Frontiers of Data and Computing ›› 2025, Vol. 7 ›› Issue (6): 124-135.
CSTR: 32002.14.jfdc.CN10-1649/TP.2025.06.012
doi: 10.11871/jfdc.issn.2096-742X.2025.06.012
• Technology and Application • Previous Articles Next Articles
DU Zhenpeng1,*( ),XU Jianliang1,ZHANG Xianyi2,HUANG Qiang2
),XU Jianliang1,ZHANG Xianyi2,HUANG Qiang2
Received:2025-03-27
Online:2025-12-20
Published:2025-12-17
Contact:
DU Zhenpeng
E-mail:dzp@stu.ouc.edu.cn
DU Zhenpeng,XU Jianliang,ZHANG Xianyi,HUANG Qiang. Implementation and Optimization of High-Performance FFT Algorithm Library Based on GPU[J]. Frontiers of Data and Computing, 2025, 7(6): 124-135, https://cstr.cn/32002.14.jfdc.CN10-1649/TP.2025.06.012.
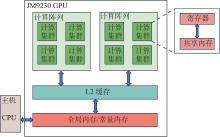
Fig.1
JM9230 GPU architecture"
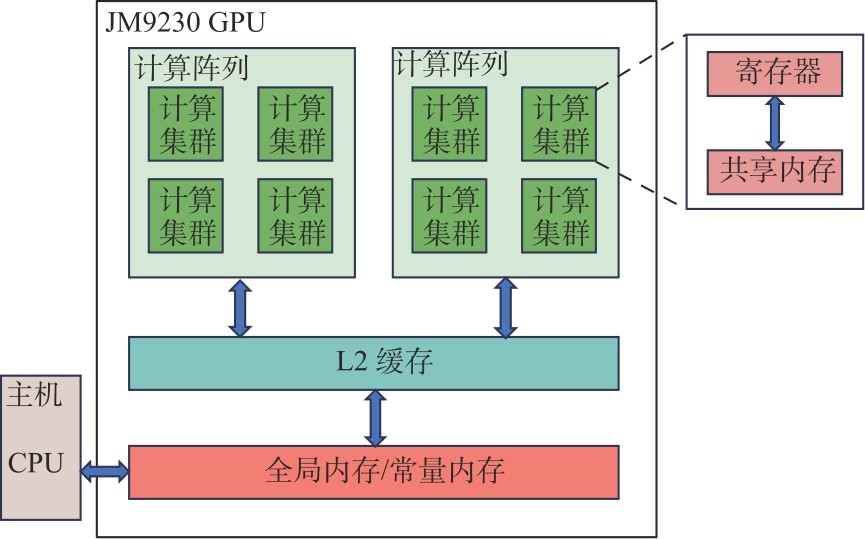
Table.1
Characteristics of radix-2, radix-4, radix-16"
| 基 | 阶段 数目 | 同步 次数 | 计算 粒度 | 连续内存 访问长度 | 寄存器 个数 |
|---|---|---|---|---|---|
| 2 | 8 | 8 | 小 | 1024Bytes | 4 |
| 4 | 4 | 4 | 大 | 512Bytes | 8 |
| 16 | 2 | 1 | 大 | 128Bytes | 32 |
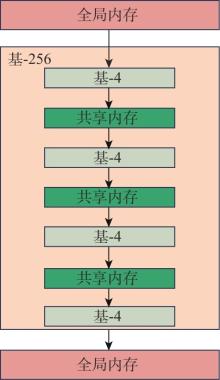
Fig.2
Data stream of the Radix-256"
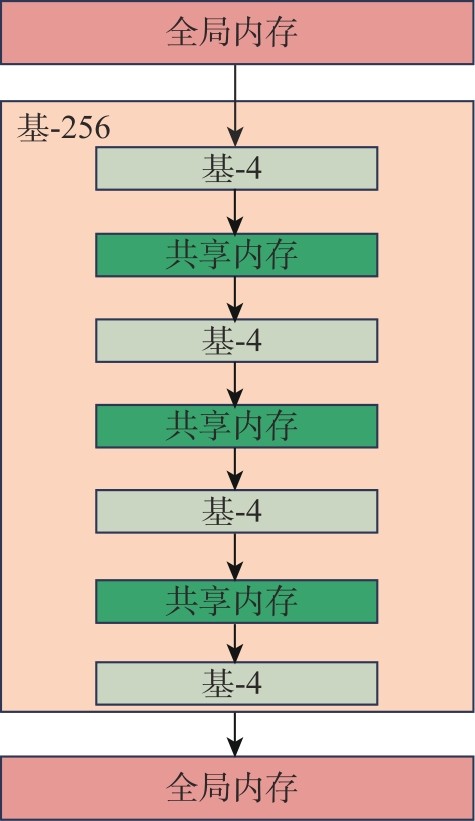

Fig.3
Traditional butterfly network"
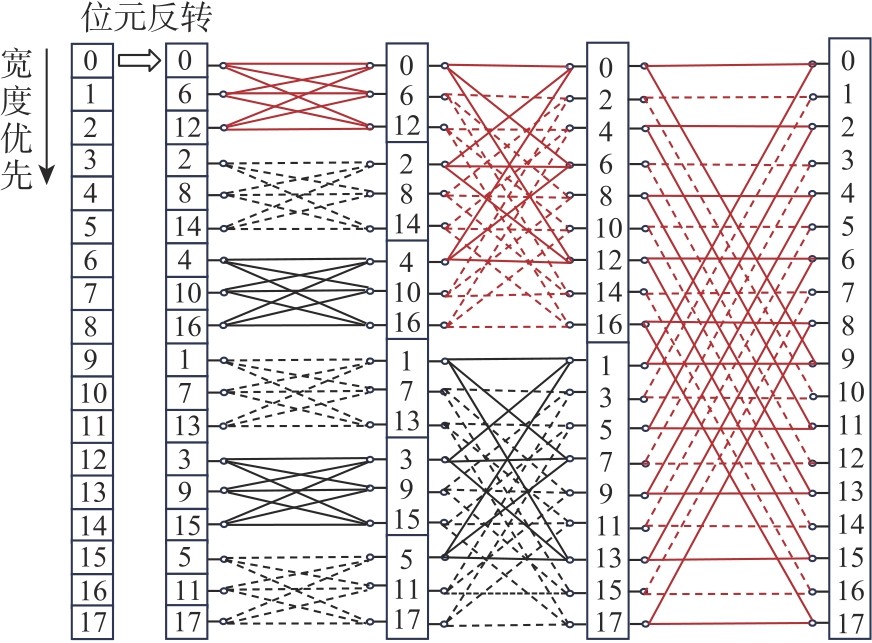
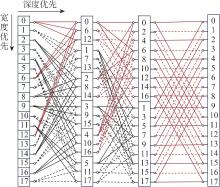
Fig.4
New butterfly network"
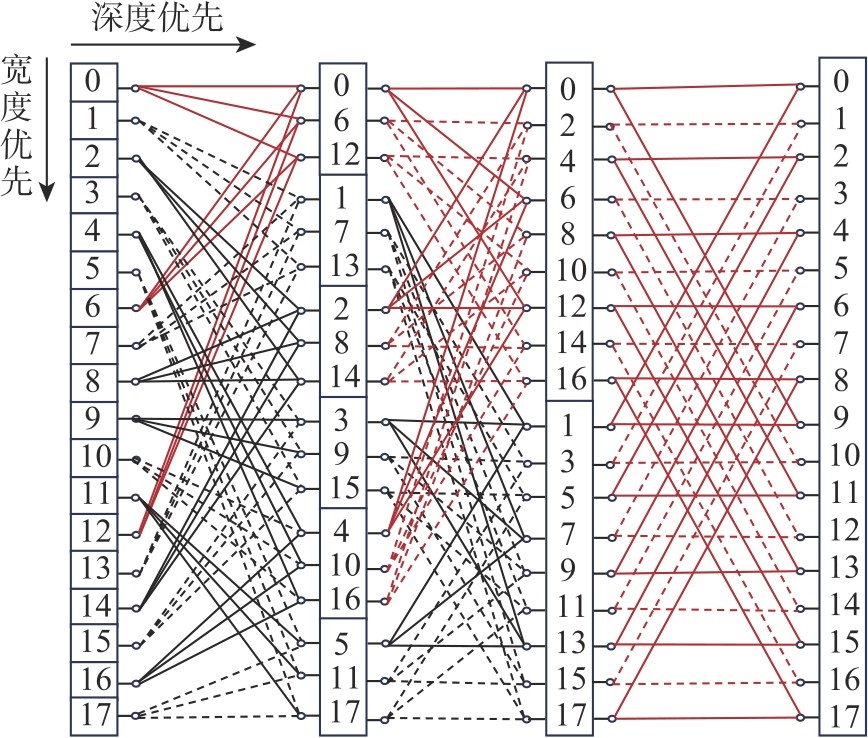
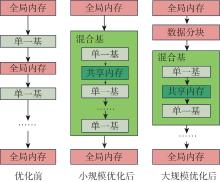
Fig.5
New butterfly network"
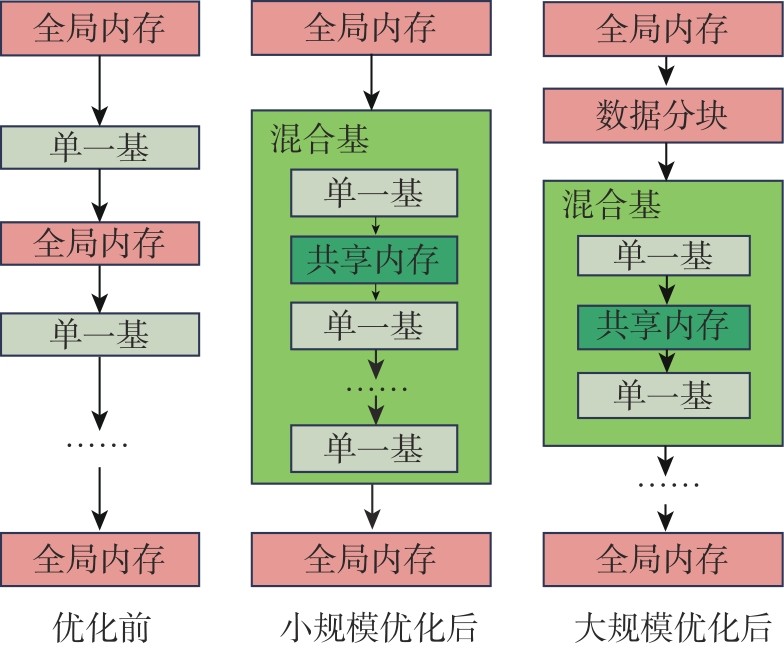
Table 2
Experimental environment"
