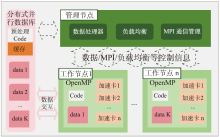
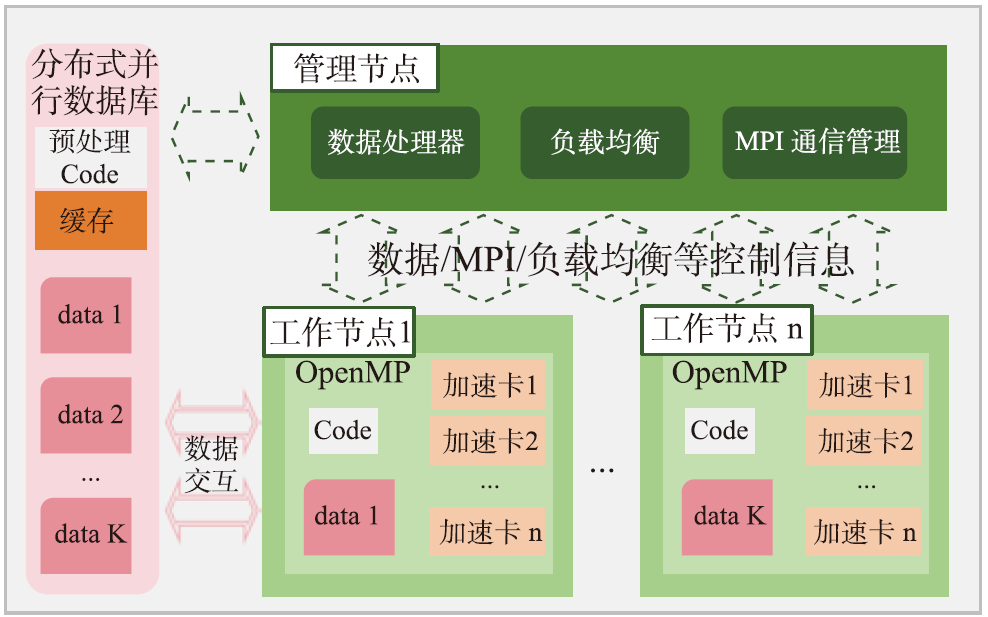
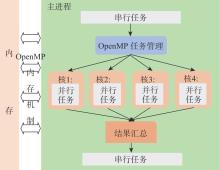
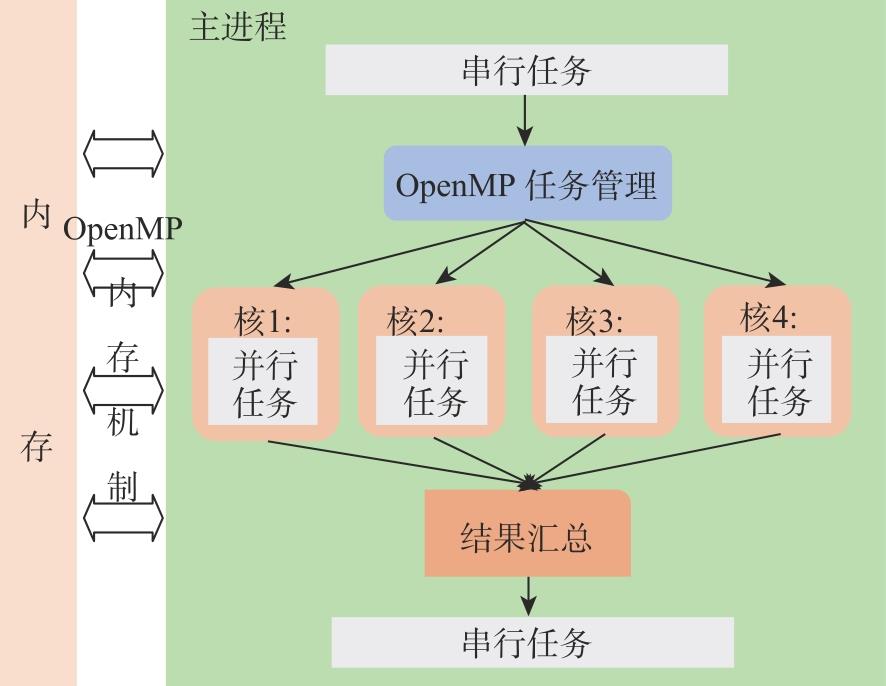
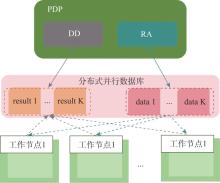
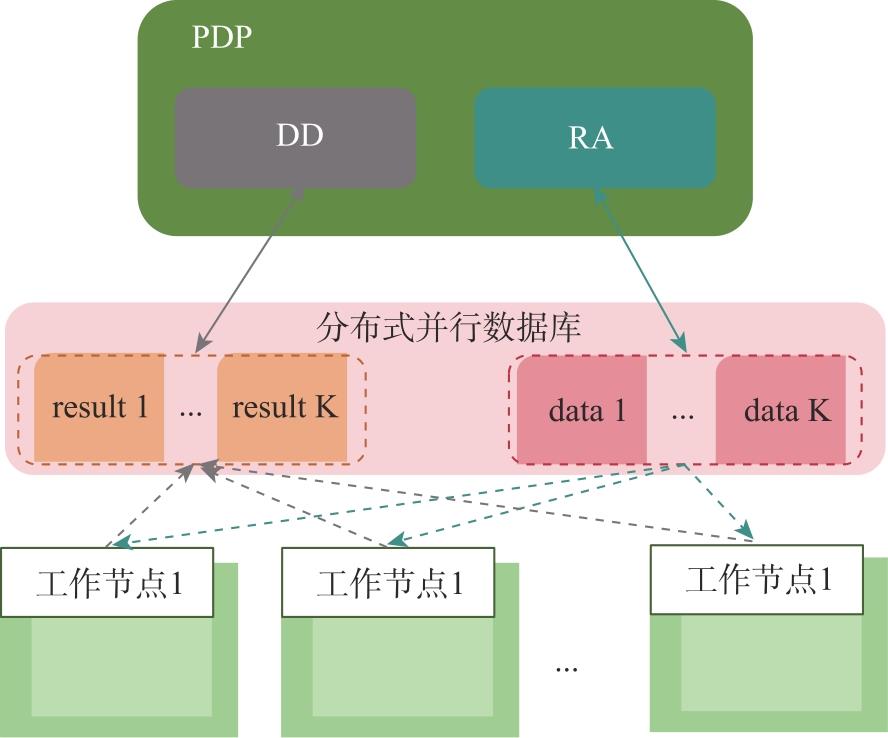
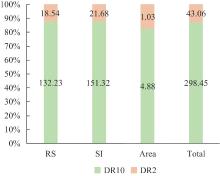
