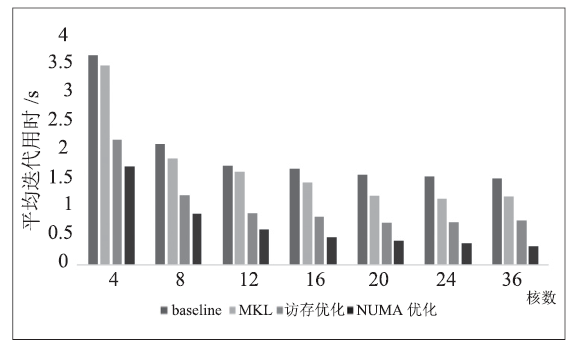
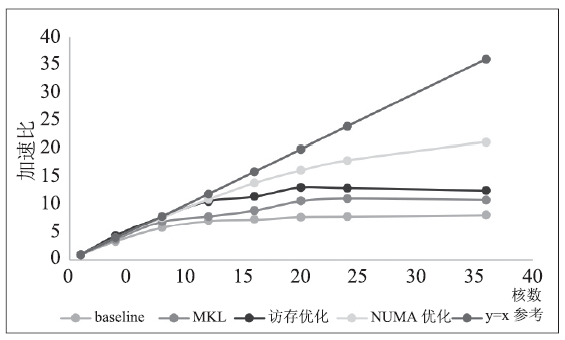
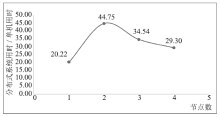
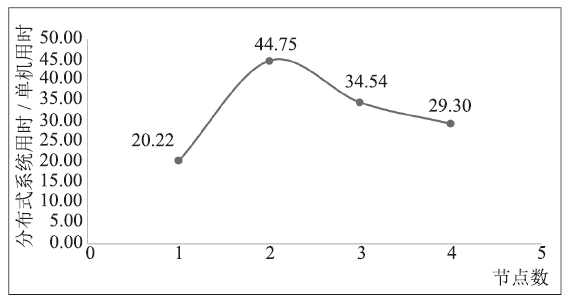
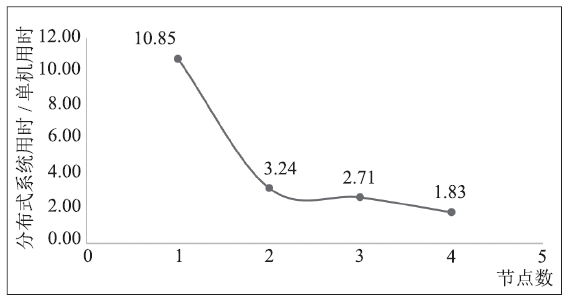
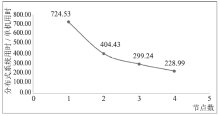
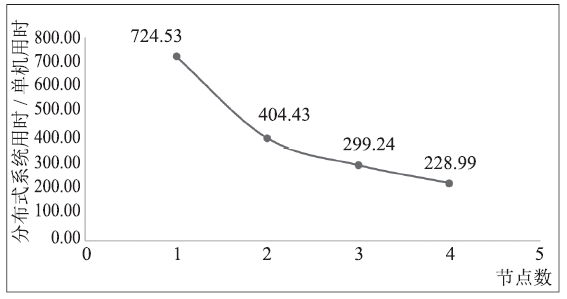
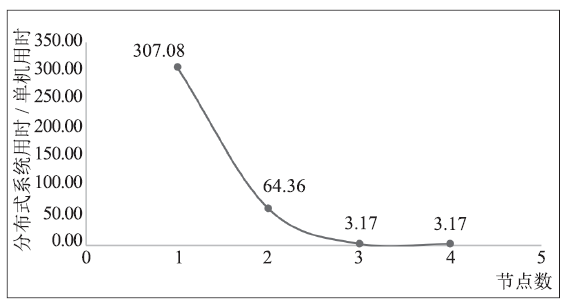
| [1] |
Hadoop. .
|
| [2] |
Spark. .
|
| [3] |
McSherry F, Isard M, Murray D G. Scalability! but at what cost? [C]//HotOS. [S.l.]: Citeseer, 2015.