| Hardware | Configuration |
|---|---|
| CPU | Phytium FT-2000/4@2.6 GHz |
| GPU | 景嘉微JM9230@1500 MHz |
| 显存 | 4 GB |
| 共享内存 | 32 KB |
| OpenCL | 3.0 |
| GCC | 13.1.0 |
| clFFT | 2.0 |
| FFTW | 3.3.10 |
Table 3
The comparison of average computation time for radix-256"
| 批次 | clFFT(ms) | PerfFFT(ms) | 加速比 |
|---|---|---|---|
| 1 | 1.14123 | 0.90912 | 1.2553 |
| 2 | 1.13740 | 0.91310 | 1.2456 |
| 4 | 1.14535 | 1.00106 | 1.1441 |
| 8 | 1.15764 | 0.82594 | 1.4016 |
| 16 | 1.12110 | 0.93636 | 1.1973 |
| 32 | 1.14706 | 0.94248 | 1.2171 |
| 64 | 1.02652 | 0.74627 | 1.3755 |
| 128 | 1.01930 | 0.82706 | 1.2324 |
| 256 | 1.02703 | 0.98815 | 1.0393 |
| 512 | 1.03991 | 0.56443 | 1.8424 |
| 1,024 | 1.04316 | 0.92120 | 1.1324 |
| 2,048 | 1.12110 | 1.07124 | 1.0465 |
| 4,096 | 1.46160 | 0.95479 | 1.5308 |
| 8,192 | 2.63448 | 1.28138 | 2.0560 |
| 16,384 | 5.11076 | 2.28341 | 2.2382 |
Table 4
FFT running time table on CPU and GPU"
| 规模 | GPU PerfFFT(ms) | CPU FFTW(ms) | 加速比 |
|---|---|---|---|
| 256 | 0.6377 | 0.0669 | 0.1049 |
| 512 | 0.4908 | 0.1091 | 0.2224 |
| 1,024 | 0.6640 | 0.2361 | 0.3556 |
| 2,048 | 1.1347 | 0.5426 | 0.4782 |
| 4,096 | 1.9746 | 2.2921 | 1.1608 |
| 8,192 | 3.1945 | 6.8923 | 2.1575 |
| 16,384 | 5.7951 | 17.2347 | 2.9740 |
| 32,768 | 13.3553 | 36.5582 | 2.7373 |
| 65,536 | 27.8472 | 83.0932 | 2.9839 |
| 131,072 | 85.4049 | 181.1213 | 2.1207 |
| 262,144 | 184.8835 | 664.8009 | 3.5957 |
| 524,288 | 376.7236 | 1,816.3510 | 4.8214 |
