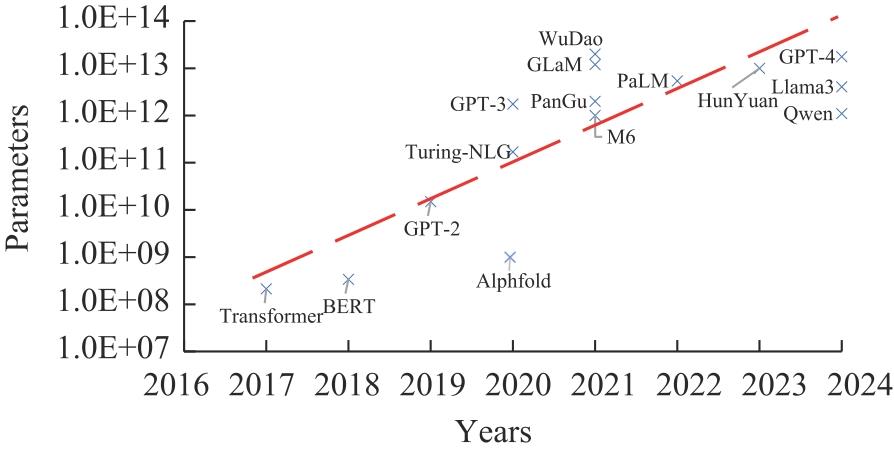
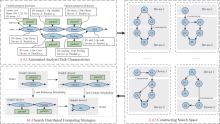
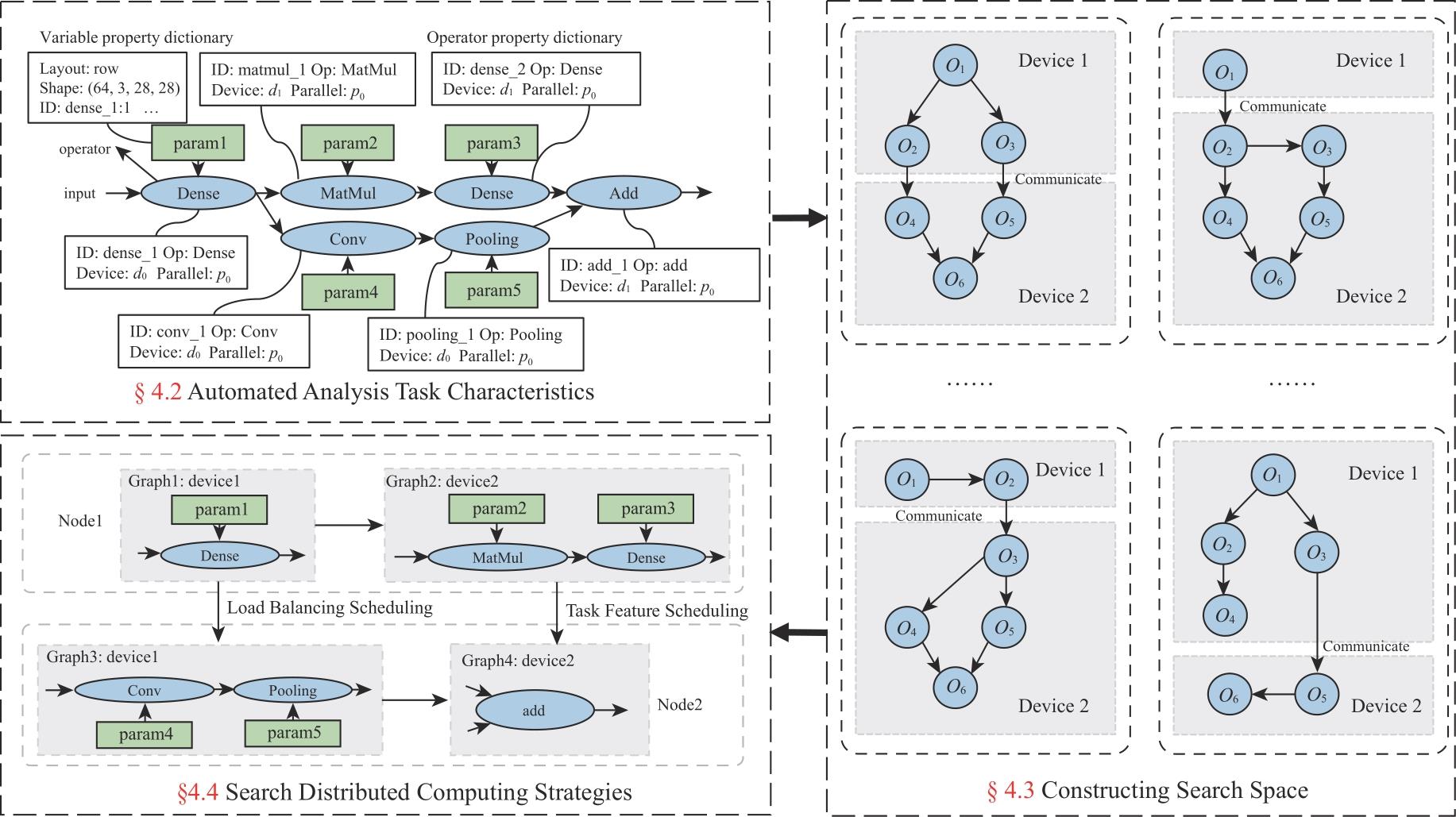
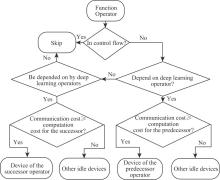
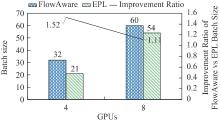
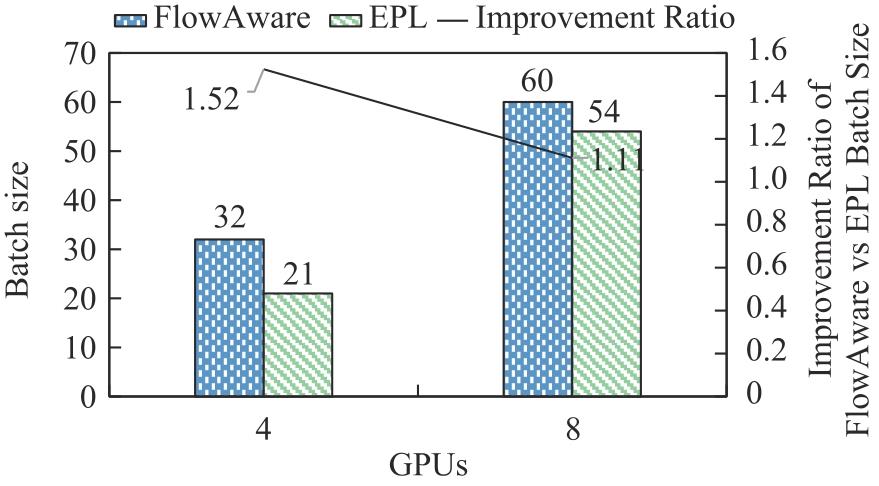
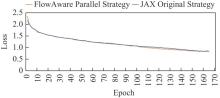
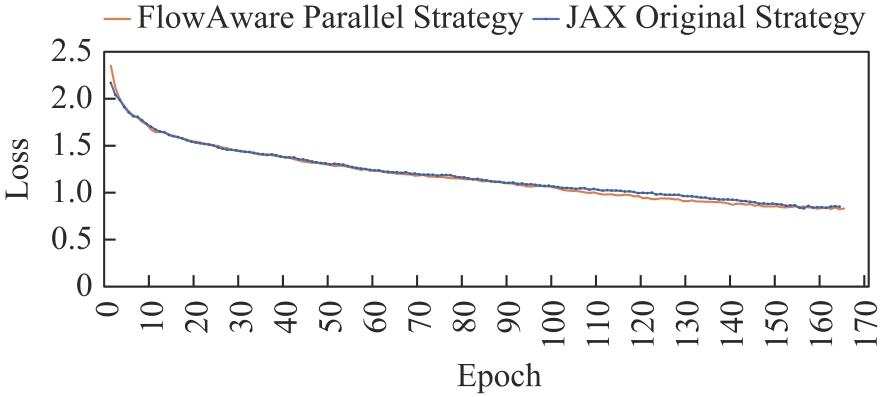
| [1] |
ABRAMSON J, ADLER J, DUNGER J, et al. Accurate structure prediction of biomolecular interactions with AlphaFold 3[J]. Nature, 2024, 630(8016): 493-500.
|
| [2] |
DU Y, WANG Y, HUANG Y, et al. M2Hub: Unlocking the Potential of Machine Learning for Materials Discovery[C]// Proceedings of the 37th International Conference on Neural Information Processing Systems, 2024: 77359-77378.
