数据与计算发展前沿 ›› 2024, Vol. 6 ›› Issue (4): 59-76.
CSTR: 32002.14.jfdc.CN10-1649/TP.2024.04.005
doi: 10.11871/jfdc.issn.2096-742X.2024.04.005
• 专刊:面向国家科学数据中心的基础软件栈及系统 • 上一篇 下一篇
蔡佳威1,2( ),胡川1,2,王华进1,2,沈志宏1,2,*()
),胡川1,2,王华进1,2,沈志宏1,2,*()
收稿日期:2024-01-15
出版日期:2024-08-20
发布日期:2024-08-20
通讯作者:
*沈志宏(E-mail: 作者简介:蔡佳威,中国科学院计算机网络信息中心,中国科学院大学,硕士研究生,主要研究方向为图数据库、数据管理。基金资助:
CAI Jiawei1,2(),HU Chuan1,2,WANG Huajin1,2,SHEN Zhihong1,2,*()
Received:2024-01-15
Online:2024-08-20
Published:2024-08-20
摘要:
【背景】 在过去的二十年里,DNA测序技术持续发展,海量生物序列数据的产生给数据存储、管理和传输带来了严峻的挑战。【目的】 本文主要总结近十五年基于参考的基因序列压缩算法,以寻求加速生物数据共享和降低存储成本的方法。【方法】 本文从算法的发展角度出发,按照不同算法所使用的关键技术和针对压缩优化的方案进行分类。通过实验验证当前主流算法的性能,揭示当前基于参考的压缩算法所存在的问题。提出一些值得探讨的研究方向,并对未来的研究方向进行了展望。【结果】 本文分析了已有基于参考的基因序列压缩算法使用的技术,包括基于单核苷酸多态性、检测最大精确匹配、分段/分块处理和基于LZ77等技术。并对几种较著名的算法进行了复现,发现这些算法倾向于在基准数据集上表现出高压缩比,但在普通数据集上的压缩比普遍不高。【结论】 目前已有的基于参考的基因序列压缩算法在理论上可以加速数据传输效率、节约存储成本,但是实用性存疑。须继续改进公共子序列匹配方式以提升对普通数据集的支持,增加预处理参考序列步骤以降低匹配时间开销。
蔡佳威, 胡川, 王华进, 沈志宏. 基于参考的基因序列压缩算法综述[J]. 数据与计算发展前沿, 2024, 6(4): 59-76.
CAI Jiawei, HU Chuan, WANG Huajin, SHEN Zhihong. A Survey on Gene Sequence Compression Algorithms Based on Reference Sequences[J]. Frontiers of Data and Computing, 2024, 6(4): 59-76, https://cstr.cn/32002.14.jfdc.CN10-1649/TP.2024.04.005.
表1
DNA序列中核苷酸字符种类"
| 核苷酸 | 字符 | 核苷酸 | 字符 |
|---|---|---|---|
| A | Adenine/腺嘌呤 | K | T,U,或G |
| C | Cytosine/胞嘧啶 | W | T,U,或A |
| G | Guanine/鸟嘌呤 | S | C或G |
| T | Thymine/胸腺嘧啶 | B | C,T,U,或G(非A) |
| U | Uracil/尿嘧啶 | D | A,T,U,或G(非 C) |
| R | Purine/嘌呤(A或G) | H | A,T,U,或C(非 G) |
| Y | Pyrimidine/嘌呤(C,T,或U) | V | A,C,或G(非T, 非U) |
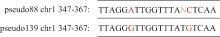
图1
SNP示例,图中红色碱基为SNP,绿色碱基为不确定的碱基,以IUPAC符号为标准"

图2
存档号为SRR1145747的部分数据"


图3
TAIR9的第一条染色体chr1的部分数据"

表2
基于SNP的基因压缩算法"
| 算法名称 | 发表年份 | 压缩效果 |
|---|---|---|
| DNAzip[ | 2009 | 在JW基因组上的压缩比为750 |
| Brandon等人[ | 2009 | 在人类线粒体序列上的压缩比为433 |
| GenomeZip[ | 2013 | 在JW基因组上的压缩比为1,250 |
表3
LZ77式压缩算法"
| 算法名称 | 发表年份 | 压缩效果 |
|---|---|---|
| RLZ[ | 2010 | 在人类基因组上的压缩比为109.7 |
| RLZ-opt[ | 2011 | 在人类基因组上的压缩比为189.6 |
| GDC[ | 2011 | 在69个人类基因组上的压缩比为1,000 |
| FRESCO[ | 2013 | 在人类基因组上的压缩比为4,000 |
| GDC 2[ | 2015 | 在1092个人类基因组上的压缩比为9,500 |
| MBGC[ | 2022 | 在168311个细菌基因组上的压缩比为1,265 |
表4