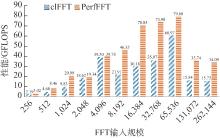
Fig.6
The performance graph of powers of 2 (batch: 128)"
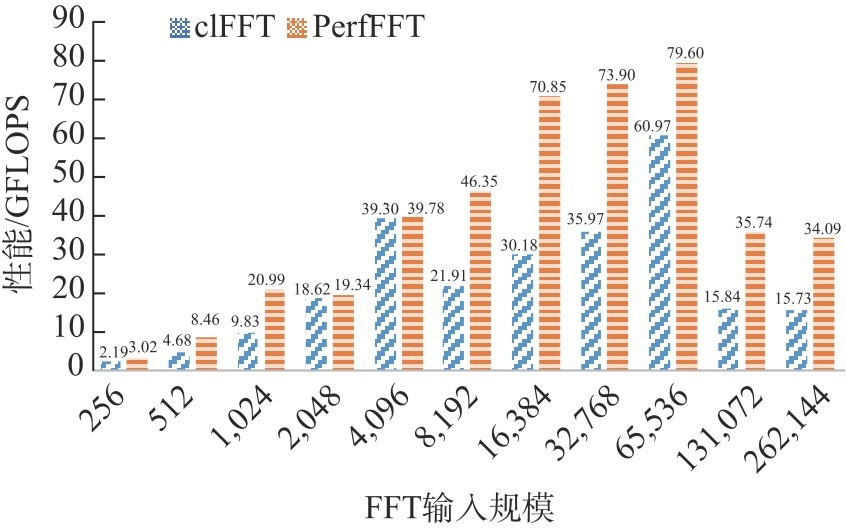
Fig.7
The performance graph of powers of 2 (batch: 256)"
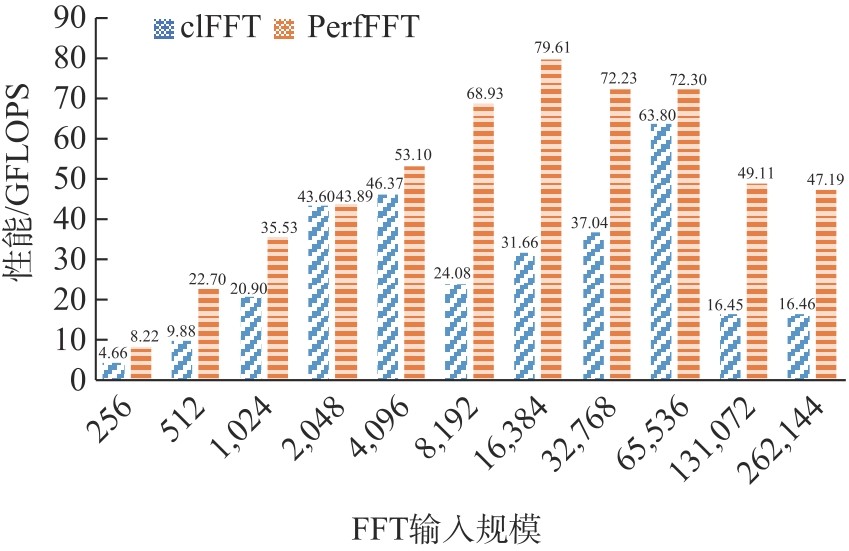

Fig.8
The Performance chart of non-powers of 2 (batch: 128)"
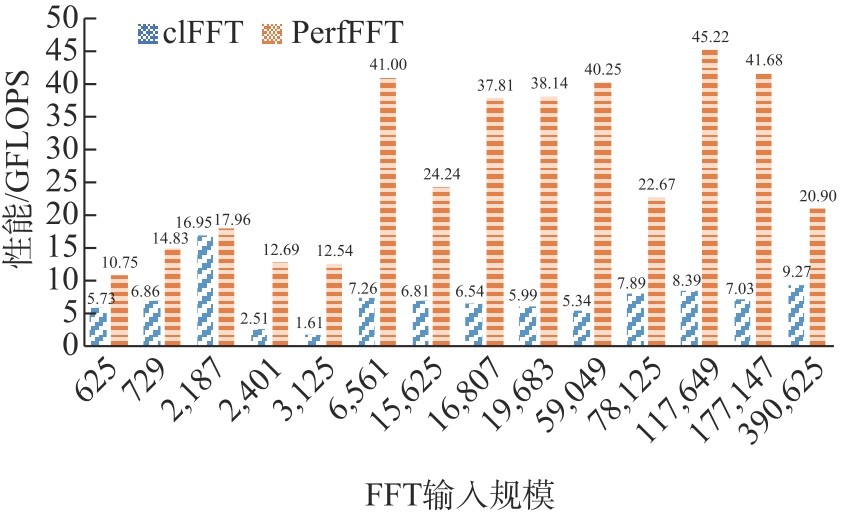
Fig.9
The Performance chart of non-powers of 2 (batch: 256)"
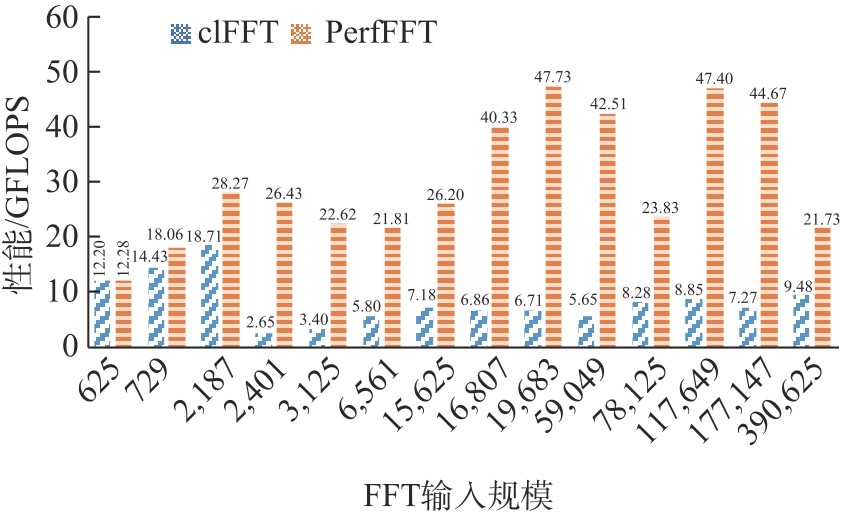
Table 5
Performance comparison of FFT across different batches"
| 规模 | 批次:128 (GFLOPS) | 批次:256 (GFLOPS) | 批次:512 (GFLPOS) |
|---|---|---|---|
| 128 | 1.36425 | 3.04158 | 7.25379 |
| 256 | 3.01587 | 8.22155 | 32.29310 |
| 512 | 8.46080 | 22.69992 | 38.41876 |
| 1,024 | 20.99017 | 35.53175 | 69.69964 |
| 2,048 | 19.34377 | 43.89296 | 55.22402 |
| 4,096 | 39.77871 | 53.10321 | 60.49311 |
| 8,192 | 46.34932 | 68.93128 | 84.50218 |
| 16,384 | 70.84720 | 79.61441 | 85.88993 |
| [1] | JOSHI S M. FFT architectures: a review[J]. International Journal of Computer Applications, 2015, 116(7). |
| [2] | RAO K R, KIM D N, HWANG J J. Fast Fourier Transform: Algorithms and Applications[M]. Springer Science & Business Media, 2011. |
| [3] | KUMAR M A, CHAKRAPANI A. Classification of ECG signal using FFT based improved Alexnet classifier[J]. PLOS ONE, 2022, 17(9): e0274225. |
| [4] | VAN N N H, DO P H, HOANG V N, et al. Leveraging FFT and hybrid EfficientNet for enhanced action recognition in video sequences[C]// Proceedings of the 12th International Symposium on Information and Co mmunication Technology, 2023: 32-39. |