|
| [3] |
LIAO Y L, SMIDT T. Equiformer: Equivariant graph attention transformer for 3d atomistic graphs[J]. arXiv preprint arXiv:2206.11990, 2022.
|
| [4] |
JUMPER J, EVANS R, PRITZEL A, et al. Highly accurate protein structure prediction with AlphaFold[J]. Nature, 2021, 596(7873): 583-589.
|
| [5] |
SZYMANSKI N J, RENDY B, FEI Y, et al. An autonomous laboratory for the accelerated synthesis of novel materials[J]. Nature, 2023, 624(7990): 86-91.
|
| [6] |
WANG H, ZHANG L, HAN J, et al. DeePMD-kit: A deep learning package for many-body potential energy representation and molecular dynamics[J]. Computer Physics Communications, 2018, 228: 178-184.
|
| [7] |
WANG H, DING Y, GU J, et al. QuantumNAS: Noiseadaptive search for robust quantum circuits[C]//The 28th IEEE international symposium on high-performance computer architecture (HPCA-28), 2022: 692-708.
|
| [8] |
BRADBURY J, FROSTIG R, HAWKINS P, et al. JAX: composable transformations of Python+NumPy programs[EB/OL]. 2018. http://github.com/google/jax.
|
| [9] |
ZHENG L, LI Z, ZHANG H, et al. Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning[C]//16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22), 2022: 559-578.
|
| [10] |
HAN M, ZENG Y, SHU H, et al. Device placement using Laplacian PCA and graph attention networks[J]. The Computer Journal, 2025, 68(2): 175-186.
|
| [11] |
ZENG Y, HUANG C C, NI Y J, et al. An Auto-Parallel Method for Deep Learning Models Based on Genetic Algorithm[C]//2023 IEEE 29th International Conference on Parallel and Distributed Systems (ICPADS), IEEE, 2023: 230-235.
|
| [12] |
ZENG Y, YI G, YIN Y, et al. Aware: Adaptive distributed training with computation, communication and position awareness for deep learning model[C]// 2022 IEEE 24th Int Conf on High Performance Computing & Communications; 8th Int Conf on Data Science & Systems; 20th Int Conf on Smart City; 8th Int Conf on Dependability in Sensor, Cloud & Big Data Systems & Application (HPCC/DSS/SmartCity/DependSys), IEEE, 2022: 1299-1306.
|
| [13] |
MA Y, YU D, WU T, et al. PaddlePaddle: An open-source deep learning platform from industrial practice[J]. Frontiers of Data and Computing, 2019, 1(1): 105-115.
|
| [14] |
Huawei MindSpore AI Development Framework[M]//Huawei Technologies Co. Ltd. Artificial Intelligence Technology, Singapore: Springer Nature, 2023: 137-162.
|
| [15] |
SHOEYBI M, PATWARY M, PURI R, et al. Megatron-lm: Training multi-billion parameter language models using model parallelism[J]. arXiv preprint arXiv:1909.08053, 2019.
|
| [16] |
XU Q, YOU Y. An Efficient 2D Method for Training Super-Large Deep Learning Models[C]//2023 IEEE International Parallel and Distributed Processing Symposium (IPDPS), 2023: 222-232.
|
| [17] |
WANG B, XU Q, BIAN Z, et al. Tesseract: parallelize the tensor parallelism efficiently[C]// Proceedings of the 51st International Conference on Parallel Processing, 2022: 1-11.
|
| [18] |
BIAN Z, XU Q, WANG B, et al. Maximizing Parallelism in Distributed Training for Huge Neural Networks[J]. arXiv preprint arXiv:2105.14450, 2021.
|
| [19] |
JIA Z, ZAHARIA M, AIKEN A. Beyond Data and Model Parallelism for Deep Neural Networks[C]// Proceedings of machine learning and systems: Vol. 1, 2018: 1-13.
|
| [20] |
JEON B, CAI L, SRIVASTAVA P, et al. Baechi: fast device placement of machine learning graphs[C]// Proceedings of the 11th ACM Symposium on Cloud Computing, Virtual Event USA: ACM, 2020: 416-430.
|
 ),WU Baofu1,YI Guangzheng1,HUANG Chengchuang1,QIU Yang1,CHEN Yue1,WAN Jian1,2,*(
),WU Baofu1,YI Guangzheng1,HUANG Chengchuang1,QIU Yang1,CHEN Yue1,WAN Jian1,2,*(