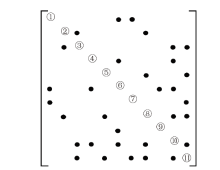
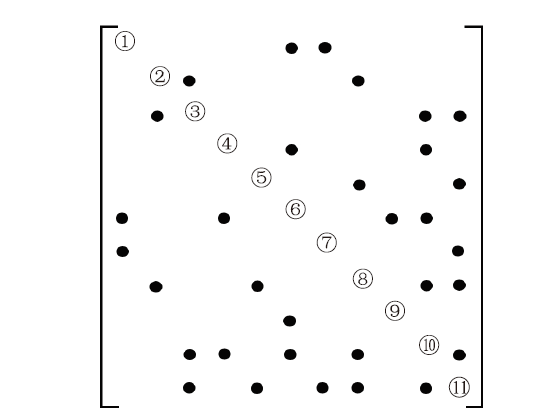
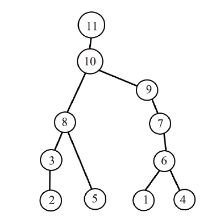
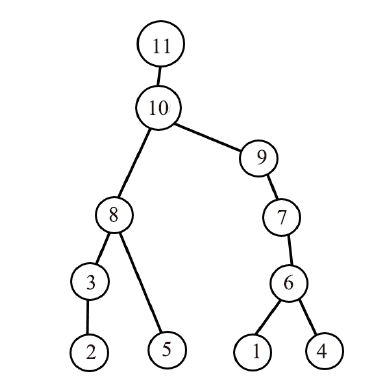
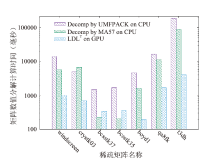
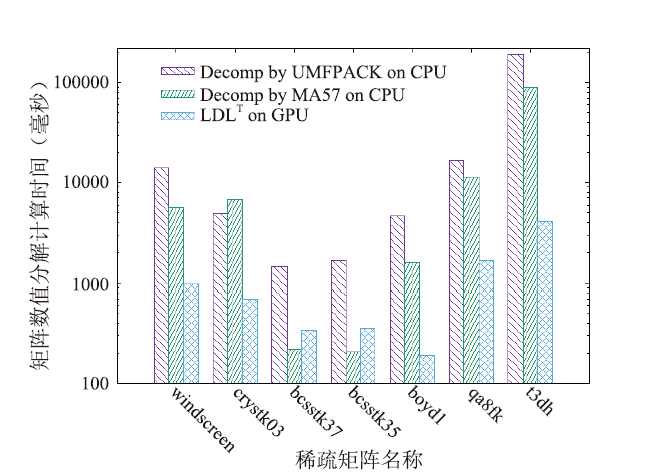
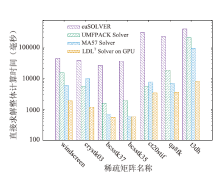
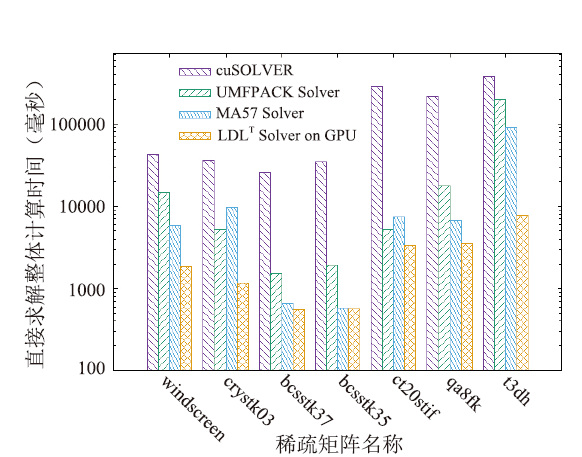
| [1] |
NVIDIA Corporation, CUBLAS library [CP/OL]. http://developer.nvidia.com/cublas.
|
| [2] |
Rutherford Appleton Laboratory, the HSL mathematical software library [CP/OL]. http://www.hsl.rl.ac.uk.
|
| [3] |
NVIDIA Corporation, CUSPARSE library[CP/OL]. http://developer.nvidia.com/cusparse.
|
| [4] |
Peng S, Tan S X. GLU3.0: Fast GPU-based Parallel Sparse LU Factorization for Circuit Simulation[J]. IEEE Design & Test, 2020, 37(3):78-90.
