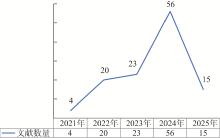
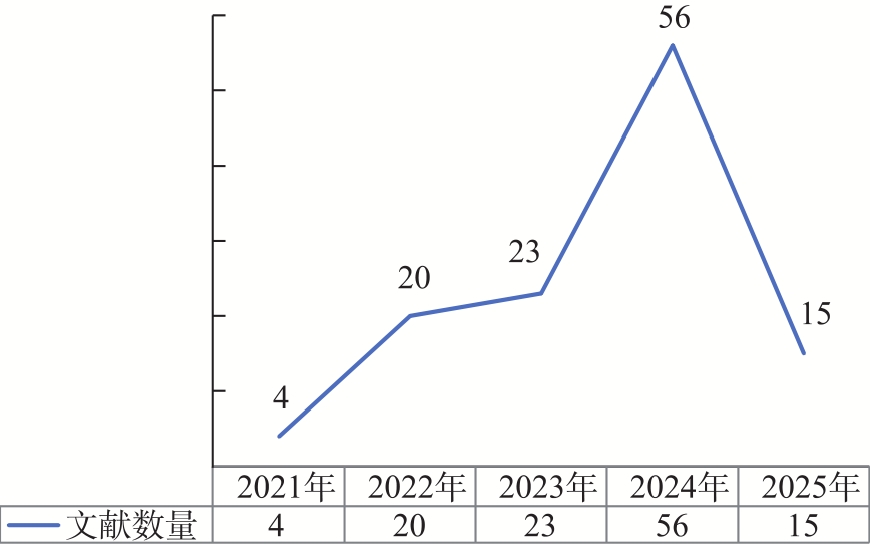
| [1] |
TAN X, QIN T, SOONG F, et al. A survey on neural speech synthesis[J]. arXiv, 2021, 2106.15561.
|
| [2] |
JIA Y, ZHANG Y, WEISS R, et al. Transfer learning from speaker verification to multispeaker text-to-speech synthesis[C]// Advances in Neural Information Processing Systems (NeurIPS). 2018, 31.
|
| [3] |
CASANOVA E, WEBER J, SHULBY C D, et al. YourTTS: Towards zero-shot multi-speaker TTS and zero-shot voice conversion for everyone[C]// International Conference on Machine Learning (ICML). PMLR, 2022: 2709-2720.
|
| [4] |
WANG C, CHEN S, WU Y, et al. Neural codec language models are zero-shot Text-to-Speech synthesizers[J]. arXiv, 2023, 2301.02111.
|
| [5] |
LI Y A, HAN C, RAGHAVAN V, et al. StyleTTS 2: Towards human-level text-to-speech through style diffusion and adversarial training with large speech language models[J]. Advances in Neural Information Processing Systems, 2023, 36: 19594-19621.
pmid: 39866554
|
| [6] |
Peng P, Huang P Y, Li S W, et al. Voicecraft: Zero-shot speech editing and text-to-speech in the wild[C]// Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1:Long Papers), 2024: 12442-12462.
|
| [7] |
LAM P, ZHANG H, CHEN N F, et al. PRESENT: zero-shot text-to-prosody control[J]. IEEE Signal Processing Letters, 2025.
|
| [8] |
DU Z, WANG Y, CHEN Q, et al. CosyVoice 2: Scalable streaming speech synthesis with large language models[J]. arXiv, 2024, 2412.10117.
|
| [9] |
JIANG Z, REN Y, LI R, et al. MegaTTS 3: Sparse alignment enhanced latent diffusion transformer for zero-shot speech synthesis[J]. arXiv, 2025, 2502. 18924.
|
| [10] |
LI Y A, HAN C, MESGARANI N. StyleTTS: A style-based generative model for natural and diverse text-to-speech synthesis[J]. IEEE Journal of Selected Topics in Signal Processing, 2025.
|
| [11] |
GUO Y, DU C, CHEN X, et al. EmoDiff: Intensity-controllable emotional text-to-speech with soft-label guidance[C]// ICASSP 2023—IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE, 2023: 1-5.
|
| [12] |
CHEN Y, NIU Z, MA Z, et al. F5-TTS: A fairytaler that fakes fluent and faithful speech with flow matching[J]. arXiv, 2024, 2410.06885.
|
| [13] |
唐浩彬, 张旭龙, 王健宗, 等. 表现性语音合成综述[J]. 大数据, 2023, 9(6): 53-71.
doi: 10.11959/j.issn.2096-0271.2022082
|
| [14] |
KONG J, KIM J, BAE J. HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis[J]. Advances in Neural Information Processing Systems, 2020, 33: 17022-17033.
|
| [15] |
LEE S, PING W, GINSBURG B, et al. BigVGAN: A universal neural vocoder with large-scale training[J]. arXiv, 2022, 2206. 04658.
|
| [16] |
QIU Z, TANG J, ZHANG Y, et al. A voice cloning method based on the improved HiFi-GAN model[J]. Computational Intelligence and Neuroscience, 2022, 2022: 6707304.
|
| [17] |
LI Y, YU C, SUN G, et al. Cross-Utterance conditioned VAE for speech generation[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2024, 32: 4263-4276.
