doc/hardware/adding_support/fake_device.md.
|
| [20] |
Martin York. C++ singleton design pattern[EB/OL]. [2021/11/04]. https://stackoverflow.com/questions/1008019/c-singleton-design-pattern.
|
| [21] |
Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J]. arXiv preprint arXiv:1409.1556, 2014.
|
| [22] |
He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]. Proceedings of the IEEE conference on computer vision and pattern recognition, 2016: 770-778.
|
| [23] |
YunYang1994. TensorFlow2.0-Examples - Difficult alg-orithm, Simple code [EB/OL]. [2021/11/04]. https://github.com/YunYang1994/TensorFlow2.0-Examples.
|
| [24] |
Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J]. arXiv pre-print arXiv:1409.1556, 2014.
|
| [25] |
He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]// Proceedings of the IEEE con-ference on computer vision and pattern recognition, 2016: 770-778.
|
 ),程大果(
),程大果(