数据与计算发展前沿 ›› 2020, Vol. 2 ›› Issue (2): 31-39.
doi: 10.11871/jfdc.issn.2096-742X.2020.02.003
所属专题: “数据分析技术与应用”专刊
孟珍1,2,王学志1,2,谢志敏3,胡良霖1,2,陈之端2,4,马俊才2,5,佟继周2,6,张艳玲7,*( ),周园春1,2,*()
),周园春1,2,*()
Meng Zhen1,2,Wang Xuezhi1,2,Xie Zhimin3,Hu Lianglin1,2,Chen Zhiduan2,4,Ma Juncai2,5,Tong Jizhou2,6,Zhang Yanling7,*(),Zhou Yuanchun1,2,*()
摘要:
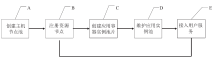
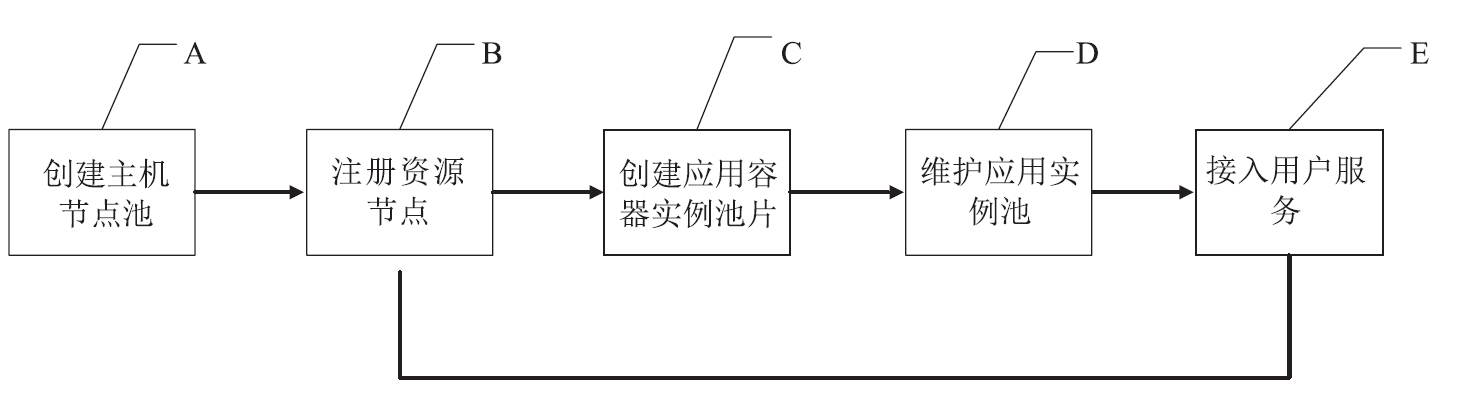
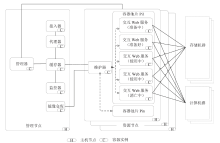
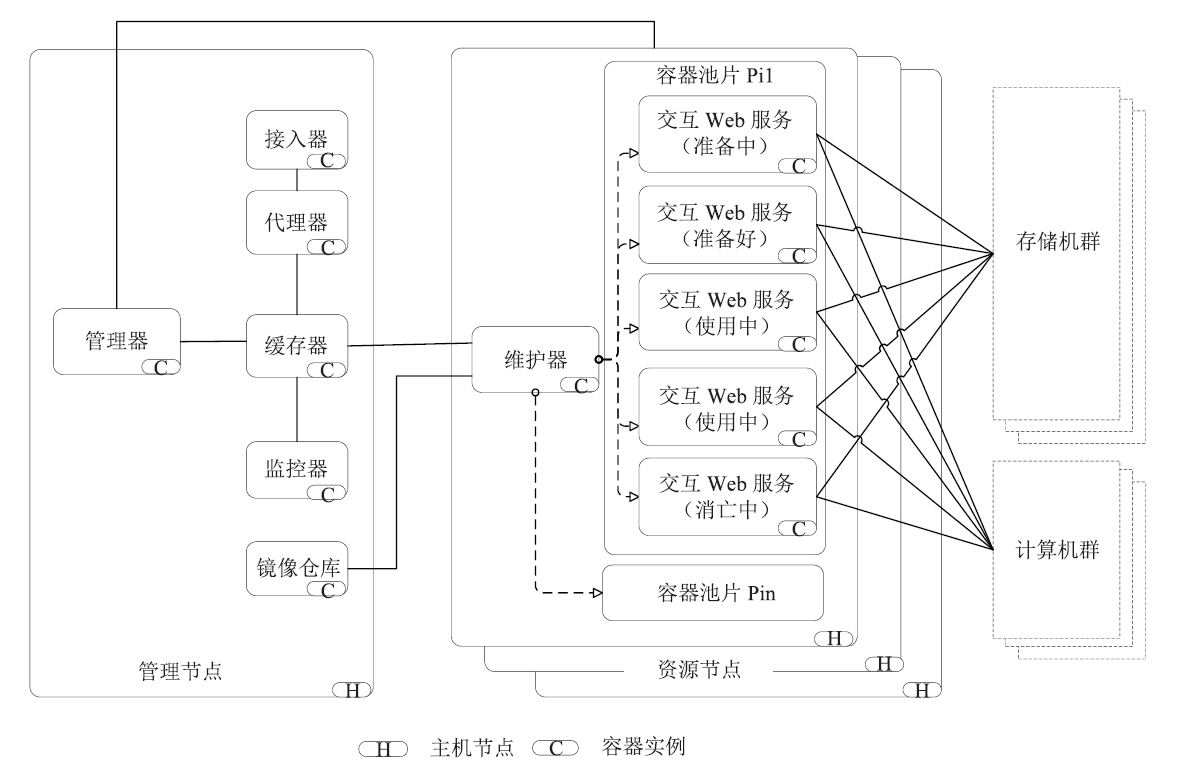
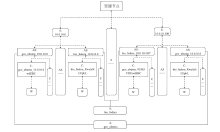
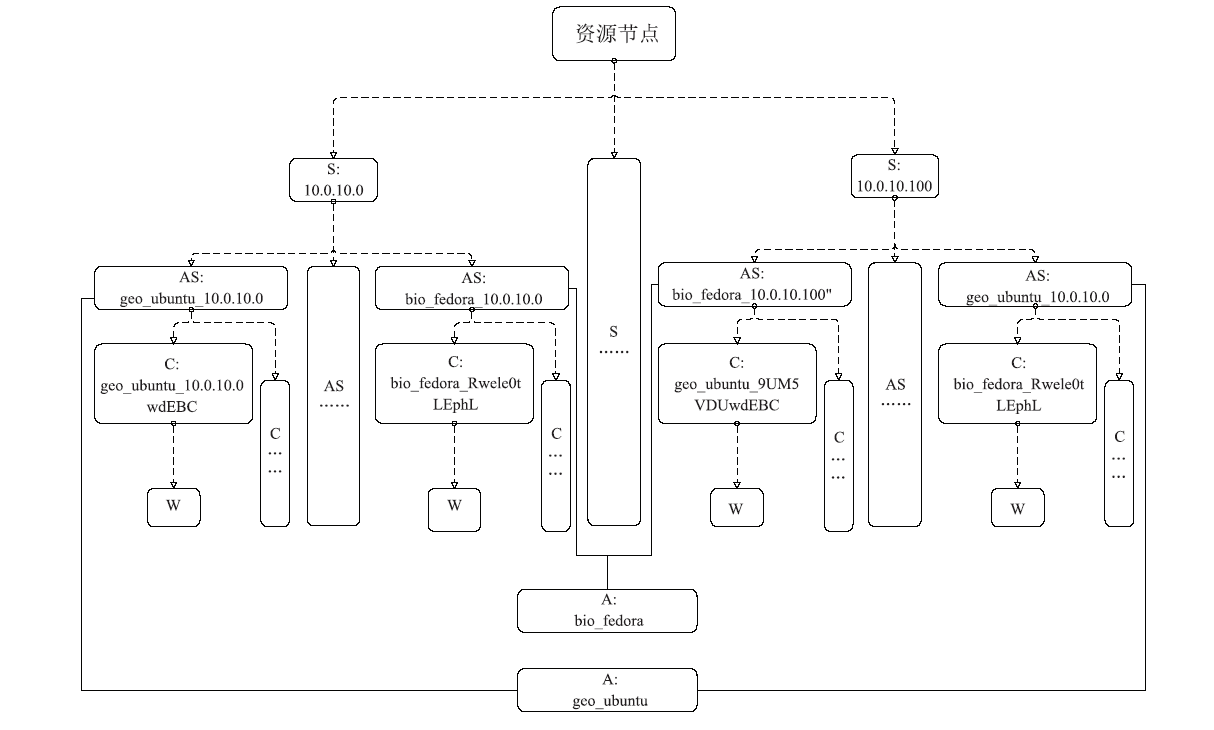
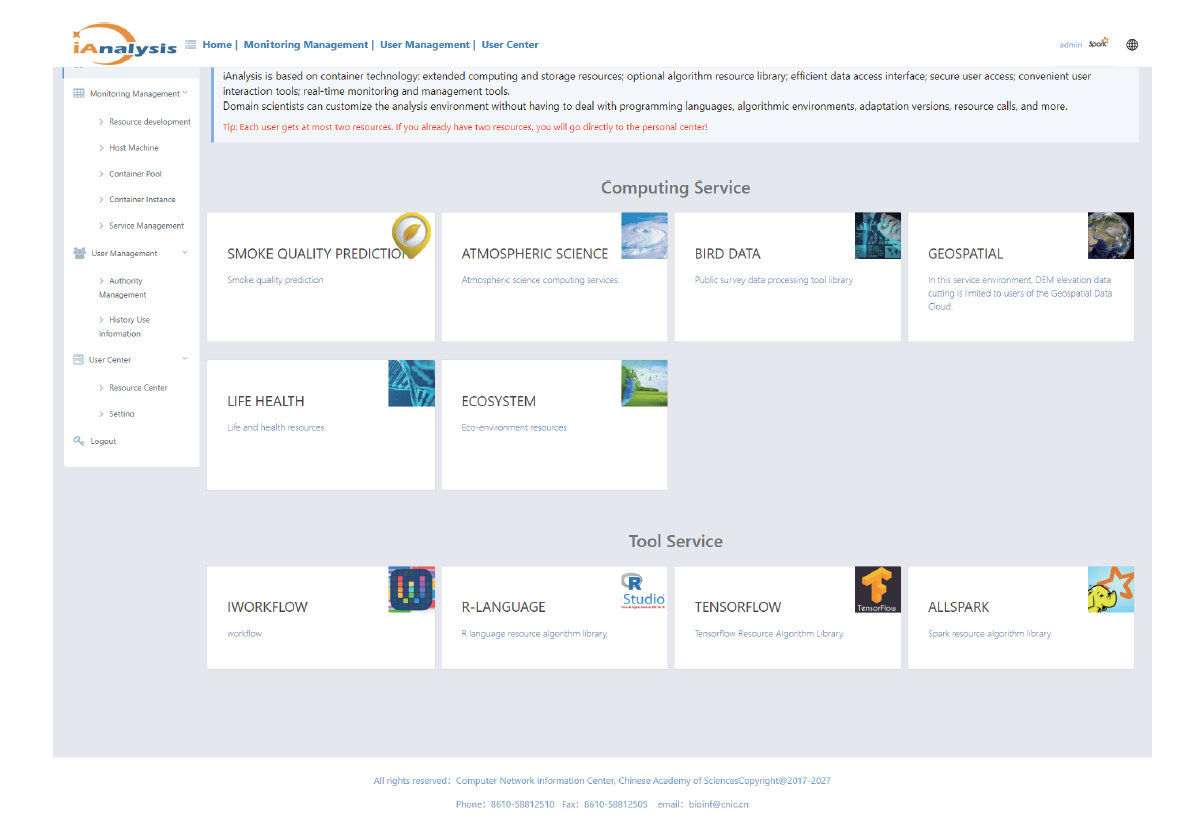
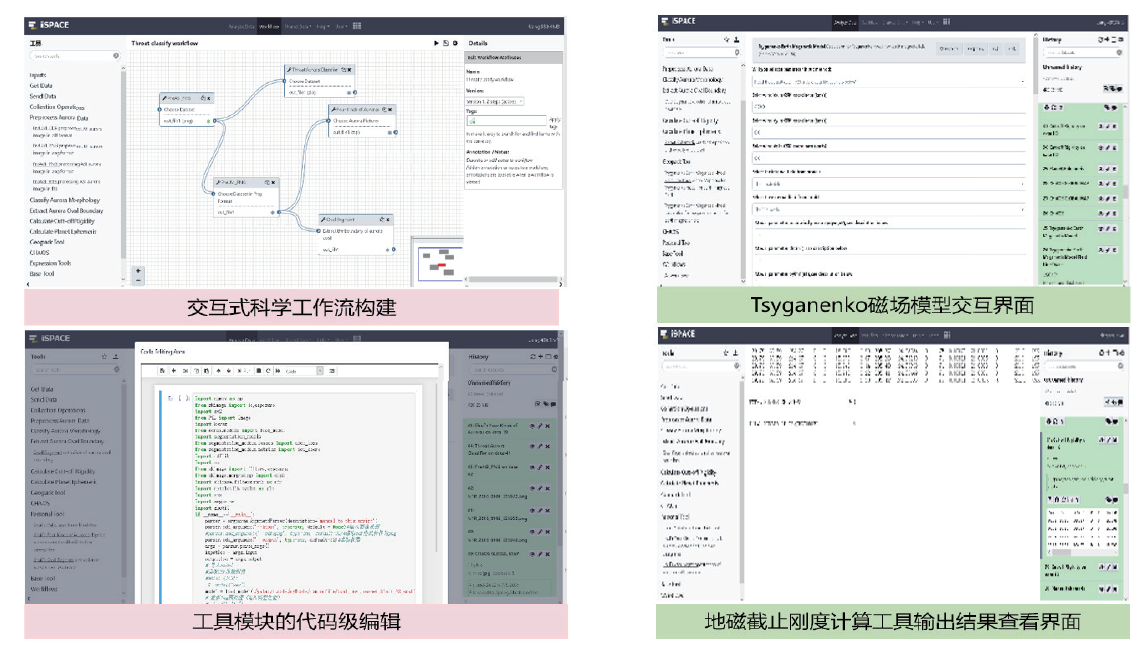
