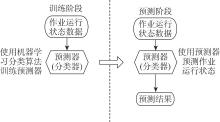
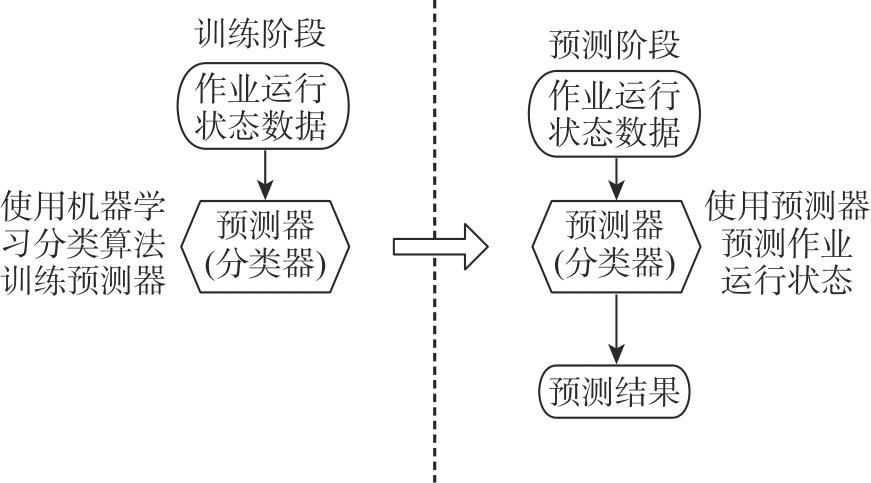
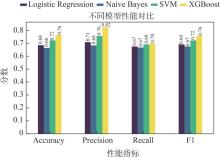
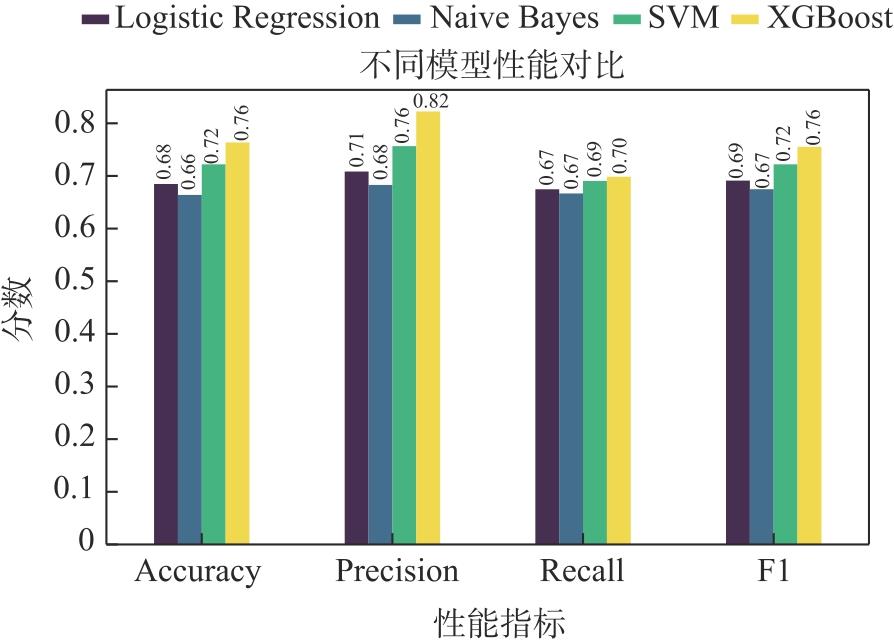
| [1] |
ZHANG Bin,LI Chen,LU Zhonghua.
A Survey of Research on Risk Factors in the Chinese Stock Market
[J]. Frontiers of Data and Computing, 2024, 6(6): 146-159.
|
| [2] |
LONG Chun, LI Lisha, LI Jing, YANG Fan, WEI Jinxia, Fu Yuhao.
Review of Research on Secure Inference in Machine Learning
[J]. Frontiers of Data and Computing, 2024, 6(5): 1-12.
|
| [3] |
GUO Xuebing, ZHU Xiaojie, TANG Xinzhai, YANG Gang, HOU Yanfei, HE Honglin.
Study on Integration Method of Algorithm Model Based on Big Data Pipeline— Taking Tree Biomass Inversion Based on Machine Learning Method and LiDAR Data as an Example
[J]. Frontiers of Data and Computing, 2024, 6(4): 96-105.
|
| [4] |
HE Ruilin, YANG Xinyi, SUN Hongzan, LI Chen.
The Latest Development and Prospects of Histopathological Image Analysis Methods Based on Graph Features
[J]. Frontiers of Data and Computing, 2024, 6(2): 101-116.
|
| [5] |
YE Xu, DU Yi, CUI Wenjuan, SHEN Junjie, XIE Jing, WANG Ludi.
Application of Machine Learning Technology in the Field of Eye Health
[J]. Frontiers of Data and Computing, 2024, 6(2): 117-133.
|
| [6] |
ZHAO Yining, XIAO Haili.
A Monitoring and Diagnosis System for CNGrid
[J]. Frontiers of Data and Computing, 2024, 6(1): 57-67.
|
| [7] |
SHEN Zhihao, LI Na, YIN Shihao, DU Yi, HU Lianglin.
Airfare Price Prediction Based on TPA-Transformer
[J]. Frontiers of Data and Computing, 2023, 5(6): 115-125.
|
| [8] |
WEI Ting, PENG Liang, NIU Tie, ZHANG Honghai.
Detection and Root Cause Analysis of HPC Failure Jobs Based on Feature Analysis
[J]. Frontiers of Data and Computing, 2023, 5(6): 94-103.
|
| [9] |
SUN Yifan, ZHANG Rui, TAO Yang, GAO Birou, QIN Shihan, AN Chao.
A Survey on Local Differential Privacy
[J]. Frontiers of Data and Computing, 2023, 5(5): 74-97.
|
| [10] |
TIAN Yiqing, CHENG Xi, FENG Bojing.
A Review of Computational Models for Corporate Credit Rating
[J]. Frontiers of Data and Computing, 2023, 5(4): 139-153.
|
| [11] |
CHEN Meilin, LIU Duanyang, XU Liming, WANG Yang.
A Review of Force Field Models Based on Machine Learning
[J]. Frontiers of Data and Computing, 2023, 5(4): 27-37.
|
| [12] |
LIU Duanyang, WEI Zhongming.
Application of Supervised Learning Algorithms in Materials Science
[J]. Frontiers of Data and Computing, 2023, 5(4): 38-47.
|
| [13] |
LI Yan,HE Hongbo,WANG Runqiang.
A Survey of Research on Microblog Popularity Prediction
[J]. Frontiers of Data and Computing, 2023, 5(2): 119-135.
|
| [14] |
GAO Tian,ZHU Jiaojun,ZHANG Jinxin,SUN Yirong,YU Fengyuan,TENG Dexiong,LU Deliang,YU Lizhong,WANG Zongguo.
Estimation of Carbon Flux of a Temperate Forest Ecosystem Based on Next-Generation Information Technologies
[J]. Frontiers of Data and Computing, 2023, 5(2): 60-72.
|
| [15] |
WANG Fan,FENG Liqiang,CAO Rongqiang.
Design and Application of Big Data-Driven Ocean Artificial Intelligence Service Platform
[J]. Frontiers of Data and Computing, 2023, 5(2): 73-85.
|
 ),NIU Tie1,WEI Ting1,PENG Liang1
),NIU Tie1,WEI Ting1,PENG Liang1