基于快速检测MEM的压缩算法"
| 算法名称 | 发表年份 | 压缩效果 |
|---|---|---|
| HiRGC[ | 2017 | 8个人类基因组上的压缩比为82-217 |
| SCCG[ | 2018 | 8个人类基因组上的压缩比为90.16-253.57 |
| memRGC[ | 2020 | 在200个1000基因项目的基因组上的压缩比为1,907 |
表5
基于分段/分块的算法"
| 算法名称 | 发表年份 | 压缩效果 |
|---|---|---|
| GRS[ | 2011 | 以KOREF_20090131为参考压缩KOREF_20090224时压缩比为158.9 |
| Block Compression[ | 2012 | 在人类基因组上的压缩比为400 |
| ERGC[ | 2015 | 在5个人类基因组上的压缩比为6.80-491 |
| NRGC[ | 2016 | 在5个人类基因组上的压缩比为63.8-397 |
表6
其他算法"
| 算法名称 | 发表 年份 | 压缩效果 |
|---|---|---|
| GReEn[ | 2012 | 以KOREF_20090131为参考压缩KOREF_20090224时压缩比为171.4 |
| iDoComp[ | 2015 | 以拟南芥TAIR9为参考压缩TAIR10时的压缩比为59,382 |
| CoGI[ | 2015 | 以KOREF 20090224为参考压缩YH时的压缩比为244.42 |
| HRCM[ | 2019 | 在1000项目中所有人类基因组上的压缩比为1,857 |
| HADC[ | 2022 | 以TAIR9为参考压缩TAIR10时的压缩比为83,790 |
| LMSRGC[ | 2023 | 在8个人类基因组上的压缩比在100-430 |
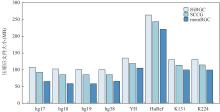
图4
八个人类基因的压缩结果(MB)"

图5
八个人类基因的压缩时间(秒)"

表7
中小型基因的压缩比"
| ref | tar | 算法 | ||
|---|---|---|---|---|
| HiRGC | SCCG | memRGC | ||
| ce6 | ce10 | 425.73 | 425.08 | 12471.21 |
| ce11 | 415.83 | 415.95 | 611.43 | |
| ce10 | ce6 | 422.40 | 423.32 | 14689.67 |
| ce11 | 416.23 | 417.18 | 629.18 | |
| ce11 | ce6 | 494.97 | 497.01 | 616.38 |
| ce10 | 499.92 | 501.13 | 629.06 | |
| TAIR8 | TAIR9 | 34603.17 | 47527.25 | 43668.95 |
| TAIR10 | 34603.17 | 47337.14 | 43668.95 | |
| TAIR9 | TAIR8 | 34614.78 | 10267.35 | 42279.48 |
| TAIR10 | 81615.76 | 275215.94 | 563537.40 | |
| TAIR10 | TAIR8 | 34716.29 | 10267.35 | 42279.48 |
| TAIR9 | 81056.75 | 275215.94 | 537922.06 | |
| sacCer2 | sacCer3 | 4234.18 | 4419.62 | 4824.60 |
| sacCer3 | sacCer2 | 4063.53 | 4234.03 | 5045.55 |
表8
中小型基因的压缩时间比较(秒)"
| ref | tar | 算法 | ||
|---|---|---|---|---|
| HiRGC | SCCG | memRGC | ||
| ce6 | ce10 | 14.05 | 23.40 | 6.64 |
| ce11 | 14.83 | 23.50 | 7.46 | |
| ce10 | ce6 | 14.30 | 23.36 | 7.29 |
| ce11 | 14.12 | 23.53 | 7.17 | |
| ce11 | ce6 | 14.03 | 23.31 | 7.76 |
| ce10 | 13.68 | 23.14 | 7.34 | |
| 平均压缩时间 | 14.17 | 23.37 | 7.28 | |
| TAIR8 | TAIR9 | 14.33 | 23.17 | 6.76 |
| TAIR10 | 14.25 | 23.42 | 6.72 | |
| TAIR9 | TAIR8 | 13.94 | 23.54 | 7.38 |
| TAIR10 | 13.64 | 23.59 | 0.36 | |
| TAIR10 | TAIR8 | 15.53 | 23.57 | 7.51 |
| TAIR9 | 14.32 | 23.50 | 0.36 | |
