Frontiers of Data and Computing ›› 2024, Vol. 6 ›› Issue (5): 66-79.
CSTR: 32002.14.jfdc.CN10-1649/TP.2024.05.007
doi: 10.11871/jfdc.issn.2096-742X.2024.05.007
Previous Articles Next Articles
YAN Zhiyu1( ),RU Yiwei2,SUN Fupeng3,SUN Zhenan2,*()
),RU Yiwei2,SUN Fupeng3,SUN Zhenan2,*()
Received:2023-08-09
Online:2024-10-20
Published:2024-10-21
YAN Zhiyu, RU Yiwei, SUN Fupeng, SUN Zhenan. Research on Video Behavior Recognition Method with Active Perception Mechanism[J]. Frontiers of Data and Computing, 2024, 6(5): 66-79, https://cstr.cn/32002.14.jfdc.CN10-1649/TP.2024.05.007.
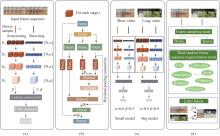
Fig.1
The proposed methods: (a) Spatial-temporal multiscale initiative; (b) Self-attention initiative of the sensing area; (c) Dynamically configure the sensor parameters; (d) Active sampling of sample amplification"

Table 1
Active Perception Machine (APM) base model"
| 审视分支 | 输出大小 | 浏览分支 | 输出大小 | |
|---|---|---|---|---|
| stride | stride | |||
投影维度 stride | 投影维度 stride | |||

Fig.2
Video frame sampling mode"
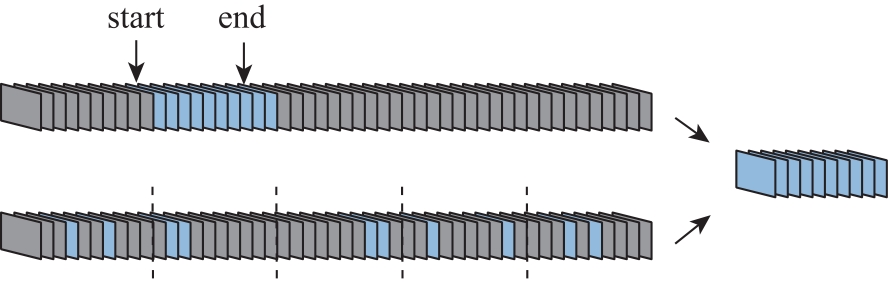
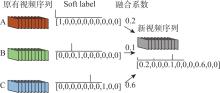
Fig.3
Label fusion mode"
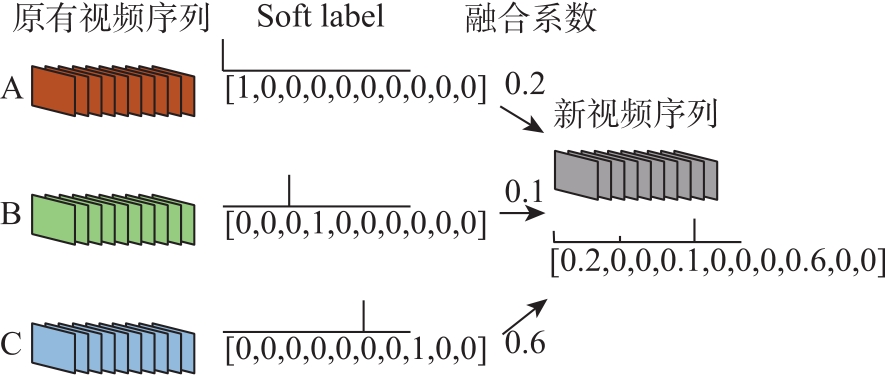
Table 2
Comparison of performance with existing algorithms on the Kinetics-400 dataset"
| 模型 | 预训练 | top-1 | top-5 | GFLOPs×views | Param |
|---|---|---|---|---|---|
| I3D[ | ImageNet | 72.1 | 90.3 | 108×N/A | 12M |
| Two-Stream I3D[ | ImageNet | 75.7 | 92.0 | 216×N/A | 25M |
| MF-Net[ | ImageNet | 72.8 | 90.4 | 11.1×50 | 8.0M |
| TSM R50[ | ImageNet | 74.7 | N/A | 65×10 | 24.3M |
| Nonlocal R50[ | ImageNet | 76.5 | 92.6 | 282×30 | 35.3M |
| Nonlocal R101[ | ImageNet | 77.7 | 93.3 | 359×30 | 54.3M |
| APGN[ | ImageNet | 77.7 | 93.4 | - | 27.6M |
| Two-Stream I3D[ | - | 71.6 | 90.0 | 216×N/A | 25M |
| R(2+1)D[ | - | 72.0 | 90.0 | 152×115 | 63.6M |
| Two-Stream R(2+1)D[ | - | 73.9 | 90.9 | 304×115 | 127.2M |
| Oct-I3D + NL[ | - | 75.7 | N/A | 28.9×30 | 33.6M |
| ip-CSN-152[ | - | 77.8 | 92.8 | 109×30 | 32.8M |
| X3D-M[ | - | 76.0 | 92.3 | 6.2×30 | 3.8M |
| X3D-XL[ | - | 79.1 | 93.9 | 48.4×30 | 11.0M |
| SlowFast 4×16,R50[ | - | 75.6 | 92.1 | 36.1×30 | 34.4M |