| [5] | 李亚美, 陈莉丽, 王锋, 等. 基于异构编程模型的FFT算法实现和优化[J]. 智能安全, 2023, 2(4): 24-34. |
| [6] | COOLEY J W, TUKEY J W. An algorithm for the machine calculation of complex Fourier series[J]. Mathematics of Computation, 1965, 19(90): 297-301. |
| [7] | LU Q, WANG X, MA W, et al. GFFT: A task graph based fast Fourier transform optimization framework[C]// Proceedings of the 52nd International Conference on Parallel Processing, 2023: 513-523. |
| [8] | DE DINECHIN B D, HASCOëT J, DESRENTES O. InPlace Multicore SIMD Fast Fourier Transforms[C]// 2023 IEEE High Performance Extreme Computing Conference (HPEC). IEEE, 2023: 1-6. |
| [9] | HU Y, LU L, LI C. Memory-accelerated parallel method for multidimensional fast Fourier implementation on GPU[J]. The Journal of Supercomputing, 2022, 78(16): 18189-18208. |
| [10] | HAO Y, LIU F, MA W, et al. MFFT: A GPU accelerated highly efficient mixed-precision large-scale FFT framework[J]. ACM Transactions on Architecture and Code Optimization, 2023, 20(3): 1-23. |
| [11] | PISHA L, LIGOWSKI Ł. Accelerating non-power-of-2 size Fourier transforms with GPU tensor cores[C]// 2021 IEEE International Parallel and Distributed Processing Symposium (IPDPS). IEEE, 2021: 507-516. |
| [12] | NVIDIA Corporation. cufft documentation v12.5.0[M/OL]. 2023. [2024-11-05]. https://developer.nvidia.com/cufft/archive/12.5.0/cufft/index.html. |