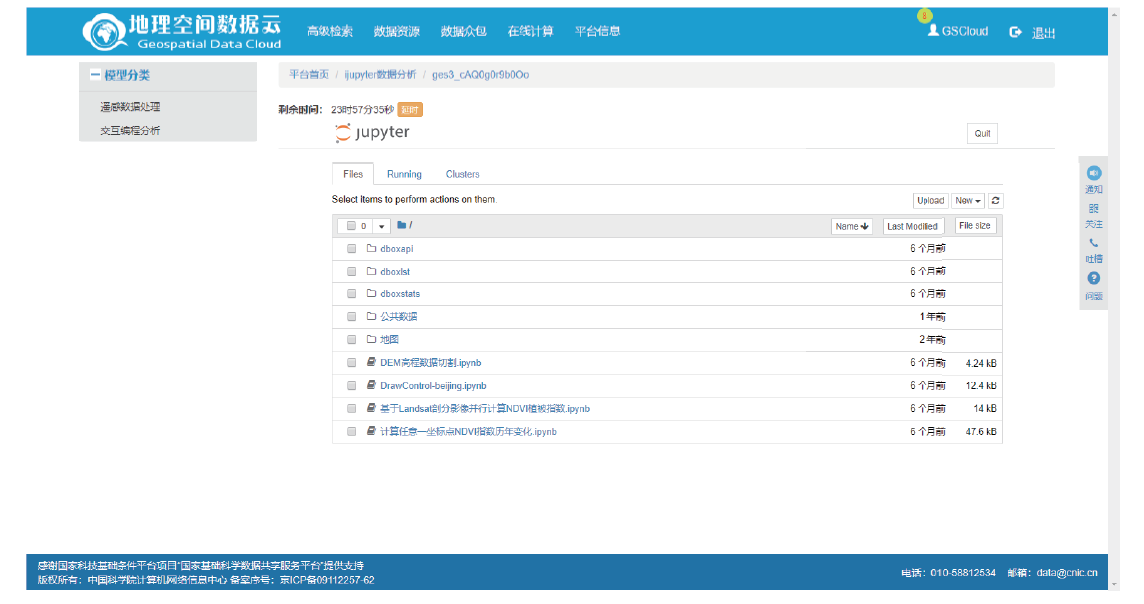
【目的】随着科学大数据技术的发展,问题导向的数据端分析成为常态。科学数据处理以云计算的形式跑在数据端,并提供安全的用户访问方式、可选的算法资源库、高效的数据存取接口、便捷的用户交互工具、有效扩展的计算和存储资源,将有力提升科学家的数据分析探索效率。【方法】本文提出一种基于容器技术的科学数据端云分析服务管理引擎设计方案:资源节点以自动注册的方式进行横向扩展,资源节点可以是物理主机或虚拟主机;当在用资源达到阈值,管理节点通过接口启动资源节点的注册,同时资源入池;可选的算法资源库、高效的数据和计算访问接口均以容器镜像的方式进行版本控制,在构造资源池时选用。