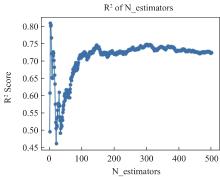
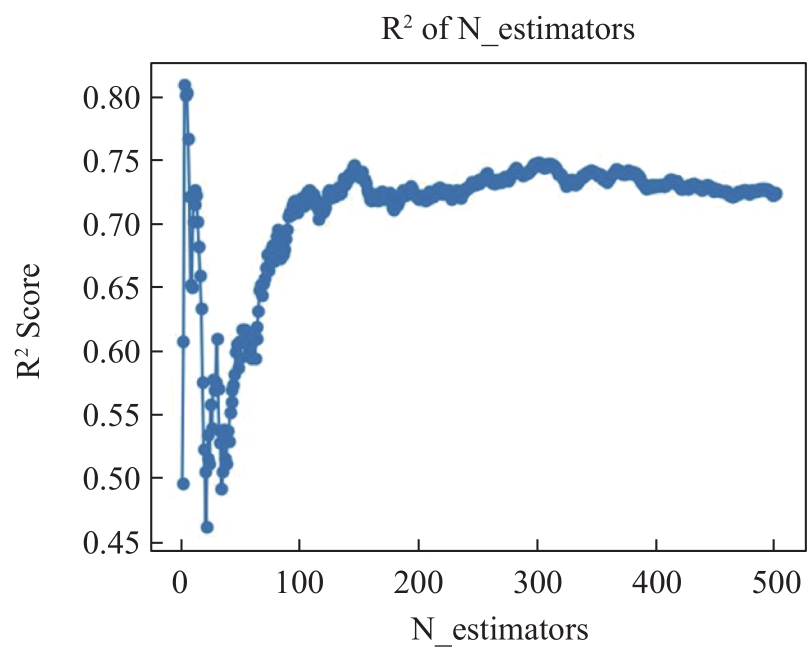
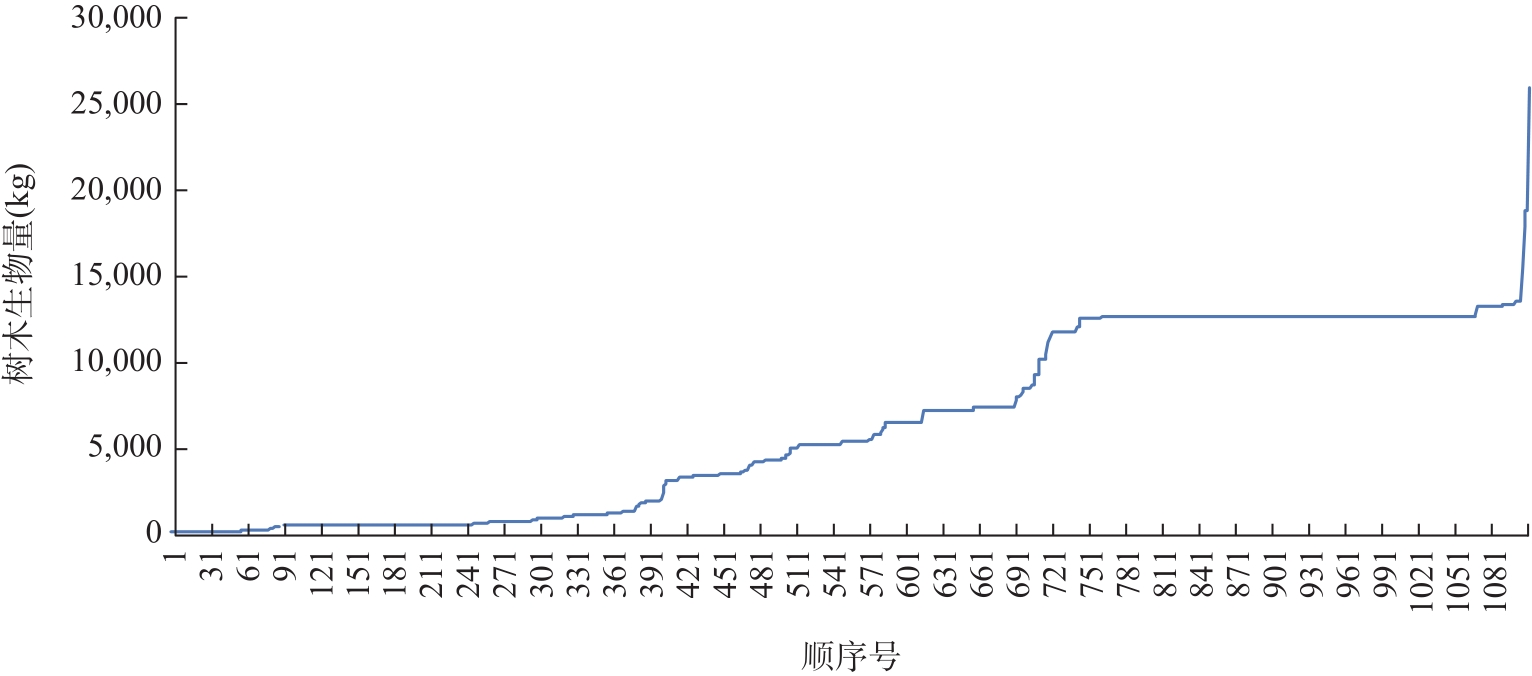
| [1] |
郭庆华, 刘瑾, 陶胜利, 等. 激光雷达在森林生态系统监测模拟中的应用现状与展望[J]. 科学通报, 2014, 59(6): 459-478.