| 平均压缩时间 | 14.33 | 23.46 | 4.85 | |
| sacCer2 | sacCer3 | 15.68 | 5.34 | 1.58 |
| sacCer3 | sacCer2 | 15.83 | 5.37 | 1.58 |
| 平均压缩时间 | 15.76 | 5.36 | 1.58 | |
表9
实验三压缩比"
| ref | tar | 算法 | ||
|---|---|---|---|---|
| HiRGC | SCCG | memRGC | ||
| TAIR8 | pseudo88 | 11.07 | 11.01 | 22.82 |
| pseudo108 | 14.75 | 14.74 | 31.74 | |
| pseudo139 | 12.95 | 12.91 | 27.77 | |
| pseudo159 | 13.47 | 13.44 | 29.29 | |
| pseudo265 | 14.69 | 14.67 | 31.64 | |
| pseudo350 | 13.95 | 13.92 | 30.17 | |
| pseudo351 | 15.19 | 15.19 | 32.84 | |
| pseudo403 | 13.94 | 13.91 | 30.31 | |
| pseudo410 | 12.62 | 12.58 | 26.84 | |
| pseudo424 | 13.20 | 13.17 | 28.65 | |
表10
压缩时间(秒)"
| ref | tar | 算法 | ||
|---|---|---|---|---|
| HiRGC | SCCG | memRGC | ||
| TAIR8 | pseudo88 | 19.72 | 43.06 | 189.07 |
| pseudo108 | 20.25 | 48.89 | 162.37 | |
| pseudo139 | 19.41 | 47.50 | 175.98 | |
| pseudo159 | 19.56 | 46.39 | 170.83 | |
| pseudo265 | 18.57 | 48.19 | 162.36 | |
| pseudo350 | 20.42 | 48.03 | 167.36 | |
| pseudo351 | 18.03 | 46.91 | 159.61 | |
| pseudo403 | 19.45 | 46.49 | 166.99 | |
| pseudo410 | 20.39 | 44.94 | 178.33 | |
| pseudo424 | 18.58 | 46.02 | 172.69 | |
| 平均压缩时间 | 19.44 | 46.64 | 170.56 | |
| [1] | LANDER E S. Initial impact of the sequencing of the human genome[J]. Nature, 2011, 470(7333): 187-197. |
| [2] |
GOODWIN S, MCPHERSON J D, MCCOMBIE W R. Coming of age: ten years of next-generation sequencing technologies[J]. Nature Reviews Genetics, 2016, 17(6): 333-351.
doi: 10.1038/nrg.2016.49 pmid: 27184599 |
| [3] | O'LEARY N A, WRIGHT M W, BRISTER J R, et al. Reference sequence (RefSeq) database at NCBI: current status, taxonomic expansion, and functional annotation[J]. Nucleic acids research, 2016, 44(D1): D733-D745. |
| [4] |
CHEN X, LI M, MA B, et al. DNACompress: fast and effective DNA sequence compression[J]. Bioinformatics, 2002, 18(12): 1696-1698.
pmid: 12490460 |
| [5] | MATOS L M O, PRATAS D, PINHO A J. A compression model for DNA multiple sequence alignment blocks[J]. IEEE transactions on information theory, 2013, 59(5): 3189-3198. |
| [6] |
HAYASHIDA M, RUAN P, AKUTSU T. Proteome compression via protein domain compositions[J]. Methods, 2014, 67(3): 380-385.
