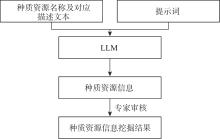
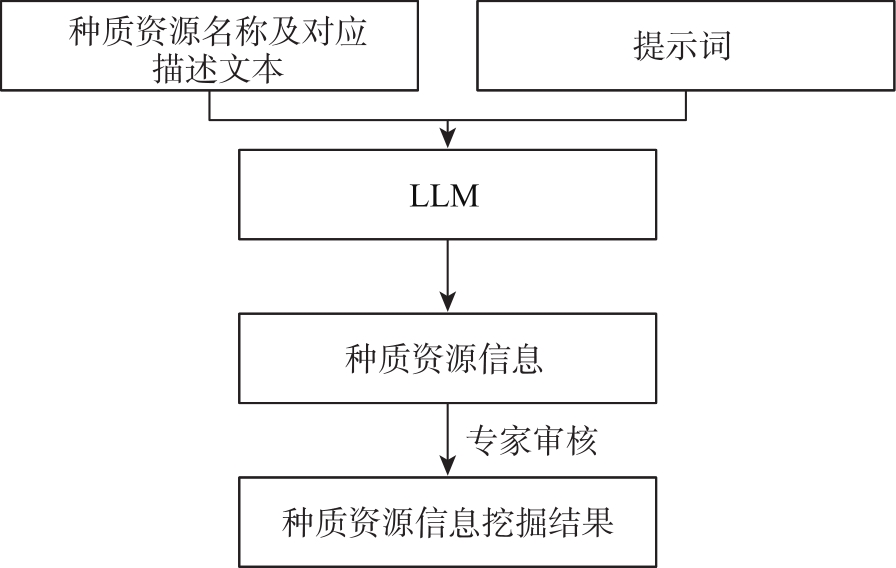
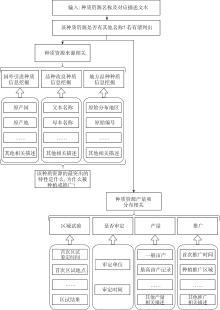
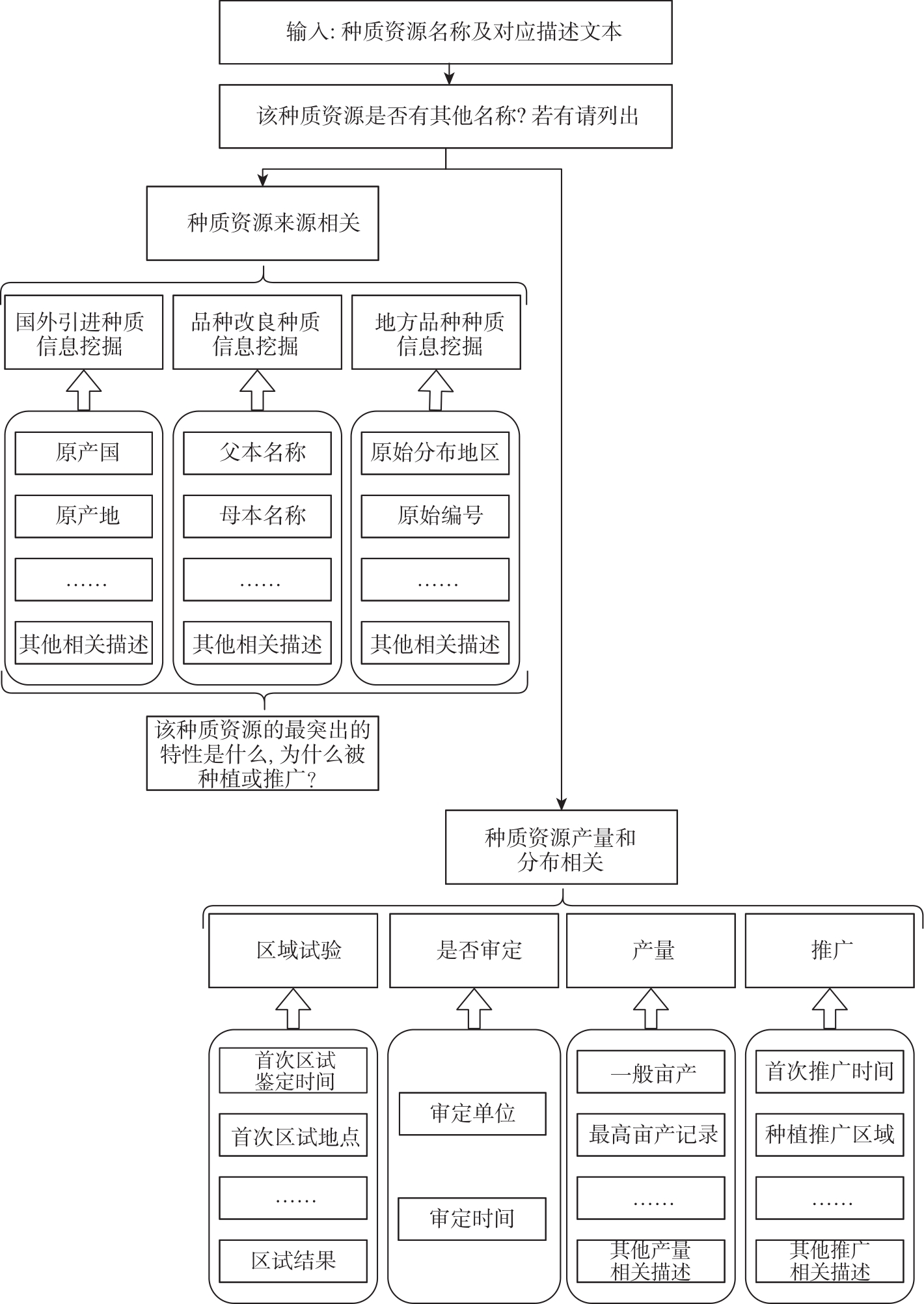
| [1] |
唐建卫, 高艳, 胡润雨, 等. 近十年基于重要小麦亲本周麦22的遗传改良[J]. 麦类作物学报, 2021, 41(3): 263-271.