|
| [4] |
Zaharia M, Chowdhury M, Das T, et al. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing [C]//Proceedings of the 9th USENIX conference on Networked Systems Design and Implementation. [S.l.]: USENIX Association, 2012: 2-2.
|
| [5] |
Wang L, Zhan J, Luo C, et al. Bigdatabench: A big data benchmark suite from internet services [C]//High Performance Computer Architecture (HPCA), 2014 IEEE 20th International Symposium on. [S.l.]: IEEE, 2014: 488-499.
|
| [6] |
Meng X, Bradley J, Yavuz B , et al. Mllib: Machine learning in apache spark[J]. The Journal of Machine Learning Research, 2016,17(1):1235-1241.
|
| [7] |
LeCun Y., Cortes C., & Burges C. J. ( 2010). MNIST handwritten digit database. AT&T Labs [Online]. Available: , 2, 18.
|
| [8] |
Wang E., Zhang Q., Shen B., Zhang G., Lu X., Wu Q., & Wang Y . ( 2014). Intel math kernel library[M]. In High-Performance Computing on the Intel® Xeon Phi™( pp. 167-188) . Springer, Cham.
|
| [9] |
Lameter C . Numa (non-uniform memory access): An overview[J]. Queue, 2013,11(7):40.
|
| [10] |
Wikipedia contributors. Limited-memory bfgs — Wikipedia, the free encyclopedia[Z]. [S.l.:s.n.], 2018.
|
| [11] |
Malewicz G., Austern M. H., Bik A. J., Dehnert J. C., Horn I., Leiser N., & Czajkowski G. ( 2010, June). Pregel: a system for large-scale graph processing [C]. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of data (pp. 135-146). ACM.
|
| [12] |
Bu Y., Howe B., Balazinska M., & Ernst M. D. ( 2010). HaLoop: efficient iterative data processing on large clusters [C]. Proceedings of the VLDB Endowment, 3(1-2), 285-296.
|
| [13] |
Nitzberg, B., & Lo, V . ( 1991). Distributed shared memory: A survey of issues and algorithms[J]. Computer, 24(8), 52-60.
|
| [14] |
Pfister, G. F . ( 2001). An introduction to the infiniband architecture[J]. High Performance Mass Storage and Parallel I/O, 42, 617-632.
|
| [15] |
Liu J., Wu J., & Panda D. K . ( 2004). High performance RDMA-based MPI implementation over InfiniBand[J]. International Journal of Parallel Programming, 32(3), 167-198.
|
| [16] |
Zhu X., Chen W., Zheng W., & Ma X. ( 2016). Gemini: A computation-centric distributed graph processing system [C]. In 12th {USENIX} Symposium on Operating Systems Design and Implementation( {OSDI} 16) (pp. 301-316).
|
| [17] |
Isard M., Budiu M., Yu Y., Birrell A., & Fetterly D. ( 2007, March). Dryad: distributed data-parallel programs from sequential building blocks [C]. In ACM SIGOPS operating systems review (Vol. 41, No. 3, pp. 59-72). ACM.
|
| [18] |
Li P., Luo Y., Zhang N., & Cao Y. ( 2015, August). Heterospark: A heterogeneous cpu/gpu spark platform for machine learning algorithms [C]. In 2015 IEEE International Conference on Networking, Architecture and Storage (NAS)( pp. 347-348). IEEE.
|
| [19] |
Hong S., Choi W., & Jeong, W. K. (2017, May). GPU in-memory processing using Spark for iterative computation[C]. In Proceedings of the 17th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (pp. 31-41). IEEE Press.
|
| [20] |
Kanungo T, Mount D M, Netanyahu N S , et al. An efficient k-means clustering algorithm: Analysis and implementation[J]. IEEE transactions on pattern analysis and machine intelligence, 2002,24(7):881-892.
|
| [21] |
McCallum A, Nigam K, Ungar L H. Efficient clustering of high-dimensional data sets with application to reference matching [C]//Proceedings of the sixth ACM SIGKDD international conference on Knowledge discovery and data mining. [S.l.]: ACM, 2000: 169-178.
|
 )
)