doi: 10.1016/j.ymeth.2014.01.012 pmid: 24486717 |
| [7] | HERNAEZ M, PAVLICHIN D, WEISSMAN T, et al. Genomic data compression[J]. Annual Review of Biomedical Data Science, 2019, 2: 19-37. |
| [8] | GRUMBACH S, TAHI F. Compression of DNA sequences[C]// [Proceedings] DCC93:Data Compression Conference, 1993: 340-350. |
| [9] | 朱泽轩, 张永朋, 尤著宏, 等. 高通量 DNA 测序数据压缩研究进展[J]. 深圳大学学报(理工版), 2013, 30(4): 409-415. |
| [10] | BHOLA V, BOPARDIKAR A S, NARAYANAN R, et al. No-reference compression of genomic data stored in fastq format[C]// 2011 IEEE International Conference on Bioinformatics and Biomedicine, 2011: 147-150. |
| [11] | CHEN L, LU S, RAM J. Compressed pattern matching in dna sequences[C]// Proceedings. 2004 IEEE Computational Systems Bioinformatics Conference, 2004. CSB 2004. IEEE, 2004: 62-68. |
| [12] | WANDELT S, BUX M, LESER U. Trends in genome compression[J]. Current Bioinformatics, 2014, 9(3): 315-326. |
| [13] | ANTONIOU D, THEODORIDIS E, TSAKALIDIS A. Compressing biological sequences using self adjusting data structures[C]. In 10th IEEE International Conference on Information Technology and Applications in Biomedicine, 2010:1-5. |
| [14] | CHERN B G, OCHOA I, MANOLAKOS A, et al. Reference based genome compression[C]// 2012 IEEE Information Theory Workshop, 2012: 427-431. |
| [15] | PRATAS D, HOSSEINI M, PINHO A J. Substitutional tolerant Markov models for relative compression of DNA sequences[C]// 11th International Conference on Practical Applications of Computational Biology & Bioinformatics, Springer International Publishing, 2017: 265-272. |
| [16] |
MEISER L C, NGUYEN B H, CHEN Y J, et al. Synthetic DNA applications in information technology[J]. Nature communications, 2022, 13(1): 352.
doi: 10.1038/s41467-021-27846-9 pmid: 35039502 |
| [17] |
NURK S, KOREN S, RHIE A, et al. The complete sequence of a human genome[J]. Science, 2022, 376(6588): 44-53.
doi: 10.1126/science.abj6987 pmid: 35357919 |
| [18] | INTERNATIONAL HUMAN GENOME SEQUENCING CONSORTIUM. Initial sequencing and analysis of the human genome[J]. Nature, 2001, 409(6822): 860-921. |
| [19] | FUJITA P A, RHEAD B, ZWEIG A S, et al. The UCSC genome browser database: update 2011[J]. Nucleic acids research, 2010, 39(suppl_1): D876-D882. |
| [20] | PRATAS D, PINHO A J. JARVIS2: a data compressor for large genome sequences[C]. 2023 Data Compression Conference, 2023: 288-297. |
| [21] | DEOROWICZ S, DANEK A, NIEMIEC M. GDC 2: Compression of large collections of genomes[J]. Scientific reports, 2015, 5(1): 11565. |
| [22] | WATSON J D, CRICK F H C. The structure of DNA[C]. Cold Spring Harbor Laboratory Press, 1953, 18: 123-131. |
| [23] |
JOHNSON A D. An extended IUPAC nomenclature code for polymorphic nucleic acids[J]. Bioinformatics, 2010, 26(10): 1386-1389.
doi: 10.1093/bioinformatics/btq098 pmid: 20202974 |
| [24] |
KIM S, MISRA A. SNP genotyping: technologies and biomedical applications[J]. Annu. Rev. Biomed. Eng., 2007, 9: 289-320.
pmid: 17391067 |
| [25] |
FRIDLEY B L, BIERNACKA J M. Gene set analysis of SNP data: benefits, challenges, and future directions[J]. European Journal of Human Genetics, 2011, 19(8): 837-843.