|
| [2] |
郝晨阳, 董玉琛, 王兰芬, 等. 我国普通小麦核心种质的构建及遗传多样性分析[J]. 科学通报, 2008(8): 908-915.
|
| [3] |
相吉山, 杨欣明, 李秀全, 等. 小麦骨干亲本南大2419对衍生品种(系)HMW-GS的贡献分析[J]. 植物遗传资源报, 2013, 14(6): 1053-1058.
|
| [4] |
潘玉朋, 李立群, 郑锦娟, 等. 黄淮麦区近年大面积推广小麦品种的遗传多样性分析[J]. 西北农业学报, 2011, 20(4): 47-52.
|
| [5] |
SHANAHAN M. Talking about large language models[J]. Communications of the ACM, 2024, 67(2): 68-79.
|
| [6] |
BROWN T, MANN B, RYDER N, et al. Language models are few-shot learners[J]. Advances in Neural Information Processing Systems, 2020, 33: 1877-1901.
|
| [7] |
CHOWDHERY A, NARANG S, DEVLIN J, et al. Palm: Scaling language modeling with pathways[J]. Journal of Machine Learning Research, 2023, 24(240): 1-113.
|
| [8] |
TOUVRON H, LAVRIL T, IZACARD G, et al. Llama: Open and efficient foundation language models[J]. arXiv preprint arXiv:2302.13971, 2023.
|
| [9] |
QIN C, ZHANG A, ZHANG Z, et al. Is ChatGPT a general-purpose natural language processing task solver?[J]. arXiv preprint arXiv:2302.06476, 2023.
|
| [10] |
OpenAI R. Gpt-4 technical report. arxiv 2303.08774[J]. View in Article, 2023, 2: 3.
|
| [11] |
HAN X, ZHANG Z, DING N, et al. Pre-trained models: Past, present and future[J]. AI Open, 2021, 2: 225-250.
|
| [12] |
WEI J, TAY Y, BOMMASANI R, et al. Emergent abilities of large language models[J]. arXiv preprint arXiv:2206.07682, 2022.
|
| [13] |
HOFFMANN J, BORGEAUD S, MENSCH A, et al. Training compute-optimal large language models[J]. arXiv preprint arXiv:2203.15556, 2022.
|
| [14] |
BIAN J, ZHENG J, ZHANG Y, et al. Inspire the Large Language Model by External Knowledge on BioMedical Named Entity Recognition[J]. arXiv preprint arXiv:2309.12278, 2023.
|
| [15] |
POLAK M P, MORGAN D. Extracting accurate materials data from research papers with conversational language models and prompt engineering[J]. Nature Communications, 2024, 15(1): 1569.
|
| [16] |
GILARDI F, ALIZADEH M, KUBLI M. Chatgpt outperforms crowd-workers for text-annotation tasks[J]. arXiv preprint arXiv:2303.15056, 2023.
|
| [17] |
HUANG J, GU S S, HOU L, et al. Large language models can self-improve[J]. arXiv preprint arXiv:221 0.11610, 2022.
|
| [18] |
TANG R, HAN X, JIANG X, et al. Does synthetic data generation of llms help clinical text mining?[J]. arXiv preprint arXiv:2303.04360, 2023.
|
| [19] |
JEBLICK K, SCHACHTNER B, DEXL J, et al. ChatGPT makes medicine easy to swallow: an exploratory case study on simplified radiology reports[J]. European Radiology, 2023: 1-9.
|
| [20] |
CHOI J H, HICKMAN K E, MONAHAN A, et al. Chatgpt goes to law school[J]. Available at SSRN, 2023.