| [13] | ZHANG Z, HU N, ZHOU L. An efficient multi-step parallel fft algorithm on gpu[C]// International Conference on Algorithms, High Performance Computing, and Artificial Intelligence (AHPCAI 2024): volume 13403. SPIE, 2024: 66-72. |
| [14] | NVIDIA Corporation. Cuda c programming guide[M/OL]. NVIDIA Corporation, 2024. [20241101]. https://docs.nvidia.com/cuda/cudacprogrammingguide/index.html. |
| [15] | AMD. rocfft documentation 1.0.31[EB/OL]. 2024. [2-0241105]. https://rocm.docs.amd.com/projects/roc-FFT/en/latest/index.html. |
| [16] | AMD. Hip documentation[EB/OL]. 2024. [202411-05]. https://rocm.docs.amd.com/projects/HIP/en/lat est/index.html. |
| [17] | clMath Libraries. clfft: Opencl fast fourier transforms[EB/OL]. 2016.[20241105]. https://clmathlibraries.github.io/clFFT/. |
| [18] | FRIGO M, JOHNSON S G. Fftw:The fastest fourier transform in the west[EB/OL]. [20241105]. https://www.fftw.org/. |
| [19] | GROUP K. OpenCL documentation[EB/OL]. [2024-11-05]. https://www.khronos.org/opencl/. |
| [20] | LI B, CHENG S, LIN J. tcfft: A fast half-precision FFT library for NVIDIA tensor cores[C]// 2021 IEEE International Conference on Cluster Computing (CL USTER). IEEE, 2021: 1-11. |
| [21] | TOLMACHEV D. VkFFTa performant, crossplatform and open-source GPU FFT library[J]. IEEE Access, 2023, 11: 12039-12058. |
| [22] | VIZCAINO P, MANTOVANI F, FERRER R, et al. Acceleration with long vector architectures: Impleme-ntation and evaluation of the FFT kernel on NEC SX-Aurora and RISC-V vector extension[J]. Concurrency and Computation: Practice and Experience, 2023, 35(20): e7424. |