doi: 10.1038/ejhg.2011.57 pmid: 21487444 |
| [26] |
ROSSI M, OLIVA M, LANGMEAD B, et al. MONI: a pangenomic index for finding maximal exact matches[J]. Journal of Computational Biology, 2022, 29(2): 169-187.
doi: 10.1089/cmb.2021.0290 pmid: 35041495 |
| [27] | BINZ P A, SHOFSTAHL J, VIZCAÍNO J A, et al. Proteomics standards initiative extended FASTA format[J]. Journal of proteome research, 2019, 18(6): 2686-2692. |
| [28] | ROBINSON P N, PIRO R M, JAGER M. Computational exome and genome analysis[M]. CRC Press, 2017: 57-59. |
| [29] | LIU Y, SHEN X, GONG Y, et al. Sequence Alignment/Map format: a comprehensive review of approaches and applications[J]. Briefings in Bioinformatics, 2023, 24(5): bbad320. |
| [30] |
DANECEK P, AUTON A, ABECASIS G, et al. The variant call format and VCFtools[J]. Bioinformatics, 2011, 27(15): 2156-2158.
doi: 10.1093/bioinformatics/btr330 pmid: 21653522 |
| [31] |
EWING B, HILLIER L D, WENDL M C, et al. Base-calling of automated sequencer traces using Phred. I. Accuracy assessment[J]. Genome research, 1998, 8(3): 175-185.
doi: 10.1101/gr.8.3.175 pmid: 9521921 |
| [32] |
EWING B, GREEN P. Base-calling of automated sequencer traces using phred. II. Error probabilities[J]. Genome research, 1998, 8(3): 186-194.
pmid: 9521922 |
| [33] | SMITH A D, XUAN Z, ZHANG M Q. Using quality scores and longer reads improves accuracy of Solexa read mapping[J]. BMC bioinformatics, 2008, 9(1): 1-8. |
| [34] | COX M P, PETERSON D A, BIGGS P J. SolexaQA: At-a-glance quality assessment of Illumina second-generation sequencing data[J]. BMC bioinformatics, 2010, 11(1): 1-6. |
| [35] | CHEN S. Ultrafast one-pass FASTQ data preprocessing, quality control, and deduplication using fastp[J]. iMeta, 2023: e107. |
| [36] |
DEOROWICZ S, GRABOWSKI S. Compression of DNA sequence reads in FASTQ format[J]. Bioinformatics, 2011, 27(6): 860-862.
doi: 10.1093/bioinformatics/btr014 pmid: 21252073 |
| [37] | QUAIL M A, KOZAREWA I, SMITH F, et al. A large genome center’s improvements to the Illumina sequencing system[J]. Nature methods, 2008, 5(12): 1005-1010. |
| [38] | PEARSON W R, LIPMAN D J. Improved tools for biological sequence comparison[J]. Proceedings of the National Academy of Sciences, 1988, 85(8): 2444-2448. |
| [39] | BINZ P A, SHOFSTAHL J, VIZCAÍNO J A, et al. Proteomics standards initiative extended FASTA format[J]. Journal of proteome research, 2019, 18(6): 2686-2692. |
| [40] | SHENDURE J, BALASUBRAMANIAN S, CHURCH G M, et al. DNA sequencing at 40: past, present and future[J]. Nature, 2017, 550(7676): 345-353. |
| [41] | 1000 GENOMES PROJECT CONSORTIUM. An integrated map of genetic variation from 1,092 human genomes[J]. Nature, 2012, 491(7422): 56. |
| [42] | THE UK10K CONSORTIUM. The UK10K project identifies rare variants in health and disease. Nature, 2015, 526(7571): 82-90. |
| [43] | BALL M P, THAKURIA J V, ZARANEK A W, et al. A public resource facilitating clinical use of genomes[J]. Proceedings of the National Academy of Sciences, 2012, 109(30): 11920-11927. |
| [44] |
GAZIANO J M, CONCATO J, BROPHY M, et al. Million Veteran Program: A mega-biobank to study genetic influences on health and disease[J]. Journal of clinical epidemiology, 2016, 70: 214-223.