doi: 10.1109/TASLP.2024.3453598
|
| [18] |
KIM J, KONG J, SON J. Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech[C]// International Conference on Machine Learning (ICML). PMLR, 2021: 5530-5540.
|
| [19] |
CASANOVA E, SHULBY C, GÖLGE E, et al. SC-GlowTTS: An efficient zero-shot multi-speaker text-to-speech model[J]. arXiv, 2021, 2104. 05557.
|
| [20] |
KIM S, SHIH K, SANTOS J F, et al. P-Flow: A fast and data-efficient Zero-shot TTS through speech prompting[J]. Advances in Neural Information Processing Systems, 2023, 36: 74213-74228.
|
| [21] |
BILINSKI P, MERRITT T, EZZERG A, et al. Creating new voices using normalizing flows[C]// Interspeech 2022. 2022: 2958-2962.
|
| [22] |
LE M, VYAS A, SHI B, et al. Voicebox: Text-guided multilingual universal speech generation at scale[J]. Advances in Neural Information Processing Systems, 2023, 36: 14005-14034.
|
| [23] |
BANG C W, CHUN C. Effective zero-shot multi-speaker text-to-speech technique using information perturbation and a speaker encoder[J]. Sensors, 2023, 23(23): 9591.
doi: 10.3390/s23239591
|
| [24] |
SHEN K, JU Z, TAN X, et al. NaturalSpeech 2: Latent diffusion models are natural and zero-shot speech and singing synthesizers[J]. arXiv, 2023, 2304. 09116.
|
| [25] |
JU Z, WANG Y, SHEN K, et al. NaturalSpeech 3: zero-shot speech synthesis with factorized codec and diffusion models[J]. arXiv, 2024, 2403. 03100.
|
| [26] |
ESKIMEZ S E, WANG X, THAKKER M, et al. E2 TTS: Embarrassingly easy fully non-autoregressive Zero-shot TTS[C]// IEEE Spoken Language Technology Workshop (SLT). IEEE, 2024: 682-689.
|
| [27] |
GOSWAMI N, HARADA T. SA-TTS: Speaker attractor text-to-speech, learning to speak by learning to separate[J]. arXiv, 2022, 2207.06011.
|
| [28] |
刘朝辞. 基于隐含表征的语音合成韵律建模方法研究[D]. 合肥: 中国科学技术大学, 2025.
|
| [29] |
岳焕景, 王嘉玮, 杨敬钰. 基于音素级韵律建模的自回归零样本语音合成[J]. 湖南大学学报(自然科学版), 2025, 52(4): 114-123.
|
| [30] |
PANKOV V, PRONINA V, KUZMIN A, et al. DINO-VITS: Data-efficient Zero-shot TTS with self-supervised speaker verification loss for noise robustness[J]. arXiv, 2023, 2311.09770.
|
| [31] |
付毅冲. 零样本个性化语音合成的研究[D]. 北京: 北京邮电大学, 2024.
|
| [32] |
LI J, ZHANG L. ZSE-VITS: A zero-shot expressive voice cloning method based on VITS[J]. Electronics, 2023, 12(4): 820.
doi: 10.3390/electronics12040820
|
| [33] |
CASANOVA E, DAVIS K, GÖLGE E, et al. XTTS: A massively multilingual zero-shot Text-to-Speech model[J]. arXiv, 2024, 2406.04904.
|
| [34] |
王陈偲, 杨思燕, 苗启广. 基于XTTS模型的声音克隆系统研究[J/OL]. 计算机科学, 1-10 [2025-09-12]. https://link.cnki.net/urlid/50.1075.tp.20250815.0949.022.
|
| [35] |
JIANG Z, LIU J, REN Y, et al. Mega-TTS 2: Boosting prompting mechanisms for zero-shot speech synthesis[J]. arXiv, 2023, 2307.07218.
|
| [36] |
LEI Y, YANG S, CONG J, et al. Glow-WaveGAN 2: High-quality zero-shot Text-to-Speech synthesis and any-to-any voice conversion[J]. arXiv, 2022, 2207.01832.
|
| [37] |
CHEN S, LIU S, ZHOU L, et al. VALL-E 2: Neural codec language models are human-parity zero-shot Text-to-Speech synthesizers[J]. arXiv, 2024, 2406.05370.
|
| [38] |
韩冰, 钱彦旻. VALL-E R: 利用单调对齐策略的鲁棒且高效零样本语音合成[J/OL]. 信号处理, 1-13 [2025-09-12]. https://link.cnki.net/urlid/11.2406.tn.20250728.1918.006.
|
| [39] |
ZHANG Z, ZHOU L, WANG C, et al. Speak foreign languages with your own voice: Cross-lingual neural codec language modeling[J]. arXiv, 2023, 2303. 03926.
|
| [40] |
ANASTASSIOU P, CHEN J, CHEN J, et al. Seed-TTS: A family of high-quality versatile speech generation models[J]. arXiv, 2024, 2406. 02430.
|
| [41] |
YE Z, ZHU X, CHAN C M, et al. LLASA: Scaling train-time and inference-time compute for LLaMA-based speech synthesis[J]. arXiv, 2025, 2502. 04128.
|
 ),唐云祁2,*(
),唐云祁2,*(