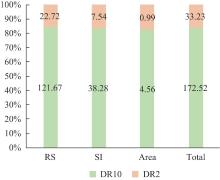
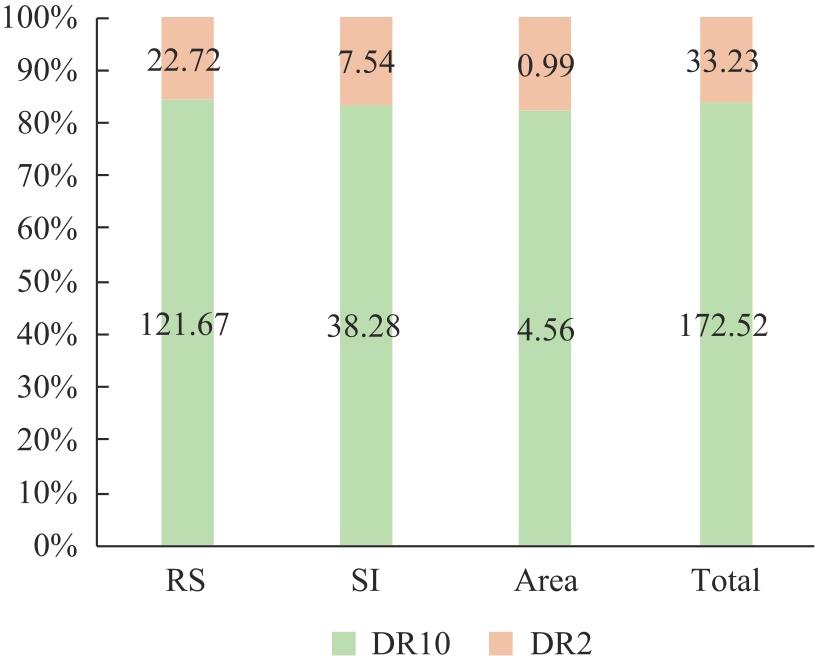
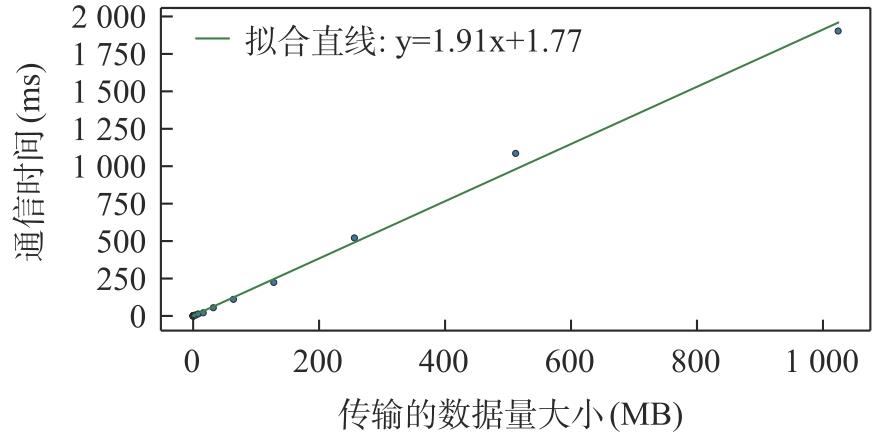
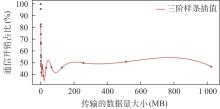
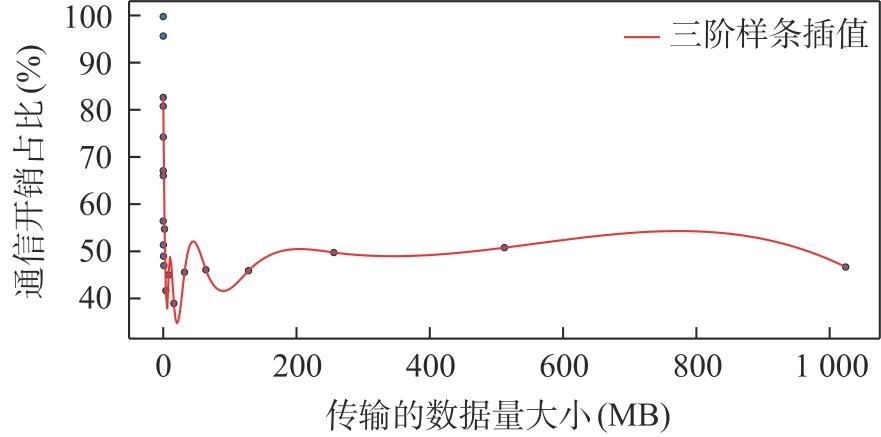
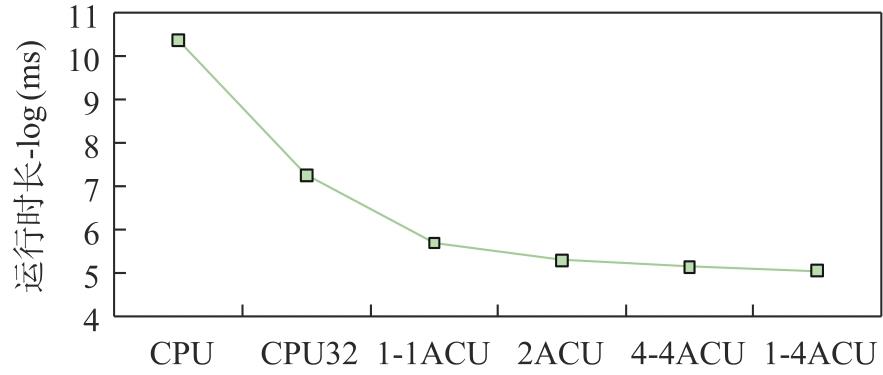
| [1] |
YORK, DONALD G, et al. The sloan digital sky survey: Technical summary[J]. The Astronomical Journal, 2000, 120(3): 1579-1587.
|
| [2] |
YANG H F, LUO A L, CHEN X Y, et al. A sample of E+ A galaxy candidates in the Second Data Release of LAMOST Survey[J]. Research in Astronomy and Astrophysics, 2015, 15(8): 1414-1420.