| [23] | 贾珍珍, 杨凌, 黄立波, 等. 开源GPU研究综述[J]. 小型微型计算机系统, 2024, 45(9): 2294-2304. |
| [24] | ROSENFELD V, BREß S, MARKL V. Query processing on heterogeneous CPU/GPU systems[J]. ACM Computing Surveys (CSUR), 2022, 55(1): 1-38. |
| [25] | DALLY W J, KECKLER S W, KIRK D B. Evolution of the graphics processing unit (gpu)[J]. IEEE Micro, 2021, 41(6): 42-51. |
| [26] | JEON H, RAVI G S, KIM N S, et al. Gpu register file virtualization[C]// Proceedings of the 48th International Symposium on Microarchitecture, 2015: 420-432. |
| [27] | DASHTI M, FEDOROVA A. Analyzing memory ma-nagement methods on integrated CPU-GPU systems[C]// Proceedings of the 2017 ACM SIGPLAN International Symposium on Memory Management, 2017: 59-69. |
| [28] | KIM D H. Evaluation of the performance of GPU global memory coalescing[J]. Evaluation, 2017, 4(4): 1-5. |
| [29] | 赵翔, 贾海鹏, 张云泉, 等. 基于ARMv8处理器的实数FFT实现与性能优化研究[J]. 计算机学报, 2023, 46(5): 1003-1018. |
| [1] | ZHENG Aiyu,MENG Xiangyu,ZHANG Boyu,ZHOU Lichan,YANG Haifeng. E+A Galaxy Search Based on a Domestic Heterogeneous Acceleration Platform: Parallelization Strategy and Implementation [J]. Frontiers of Data and Computing, 2025, 7(5): 102-112. |
| [2] | CAO Kai,TANG Xiao,CHEN Huansheng,MA Jingang,WU Qizhong,WANG Wending,CHEN Xueshun,LI Jinxi,WANG Zifa. Porting and Parallel Optimization of the Gas-Phase Chemistry Module of the Air Quality Model EPICC-Model on China’s Domestic Accelerators [J]. Frontiers of Data and Computing, 2025, 7(5): 123-137. |
