数据与计算发展前沿 ›› 2021, Vol. 3 ›› Issue (1): 112-121.
doi: 10.11871/jfdc.issn.2096-742X.2021.01.009
• 技术与应用 • 上一篇
翟擎辰1,3( ),周园春1(),宋秋成1(),王建伟2(),孟珍1,*(),张艳玲2,*()
),周园春1(),宋秋成1(),王建伟2(),孟珍1,*(),张艳玲2,*()
ZHAI Qingchen1,3(),ZHOU Yuanchun1(),SONG Qiucheng1(),WANG Jianwei2(),MENG Zhen1,*(),ZHANG Yanling2,*()
摘要:
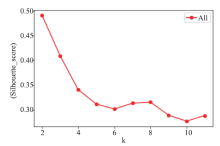
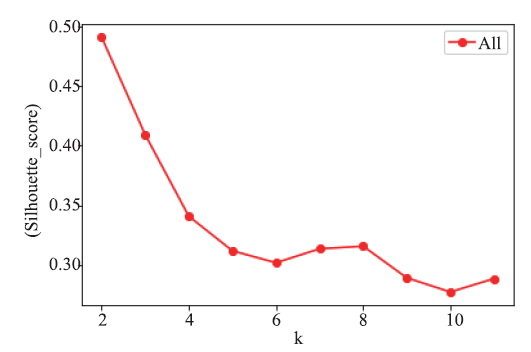
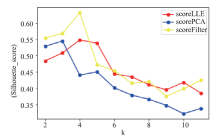
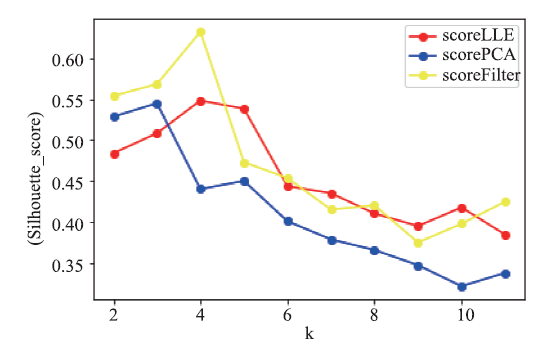
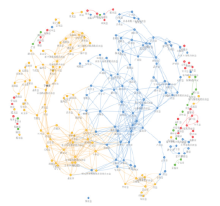
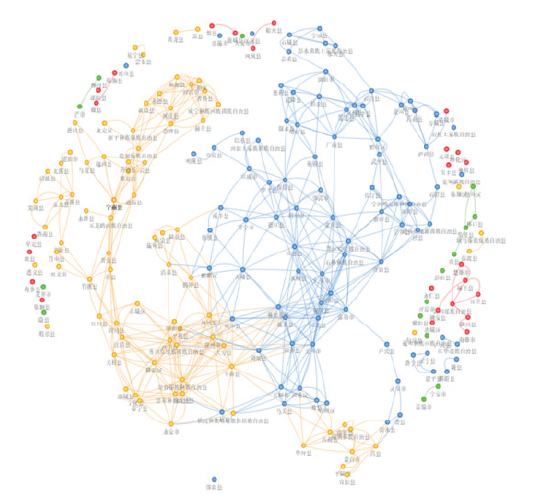
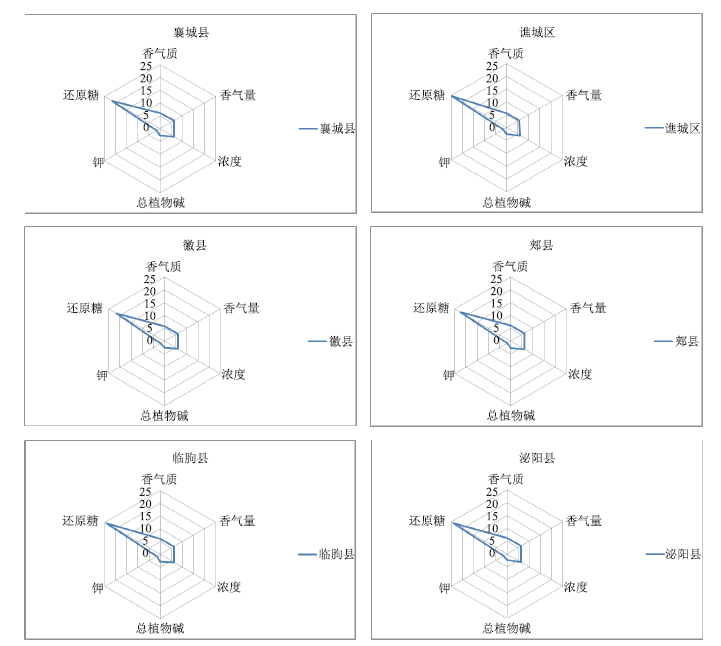
[目的]为了对烟叶产地进行相似性度量和分类,并克服高维空间下距离度量失效的问题。[方法]文章通过方差权重法、主成分分析法及局部线性嵌入法三种方法对烟叶属性指标进行降维和筛选,使用经过特征降维后的数据相似性进行计算及K-means聚类分析。[结果]通过分析不同方法所得输入指标的聚类的轮廓系数发现,方差权重法所筛选出的总植物碱、还原糖、钾、含梗率四个指标的聚类效果较两种降维算法所得的指标的聚类效果更好,对烟叶质量评估有较强的参考价值。K-means聚类算法将烟叶产区分为四类并且得到各类中属性特点,通过相似性算法所得到的结果在以麒麟区、宣威县、罗平县为代表的县区的相似性产地上与业内现有研究相互验证。[结论]文章基于机器学习算法,通过数据挖掘得到烟叶感官数据中的特征性指标与产地之间的相似性特点,为烟叶工业生产提供了具有一定参考价值的指标与结论,也为机器学习在烟草工业中的应用提供了算法基础。