doi: 10.1016/j.jclinepi.2015.09.016 pmid: 26441289 |
| [45] | WEIGEL D, MOTT R. The 1001 genomes project for Arabidopsis thaliana[J]. Genome biology, 2009, 10(5): 1-5. |
| [46] | CHENG S, MELKONIAN M, SMITH S A, et al. 10KP: A phylodiverse genome sequencing plan[J]. Gigascience, 2018, 7(3): giy013. |
| [47] | LEWIN H A, ROBINSON G E, KRESS W J, et al. Earth BioGenome Project: Sequencing life for the future of life[J]. Proceedings of the National Academy of Sciences, 2018, 115(17): 4325-4333. |
| [48] |
CHRISTLEY S, LU Y, LI C, et al. Human genomes as email attachments[J]. Bioinformatics, 2009, 25(2): 274-275.
doi: 10.1093/bioinformatics/btn582 pmid: 18996942 |
| [49] |
BRANDON M C, WALLACE D C, BALDI P. Data structures and compression algorithms for genomic sequence data[J]. Bioinformatics, 2009, 25(14): 1731-1738.
doi: 10.1093/bioinformatics/btp319 pmid: 19447783 |
| [50] |
PAVLICHIN D S, WEISSMAN T, YONA G. The human genome contracts again[J]. Bioinformatics, 2013, 29(17): 2199-2202.
doi: 10.1093/bioinformatics/btt362 pmid: 23793748 |
| [51] | HUFFMAN D A. A method for the construction of minimum-redundancy codes[J]. Proceedings of the IRE, 1952, 40(9): 1098-1101. |
| [52] | WHEELER D A, SRINIVASAN M, EGHOLM M, et al. The complete genome of an individual by massively parallel DNA sequencing[J]. nature, 2008, 452(7189): 872-876. |
| [53] | GOEL M, SUN H, JIAO W B, et al. SyRI: finding genomic rearrangements and local sequence differences from whole-genome assemblies[J]. Genome biology, 2019, 20(1): 1-13. |
| [54] | NIK-ZAINAL S, DAVIES H, STAAF J, et al. Landscape of somatic mutations in 560 breast cancer whole-genome sequences[J]. Nature, 2016, 534(7605): 47-54. |
| [55] | ZIV J, LEMPEL A. A universal algorithm for sequential data compression[J]. IEEE Transactions on information theory, 1977, 23(3): 337-343. |
| [56] |
MÄKINEN V, NAVARRO G, SIRÉN J, et al. Storage and retrieval of highly repetitive sequence collections[J]. Journal of Computational Biology, 2010, 17(3): 281-308.
doi: 10.1089/cmb.2009.0169 pmid: 20377446 |
| [57] | KURUPPU S, PUGLISI S J, ZOBEL J. Relative Lempel-Ziv compression of genomes for large-scale storage and retrieval[C]// International Symposium on String Processing and Information Retrieval, Berlin, Heidelberg: Springer Berlin Heidelberg, 2010: 201-206. |
| [58] | GILMARY R, VENKATESAN A, VAIYAPURI G. Compression Techniques for DNA Sequences: A Thematic Review[J]. J. Comput. Sci. Eng., 2021, 15(2): 59-71. |
| [59] | KURUPPU S, PUGLISI S J, ZOBEL J. Optimized relative Lempel-Ziv compression of genomes[C]// Proceedings of the Thirty-Fourth Australasian Computer Science Conference-Volume 113, 2011: 91-98. |
| [60] | MANZINI G, RASTERO M. A simple and fast DNA compressor[J]. Software: Practice and Experience, 2004, 34(14): 1397-1411. |
| [61] | GOLOMB S. Run-length encodings (corresp.)[J]. IEEE transactions on information theory, 1966, 12(3): 399-401. |
| [62] |
DEOROWICZ S, GRABOWSKI S. Robust relative compression of genomes with random access[J]. Bioinformatics, 2011, 27(21): 2979-2986.
doi: 10.1093/bioinformatics/btr505 pmid: 21896510 |
| [63] |
WANDELT S, LESER U. FRESCO: Referential compression of highly similar sequences[J]. IEEE/ACM Transactions on Computational Biology and Bioinformatics, 2013, 10(5): 1275-1288.
