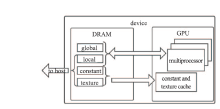
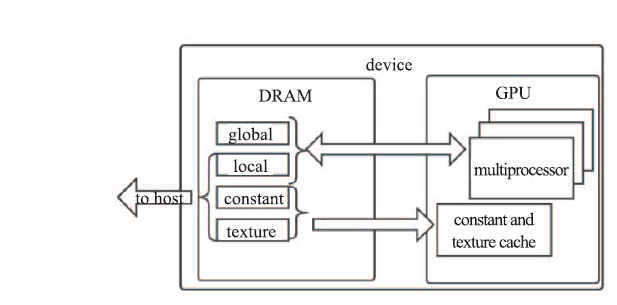
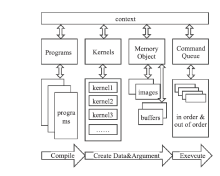
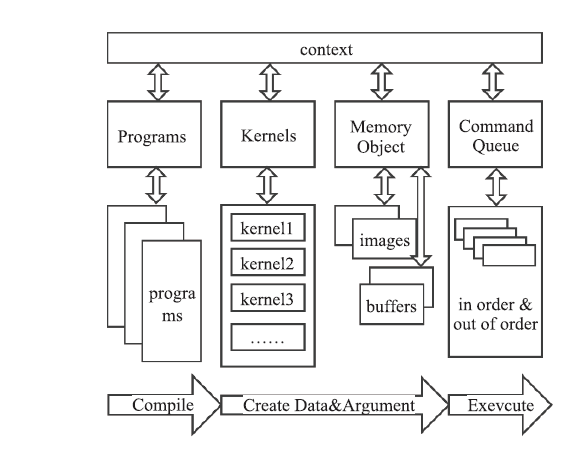
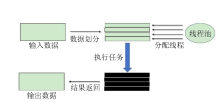
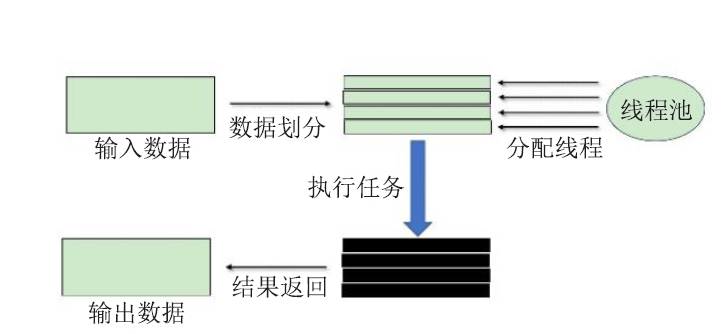
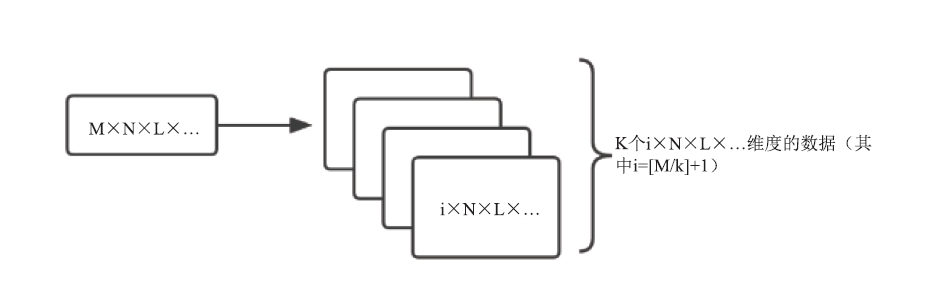
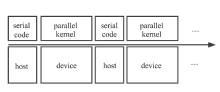
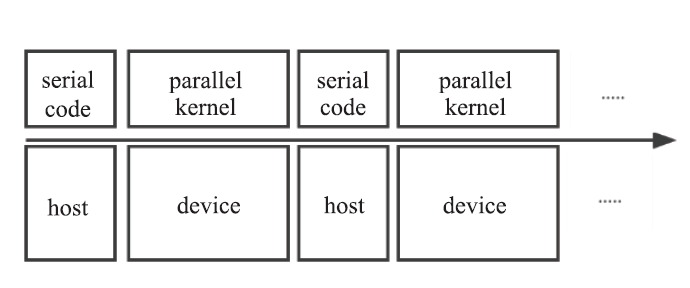
| [1] |
Chen X W, Lin X. Big data deep learning: challenges and perspectives[J]. IEEE access, 2014, 2: 514-525.
doi: 10.1109/ACCESS.2014.2325029
|
| [2] |
Blanaru F, Stratikopoulos A, Fumero J, et al. Enabling pipeline parallelism in heterogeneous managed runtime environments via batch processing[C]// Proceedings of the 18th ACM SIGPLAN/SIGOPS International Conference on Virtual Execution Environments, 2022: 58-71.
|
| [3] |
Georganas E, Avancha S, Banerjee K, et al. Anatomy of high-performance deep learning convolutions on simd architectures[C]// SC18: International Conference for Hi-gh Performance Computing, Networking, Storage and Analysis, IEEE, 2018: 830-841.
|
| [4] |
Garla Grand S, Nickolls J, et al. Parallel computing ex-periences with CUDA[J]. IEEE micro, 2008, 28(4): 13-27.
doi: 10.1109/MM.2008.57
|
| [5] |
Sanders J, Kandrot E. CUDA by example: an introduction to general-purpose GPU programming[M]. Addison-Wesley Professional, 2010: 4-11.
|
| [6] |
Che S, Boyer M, Meng J, et al. A performance study of general-purpose applications on graphics processors using CUDA[J]. Journal of parallel and distributed computing, 2008, 68(10): 1370-1380.
doi: 10.1016/j.jpdc.2008.05.014
|
| [7] |
Stone J E, Gohara D, Shi G. OpenCL: A parallel progr-amming standard for heterogeneous computing systems[J]. Computing in science & engineering, 2010, 12(3): 66-73.
|
| [8] |
Karimi K, Dickson N G, Hamze F. A performance com-parison of CUDA and OpenCL[J]. arXiv preprint arXiv: 1005.2581, 2010.
|
| [9] |
Chen T, Li M, Li Y, et al. Mxnet: A flexible and efficient machine learning library for heterogeneous distributed systems[J]. arXiv preprint arXiv:1512.01274, 2015.
|
| [10] |
Poenaru A, Lin W C, McIntosh-Smith S. A performance analysis of modern parallel programming models using a compute-bound application[C]// International Conference on High Performance Computing, Springer, Cham, 2021: 332-350.
|
 ),SHEN Shuyin*(
),SHEN Shuyin*(