|
| [2] |
王云飞, 庞勇, 舒清态. 基于随机森林算法的橡胶林地上生物量遥感反演研究——以景洪市为例[J]. 西南林业大学学报, 2013, 33(6): 38-45.
|
| [3] |
高燕, 梁泽毓, 王彪. 基于无人机和卫星遥感影像的升金湖草滩植被地上生物量反演[J]. 湖泊科学, 2019, 31(2): 517-528. DOI: 10.18307/2019.0220.
|
| [4] |
洪奕丰, 张守攻, 陈伟, 等. 基于机载激光雷达的落叶松组分生物量反演[J]. 林业科学研究, 2019, 32(5): 83-90. DOI: 10.13275/j.cnki.lykxyj.2019.05.11.
|
| [5] |
杨萍, 于秀波, 庄绪亮, 等. 中国科学院生态系统研究网络(CERN)的现状及未来发展思路[J]. 中国科学院院刊, 2008, 23(6): 555-561.
|
| [6] |
刘敏, 何洪林, 吴楠, 等. 基于Web Service和科学工作流技术的碳通量数据处理系统实现研究[J]. 科研信息化技术与应用, 2013, 4(2): 50-58.
|
| [7] |
朱小杰, 赵子豪, 杜一. 模型驱动的大数据流水线框架PiFlow[J]. 计算机应用, 2020, 40(6): 1638-1647.
doi: 10.11772/j.issn.1001-9081.2019101793
|
| [8] |
苏文, 张黎, 郭学兵, 等. 生态系统长期观测数据产品体系[J]. 大数据, 2022, 8(1): 84-97. doi: 10.11959/j.issn.2096-0271.2022008.
|
| [9] |
张鹏, 马庆勋, 吕杰, 等. 机器学习算法在森林地上生物量估算中的应用[J]. 测绘通报, 2021(12): 28-32. DOI: 10.13474/j.cnki.11-2246.2021.367.
|
| [10] |
BIAU G. Analysis of a random forests model[J]. The Journal of Machine Learning Research, 2012(13): 1063-1095.
|
| [11] |
ALI J, KHAN R, AHMAD N, et al. Random forests and decision trees[J]. International Journal of Computer Science Issues (IJCSI), 2012, 9(5): 272-285.
|
| [12] |
TRISTAN GOULDEN, NEON(National Ecological Observatory Network). Data Tutorial: Calculate Vegetation Biomass from LiDAR Data in Python[DB/OL]. https://www.neonscience.org/resources/learning-hub/tutorials/calc-biomass-py(accessed 2023/09/02).
|
| [13] |
TRAVIS E. Oliphant. Python for Scientific Computing[J]. Computing in Science & Engineering, 2007, 9(3): 10-20.
|
| [14] |
朱小杰, 王华进, 沈志宏, 等. 端到端的科学数据跨中心工作流分析框架[J]. 数据与计算发展前沿, 2023, 5(1): 15-27.
|
 ),ZHU Xiaojie3,TANG Xinzhai1,YANG Gang3,HOU Yanfei1,2,HE Honglin1,2
),ZHU Xiaojie3,TANG Xinzhai1,YANG Gang3,HOU Yanfei1,2,HE Honglin1,2