|
| [21] |
NOV O, SINGH N, MANN D M. Putting ChatGPT’s medical advice to the (Turing) test[J]. medRxiv, 2023: 2023.01. 23.23284735.
|
| [22] |
BLAIR-STANEK A, HOLZENBERGER N, VAN D URME B. Can GPT-3 perform statutory reasoning?[J]. arXiv preprint arXiv:2302.06100, 2023.
|
| [23] |
BANG Y, CAHYAWIJAYA S, LEE N, et al. A multitask, multilingual, multimodal evaluation of chatgpt on reasoning, hallucination, and interactivity[J]. arXiv preprint arXiv:2302.04023, 2023.
|
| [24] |
FLORIDI L, CHIRIATTI M. GPT-3: Its nature, scope, limits, and consequences[J]. Minds and Machines, 2020, 30: 681-694.
|
| [25] |
ACHIAM J, ADLER S, AGARWAL S, et al. Gpt-4 technical report[J]. arXiv preprint arXiv:2303.08774, 2023.
|
| [26] |
KURIBAYASHI T, OSEKI Y, TAIEB S B, et al. Large Language Models Are Human-Like Internally[J]. arXiv preprint arXiv:2502.01615, 2025.
|
| [27] |
RADFORD A, WU J, CHILD R, et al. Language models are unsupervised multitask learners[J]. OpenAI Blog, 2019, 1(8): 9.
|
| [28] |
TOUVRON H, LAVRIL T, IZACARD G, et al. Llama: Open and efficient foundation language models[J]. arXiv preprint arXiv:2302.13971, 2023.
|
| [29] |
TOUVRON H, MARTIN L, STONE K, et al. Llama 2: Open foundation and fine-tuned chat models[J]. arXiv preprint arXiv:2307.09288, 2023.
|
| [30] |
MIN B, ROSS H, SULEM E, et al. Recent advances in natural language processing via large pre-trained language models: A survey[J]. ACM Computing Surveys, 2023, 56(2): 1-40.
|
| [31] |
YOO K M, PARK D, KANG J, et al. Gpt3mix: Leveraging large-scale language models for text augmentation[J]. arXiv preprint arXiv:2104.08826, 2021.
|
| [32] |
ALBRECHT J, KITANIDIS E, FETTERMAN A J. Despite “super-human” performance, current LLMs are unsuited for decisions about ethics and safety[J]. arXiv preprint arXiv:2212.06295, 2022.
|
| [33] |
LIANG P P, WU C, MORENCY L P, et al. Towards understanding and mitigating social biases in language models[C]// International Conference on Machine Learning. PMLR, 2021: 6565-6576.
|
| [34] |
ALVI M, ZISSERMAN A, NELLÅKER C. Turning a blind eye: Explicit removal of biases and variation from deep neural network embeddings[C]// Proceedings of the European Conference on Computer Vision (ECCV) Workshops, 2018.
|
| [35] |
ZHANG J, VERMA V. Discover Discriminatory Bias in High Accuracy Models Embedded in Machine Learning Algorithms[C]// The International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery. Cham: Springer International Publishing, 2020: 1537-1545.
|
| [36] |
HAJIKHANI A, COLE C. A critical review of large language models: Sensitivity, bias, and the path toward specialized ai[J]. Quantitative Science Studies, 2024: 1-22.
|
| [37] |
GARTLEHNER G, KAHWATI L, HILSCHER R, et al. Data extraction for evidence synthesis using a large language model: A proof-of-concept study[J]. Research Synthesis Methods, 2024.
|
| [38] |
BELTAGY I, LO K, COHAN A. SciBERT: A pretrained language model for scientific text[J]. arXiv preprint arXiv:1903.10676, 2019.
|
| [39] |
LEWIS P, OTT M, DU J, et al. Pretrained language models for biomedical and clinical tasks: understanding and extending the state-of-the-art[C]// Proceedings of the 3rd clinical natural language processing workshop, 2020: 146-157.
|
| [40] |
LIN Z. How to write effective prompts for large language models[J]. Nature Human Behaviour, 2024: 1-5.
|
| [41] |
LIU P, YUAN W, FU J, et al. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing[J]. ACM Computing Surveys, 2023, 55(9): 1-35.
|
| [42] |
DeepSeek-AI. DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model[J]. arxiv preprint arxiv:2405.04434, 2024.
|
| [43] |
DAI D, DENG C, ZHAO C, et al. Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models[J]. arxiv preprint arxiv:2401. 06066, 2024.
|
| [44] |
AINSLIE J, LEE-THORP J, DE JONG M, et al. Gqa: Training generalized multi-query transformer models from multi-head checkpoints[J]. arxiv preprint arxiv:2305.13245, 2023.
|
| [45] |
SHAZEER N. Fast transformer decoding: One write-head is all you need[J]. arxiv preprint arxiv:1911.021 50, 2019.
|
 ),陈彦清3,王秀东4,5,*(
),陈彦清3,王秀东4,5,*(