|
| [5] |
Kirk D B, Hwu W W. Programming Massively Parallel Processors: A Hands-on Approach[M]. 2ed, Elsevier Inc., 2013: 1-40.
|
| [6] |
Davis T A. Direct Methods for Sparse Linear Systems[M]. SIAM, 2006: 38-59.
|
| [7] |
Gilbert J R, Peierls T. Sparse partial pivoting in time proportional to arithmetic operations[J]. SIAM journal on scientific and statistical computing, 1988, 9(5):862-874.
doi: 10.1137/0909058
|
| [8] |
Parter S. The use of linear graphs in Gauss elimination[J]. SIAM review, 1961, 3(2):119-130.
doi: 10.1137/1003021
|
| [9] |
Liu J W. A compact row storage scheme for Cholesky factors using elimination trees[J]. ACM Transactions on Mathematical Software (TOMS), 1986, 12(2):127-148.
doi: 10.1145/6497.6499
|
| [10] |
Rose D J, Tarjan R E, Lueker G S. Algorithmic aspects of vertex elimination on graphs[J]. SIAM Journal on computing, 1976, 5(2):266-283.
doi: 10.1137/0205021
|
| [11] |
Schreiber R. A new implementation of sparse Gaussian elimination[J]. ACM Trans. Math. Softw., 1982, 8(3):256-276.
doi: 10.1145/356004.356006
|
| [12] |
Amestoy R P, Davis T A, Duff I S. Algorithm 837: AMD, an Approximate Minimum Degree Ordering Algorithm[J]. ACM Trans. Math. Softw., 2004, 30(3):381-388.
doi: 10.1145/1024074.1024081
|
| [13] |
METIS-Serial Graph Partitioing and Fill-reducing Matrix Ordering [CP/OL]. http://glaros.dtc.umn.edu/gkhome/METIS.
|
| [14] |
Lee W, Achar R, Nakhla M S. Dynamic GPU Parallel Sparse LU Factorization for Fast Circuit Simulation[J]. IEEE Transactions on Very Large Scale Integration, 26(11):2518-2529, 2018.
doi: 10.1109/TVLSI.2018.2858014
|
| [15] |
Li X S, Demmel J. A Scalable Sparse Direct Solver Using Static Pivoting[C]. Proceedings of the Ninth SIAM Conference on Parallel Processing for Scientific Computing, 22-24, 1999.
|
| [16] |
Arioli M, Demmel J W, Duff I S. Solving sparse linear systems with sparse backward error[J]. SIAM Journal on Matrix Analysis and Applications, 1989, 10(2):165-190.
doi: 10.1137/0610013
|
| [17] |
He K, Tan S, Wang H, Shi G. GPU-accelerated parallel Sparse LU factorization method for fast circuit analysis[J]. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2015, 24(3):1140-1150.
doi: 10.1109/TVLSI.2015.2421287
|
| [18] |
Sanders J, Kandrot E. CUDA by Example: an Introduction to General-Purpose GPU Program- ming[M]. Addison-Wesley Professional, 2011: 163-184.
|
| [19] |
扶月月, 王武, 王乔. 基于FMM-PM方法的宇宙N体模拟在GPU上的实现和优化[J]. 数据与计算发展前沿, 2020, 2(2):155-164.
|
| [20] |
张留莹, 王鹏飞, 张峰, 刘海龙, 林鹏飞, 王涛, 韦俊林, 田少博, 姜金荣, 迟学斌. 海洋环流模式LICOM的GPU实现与优化[J]. 数据与计算发展前沿, 2020, 2(4):92-104.
|
| [21] |
党冠麟, 刘世伟, 胡晓东, 张鉴, 李新亮. 基于CPU/GPU异构系统架构的高超声速湍流直接数值模拟研究[J]. 数据与计算发展前沿, 2020, 2(1):105-116.
|
| [22] |
Cheng J, Grossman M, McKercher T. Professional CUDA C Programming[M]. John Wiley, 2014: 122-131.
|
| [23] |
Davis T. the University of Florida Sparse Matrix Collection [CP/OL]. http://sparse.tamu.edu.
|
| [24] |
SuiteSparse[CP/OL]. https://people.engr.tamu.edu/davis/suitesparse.html.
|
 ),王武1,*(
),王武1,*(