| [3] | XIANG Xing,SUN Peijie,ZHANG Huahai,WANG Limin. Parallel Implementation of Three-Dimensional Lattice Boltzmann Method on Multi-GPU Platforms [J]. Frontiers of Data and Computing, 2025, 7(5): 16-27. |
| [4] | ZENG Yan,WU Baofu,YI Guangzheng,HUANG Chengchuang,QIU Yang,CHEN Yue,WAN Jian,HU Fan,JIN Sicong,LIANG Jiajun,LI Xin. FlowAware: A Feature-Aware Automated Model Parallelization Method for AI-for-Science Tasks [J]. Frontiers of Data and Computing, 2025, 7(5): 65-87. |
| [5] | HAN Xinyin, HAN Zidong, JI Detao, LI Chen, LU Zhonghua. AGPU-Accelerated Framework for Non-Small Cell Lung Cancer Subtype Identification [J]. Frontiers of Data and Computing, 2025, 7(3): 149-161. |
| [6] | ZHANG Kelong,HE Lianhua,XU Shun,JIN Zhong. Application of Mixed Precision GMRES Method in Lattice Quantum Chromodynamics [J]. Frontiers of Data and Computing, 2024, 6(6): 32-42. |
| [7] | SHANG Xiaomin, LI Qiang, GAO Lingyun, TAO Shunan, ZHOU Quan, YUAN Wu, LU Zhonghua. Research on Parallel Acceleration of OpenFOAM Threads for Domestic Accelerator [J]. Frontiers of Data and Computing, 2024, 6(2): 134-144. |
| [8] | WANG Yuming, WU Kaichao, NIU Chenhui, ZHANG Xiaoli. GPU Parallel Optimization for Fast Radio Burst Search Based on Containerization [J]. Frontiers of Data and Computing, 2024, 6(1): 102-112. |