|
| [3] |
LUO Y, NEMETH P, WANG K, et al. VizieR Online Data Catalog: Hot subdwarf stars with Gaia DR2 and LAMOST DR7 data (Luo+, 2021)[J]. VizieR Online Data Catalog, 2022, 225: 746-751.
|
| [4] |
ABDELLAH E, SAMIR R M, AWAD Z, et al. SDSS-IV MaNGA: the environmental effects on some fundamental properties of early-type galaxies[J]. Astrophysics and Space Science, 2025, 370(1): 7-11.
|
| [5] |
YANG H F, WANG R, CAI J H, et al. A Sample of Am and Ap Candidates from LAMOST DR10 (v1. 0) Based on the Ensemble Regression Model[J]. The Astrophysical Journal Supplement Series, 2024, 272(2): 43-50.
|
| [6] |
Large Sky Area Multi-Object Fiber Spectroscopic Telescope DATA RELEASE 13 v0 Q1[EB/OL]. [2023-04-02]. https://www.lamost.org/dr13/.
|
| [7] |
黄国如, 陈志威, 曾博威. 城市洪涝模型及CPU-GPU异构并行计算技术研究进展[J]. 水利学报, 2023, 54(6): 654-665.
|
| [8] |
杨晨, 翁祖建, 孟小峰, 等. 天文大数据挑战与实时处理技术[J]. 计算机研究与发展, 2017, 54(2): 10-15.
|
| [9] |
裴彤, 张彦霞, 彭南博, 等. Python多核并行计算在海量星表交叉证认中的应用[J]. 中国科学: 物理学、力学、天文学, 2011, 41(1): 6-12.
|
| [10] |
杜帅岐, 刘晓楠, 廉德萌, 等. Grover量子搜索算法在"嵩山"超级计算机系统中的模拟[J]. 计算机科学, 2024, 51(9): 96-102.
doi: 10.11896/jsjkx.230600219
|
| [11] |
黄聪祎, 赵伟文, 万德成. 国产DCU加速卡与MPS方法结合高效模拟带障碍物溃坝流动问题[J]. 水动力学研究与进展A辑, 2024(5): 45-55.
|
| [12] |
WILKINSON C L, K A PIMBBLET, J P STOTT. The evolutionary sequence of post-starburst galaxies[J]. Monthly Notices ROYAL ASTRONOMICAL SOCIETY, 2017, 472: 1447-1457.
|
| [13] |
ZHAO Y H. Large-scale astronomical spectroscopic surveys[J]. Scientia Sinica Physica, Mechanica & Astronomica, 2014, 44(10): 1041-1048.
|
| [14] |
WILKINSON C L, PIMBBLET K A, STOTT J P. The evolutionary sequence of post-starburst galaxies[J]. Monthly Notices of the Royal Astronomical Society, 2017, 472(2): 1447-1457.
|
| [15] |
KONG L, HUANG T, ZHU Y, et al. Big Data in Astronomy: Scientific Data Processing for Advanced Radio Telescopes[M]. Elsevier, 2020:3 05-323.
|
| [16] |
GOTO T. Are E+ A galaxies dusty-starbursts?: VLA 20 cm radio continuum observation[J]. Astronomy & Astrophysics, 2004, 427(1): 125-130.
|
| [17] |
祝鹏. 异构并行计算下高维混合型数据聚类算法研究[J]. 现代电子技术, 2024, 47(9): 139-142.
|
| [18] |
贾瑞鹏, 林中朝, 左胜, 等. 面向国产异构DCU平台的大规模并行矩量法研究[J]. 西安电子科技大学学报, 2024, 51(2): 76-83.
|
| [19] |
刘晓楠, 廉德萌, 杜帅岐, 等. 基于矩阵乘积态的有限纠缠量子傅里叶变换模拟[J]. 计算机科学, 2024, 51(9): 80-86.
doi: 10.11896/jsjkx.230300215
|
| [20] |
国产异构计算平台开发者社区[EB/OL]. [2023-03-24]. https://developer.sourcefind.cn/.
|
 ),MENG Xiangyu,ZHANG Boyu,ZHOU Lichan,YANG Haifeng*(
),MENG Xiangyu,ZHANG Boyu,ZHOU Lichan,YANG Haifeng*(