pmid: 24524158 |
| [64] | GRABOWSKI S, KOWALSKI T M. MBGC: multiple bacteria genome compressor[J]. GigaScience, 2022, 11: giab099. |
| [65] |
LIU Y, PENG H, WONG L, et al. High-speed and high-ratio referential genome compression[J]. Bioinformatics, 2017, 33(21): 3364-3372.
doi: 10.1093/bioinformatics/btx412 pmid: 28651329 |
| [66] |
SHI W, CHEN J, LUO M, et al. High efficiency referential genome compression algorithm[J]. Bioinformatics, 2019, 35(12): 2058-2065.
doi: 10.1093/bioinformatics/bty934 pmid: 30407493 |
| [67] |
LIU Y, WONG L, LI J. Allowing mutations in maximal matches boosts genome compression performance[J]. Bioinformatics, 2020, 36(18): 4675-4681.
doi: 10.1093/bioinformatics/btaa572 pmid: 33118018 |
| [68] | ROBINSON A H, CHERRY C. Results of a prototype television bandwidth compression scheme[J]. Proceedings of the IEEE, 1967, 55(3): 356-364. |
| [69] | HELD G, MARSHALL T R. Data compression: techniques and applications, hardware and software considerations[M]. John Wiley & Sons, Inc., 1987:45-47. |
| [70] | MOFFAT A. Implementing the PPM data compression scheme[J]. IEEE Transactions on communications, 1990, 38(11): 1917-1921. |
| [71] |
GRABOWSKI S, BIENIECKI W. copMEM: finding maximal exact matches via sampling both genomes[J]. Bioinformatics, 2019, 35(4): 677-678.
doi: 10.1093/bioinformatics/bty670 pmid: 30060142 |
| [72] |
LIU Y, ZHANG L Y, LI J. Fast detection of maximal exact matches via fixed sampling of query K-mers and Bloom filtering of index K-mers[J]. Bioinformatics, 2019, 35(22): 4560-4567.
doi: 10.1093/bioinformatics/btz273 pmid: 30994891 |
| [73] | BLOOM B H. Space/time trade-offs in hash coding with allowable errors[J]. Communications of the ACM, 1970, 13(7): 422-426. |
| [74] | 史伟. 基于参考的基因组序列数据压缩算法研究[D]. 云南大学, 2019. |
| [75] | 陈国良, 尧海昌, 陈帅, 等. 面向国产处理器大数据一体机的基因压缩技术研究[J]. 南京邮电大学学报(自然科学版), 2020, 40(05): 11-26. |
| [76] | WANG C, ZHANG D. A novel compression tool for efficient storage of genome resequencing data[J]. Nucleic acids research, 2011, 39(7): e45-e45. |
| [77] | WANDELT S, LESER U. Adaptive efficient compression of genomes[J]. Algorithms for Molecular Biology, 2012, 7(1): 1-9. |
| [78] |
SAHA S, RAJASEKARAN S. ERGC: an efficient referential genome compression algorithm[J]. Bioinformatics, 2015, 31(21): 3468-3475.
doi: 10.1093/bioinformatics/btv399 pmid: 26139636 |
| [79] |
SAHA S, RAJASEKARAN S. NRGC: a novel referential genome compression algorithm[J]. Bioinformatics, 2016, 32(22): 3405-3412.
pmid: 27485445 |
| [80] | LI G, MA L, SONG C, et al. The YH database: the first Asian diploid genome database[J]. Nucleic acids research, 2009, 37(suppl_1): D1025-D1028. |
| [81] | AHN S M, KIM T H, LEE S, et al. The first Korean genome sequence and analysis: full genome sequencing for a socio-ethnic group[J]. Genome research, 2009, 19(9): 1622-1629. |
| [82] | TAN H, ZHANG Z, ZOU X, et al. Exploring the potential of fast delta encoding: Marching to a higher compression ratio[C]// 2020 IEEE International Conference on Cluster Computing (CLUSTER), 2020: 198-208. |
| [83] |
XIE X, ZHOU S, GUAN J. CoGI: Towards compressing genomes as an image[J]. IEEE/ACM transactions on computational biology and bioinformatics, 2015, 12(6): 1275-1285.