容器实例池的健康度在节点内部进行维护,根据用户的最长使用时间、静默时间等进行实例生命周期管理;内部资源池的容器实例有准备中、准备好、使用中、消亡中几种状态,并始终维护资源池的固定大小。用户认证访问时,根据用户的领域算法库的选择和资源池的使用率进行新用户资源的接入,并通过代理配置提供唯一的标识入口以供用户访问;用户以安全加密的网络访问方式访问交互编程组件或交互应用组件,即可使用数据端的数据资源和计算资源。每个交互组件均在独立的容器实例中,可以进行有效的资源隔离。【结果】基于以上科学数据端云分析服务管理引擎构建的交互分析云服务系统IA(Interactive Analysis Cloud Service System)V1.0,实现了科学数据端云分析资源的统一管理服务,可以通过服务门户直接面向终端科学家使用,也可以通过API接口以docker容器交付的方式给其它现有数据系统调用。已逐步构建生命健康、生态环境、气象水文等领域的科学数据端云分析服务,已应用于中国科学院战略先导专项A、中国科学院战略先导专项B、国家烟草专卖局重大专项等重大项目;已应用于国家微生物科学数据中心、国家空间科学数据中心等国家科学数据中心;已应用于地理空间数据云、DarwinTree分子数据与应用环境等领域公共平台。并提供面向R、TensorFlow、Data Science、All Spark等的常用工具服务,用户可以https的方式访问交互编程组件(iJupyter)或交互应用组件(iWorkflow),即可使用数据端的数据资源和计算资源。