| [9] | XU Shun, ZHANG Baohua, LIU Qian, JIN Zhong. eMD: A Large-Scale Molecular Dynamics Simulation Software Based on Heterogeneous Computing [J]. Frontiers of Data and Computing, 2024, 6(1): 21-34. |
| [10] | ZHANG Haoyuan, MA Wenpeng, YUAN Wu, ZHANG Jian, LU Zhonghua. Implementation of CCFD-KSSolver Component for GPU Architecture [J]. Frontiers of Data and Computing, 2024, 6(1): 68-78. |
| [11] | SUI Yicheng,SHI Changqing,SUN Yufei,ZHANG Yuzhi,CHEN Yuqiao,ZHANG Yuzhe. Implementation of Element-Wise Operator in TensorFlow Framework Based on OpenCL [J]. Frontiers of Data and Computing, 2022, 4(3): 19-29. |
| [12] | CHEN Yuqiao,SUN Yufei,CHENG Daguo,ZHANG Yuzhi,ZHOU Jianyu,SUI Yicheng,SHI Changqing. Design and Implementation of Testing and Verification Method for OpenCL Kernels in TensorFlow [J]. Frontiers of Data and Computing, 2022, 4(2): 17-28. |
| [13] | GAN Rundong,SHEN Shuyin,ZHANG Yuzhe. Multidimensional Linear Data Processing Based on OpenCL Kernel Function in MXNet Framework [J]. Frontiers of Data and Computing, 2022, 4(2): 29-38. |
| [14] | GUO Qiang,CHENG Daguo,SUN Yufei,ZHOU Jianyu,ZHANG Yuzhi,PEI Jiaao,GAN Rundong,CHEN Rui. Implementation and Integration of OpenCL Operators in TensorFlow Framework [J]. Frontiers of Data and Computing, 2022, 4(2): 3-16. |
| [15] | CAO Yikui,LU Zhonghua,ZHANG Jian,LIU Xiazhen,YUAN Wu,LIANG Shan. Parallel Optimization of CFD Core Algorithms Based on Domestic Processor [J]. Frontiers of Data and Computing, 2021, 3(4): 93-103. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||