doi: 10.1109/TCBB.2015.2430331 pmid: 26671800 |
| [84] | ELNADY S, SAYED S, SALAH A. HADC: A Hybrid Compression Approach for DNA Sequences[J]. IEEE Access, 2022, 10: 106841-106848. |
| [85] | PINHO A J, PRATAS D, GARCIA S P. GReEn: a tool for efficient compression of genome resequencing data[J]. Nucleic acids research, 2012, 40(4): e27-e27. |
| [86] | CAO M D, DIX T I, ALLISON L, et al. A simple statistical algorithm for biological sequence compression[C]// 2007 Data Compression Conference, 2007: 43-52. |
| [87] |
ZHU Z, ZHANG Y, JI Z, et al. High-throughput DNA sequence data compression[J]. Briefings in bioinformatics, 2015, 16(1): 1-15.
doi: 10.1093/bib/bbt087 pmid: 24300111 |
| [88] | OCHOA I, HERNAEZ M, WEISSMAN T. iDoComp: a compression scheme for assembled genomes[J]. Bioinformatics, 2014, 31(5): 626-633. |
| [89] | YAO H, JI Y, LI K, et al. HRCM: an efficient hybrid referential compression method for genomic big data[J/OL]. BioMed Research International, 2019,https://doi.org/10.1155/2019/3108950. |
| [90] |
LU Z, GUO L, CHEN J, et al. Reference-based genome compression using the longest matched substrings with parallelization consideration[J]. BMC bioinformatics, 2023, 24(1): 369.
doi: 10.1186/s12859-023-05500-z pmid: 37777730 |
| [91] | LEIMEISTER C A, MORGENSTERN B. Kmacs: the k-mismatch average common substring approach to alignment-free sequence comparison[J]. Bioinformatics, 2014, 30(14): 2000-2008. |
| [92] | BEAL R, AFRIN T, FARHEEN A, et al. A new algorithm for “the LCS problem” with application in compressing genome resequencing data[J]. BMC genomics, 2016, 17: 369-381. |
| [93] | 尧海昌. 大规模基因序列压缩及其并行化算法研究[D]. 南京邮电大学, 2021. |
| [94] |
XING J, ZHANG Y, HAN K, et al. Mobile elements create structural variation: analysis of a complete human genome[J]. Genome research, 2009, 19(9): 1516-1526.
doi: 10.1101/gr.091827.109 pmid: 19439515 |
| [95] | BÜREN F, JÜNGER D, KOBUS R, et al. Suffix Array Construction on Multi-GPU Systems[C]// Proceedings of the 28th International Symposium on High-Performance Parallel and Distributed Computing, 2019: 183-194. |
| [96] | STEPHENS Z D, LEE S Y, FAGHRI F, et al. Big data: astronomical or genomical?[J]. PLoS biology, 2015, 13(7): e1002195. |
| [97] | TUO S, LI C, LIU F, et al. MTHSA-DHEI: multitasking harmony search algorithm for detecting high-order SNP epistatic interactions[J]. Complex & Intelligent Systems, 2023, 9(1): 637-658. |
| [98] | ZHA D, FENG L, LUO L, et al. Pre-train and Search: Efficient Embedding Table Sharding with Pre-trained Neural Cost Models[J]. Proceedings of Machine Learning and Systems, 2023, 5: 68-88. |
| [99] | SILVA M, PRATAS D, PINHO A J. Efficient DNA sequence compression with neural networks[J]. GigaScience, 2020, 9(11): giaa119. |
| [100] |
YU Y, SI X, HU C, et al. A review of recurrent neural networks: LSTM cells and network architectures[J]. Neural computation, 2019, 31(7): 1235-1270.
doi: 10.1162/neco_a_01199 pmid: 31113301 |
| [101] | TIMÓN-REINA S, RINCÓN M, MARTÍNEZ-TOMÁS R. An overview of graph databases and their applications in the biomedical domain[J]. Database, 2021, 2021: baab026. |
| No related articles found! |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||