| SlowFast 8×8,R101[ | - | 77.9 | 93.2 | 106×30 | 53.7M |
| SlowFast 8×8,R101+NL[ | - | 78.7 | 93.5 | 116×30 | 59.9M |
| SlowFast 16×8,R101+NL[ | - | 79.8 | 93.9 | 234×30 | 59.9M |
| MViTv1,16×4[ | - | 78.4 | 93.5 | 70.3×5 | 36.6M |
| MViTv1,32×3[ | - | 80.2 | 94.4 | 170×5 | 36.6M |
| MViTv2-S,16×4[ | - | 81.0 | 94.6 | 64×5 | 34.5M |
| MViTv2-B,32×3[ | - | 82.9 | 95.7 | 225×5 | 51.2M |
| APM-1-K400 (Ours) | - | 82.5 | 94.3 | 57.6×5 | 31.1M |
| APM-2-K400 (Ours) | - | 83.1 | 95.1 | 177×5 | 46.2M |
| APM-3-K400 (Ours) | - | 83.2 | 95.8 | 215×5 | 58.6M |
Table 3
Comparison of performance with existing algorithms on the Kinetics-600 dataset"
| 模型 | 预训练 | top-1 | top-5 | GFLOPs×views | Param |
|---|---|---|---|---|---|
| I3D[ | - | 71.9 | 90.1 | 108×N/A | 12M |
| SlowFast 16×8,R101+NL[ | - | 81.8 | 95.1 | 234×30 | 59.9M |
| X3D-M[ | - | 78.8 | 94.5 | 6.2×30 | 3.8M |
| X3D-XL[ | - | 81.9 | 95.5 | 48.4×30 | 11.0M |
| MoViNet-A6[ | - | 84.8 | 96.5 | 386×1 | 31.4M |
| ViT-B-TimeSformer[ | ImageNet | 82.4 | 96.0 | 1,703×3 | 121.4M |
| ViT-L-ViViT[ | ImageNet | 83.0 | 95.7 | 3992×12 | 310.8M |
| Swim-B[ | ImageNet | 84.0 | 96.5 | 282×12 | 88.1M |
| Swim-L[ | ImageNet | 86.1 | 97.3 | 2107×50 | 200.0M |
| MViTv1,16×4[ | - | 82.1 | 95.5 | 70.5×5 | 36.8M |
| MViTv1,32×3[ | - | 83.4 | 96.3 | 170×5 | 36.8M |
| MViTv2-B,32×3[ | - | 85.5 | 97.2 | 206×5 | 51.4M |
| APM-1-K600 (Ours) | - | 82.4 | 95.6 | 58.3×5 | 32.4M |
| APM-2-K600 (Ours) | - | 83.3 | 96.6 | 178×5 | 46.8M |
| APM-3-K600 (Ours) | - | 85.8 | 97.5 | 215.5×5 | 59.4M |
Table 4
The top-1 accuracy using different fusion strategies on the Kinetics-400 dataset"
| α β | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 |
|---|---|---|---|---|---|---|---|---|---|
| 0.1 | 77.61 | 76.44 | 75.28 | 74.12 | 72.95 | 71.79 | 70.62 | 69.46 | 68.30 |
| 0.2 | 78.41 | 77.56 | 76.72 | 75.87 | 75.02 | 74.17 | 73.33 | 72.48 | 71.63 |
| 0.3 | 79.05 | 78.53 | 78.00 | 77.47 | 76.94 | 76.42 | 75.89 | 75.36 | 74.84 |
| 0.4 | 80.49 | 80.02 | 79.54 | 79.07 | 78.59 | 78.11 | 77.64 | 77.16 | 76.69 |
| 0.5 | 79.83 | 79.62 | 79.42 | 79.21 | 79.01 | 78.80 | 78.60 | 78.40 | 78.19 |
| 0.6 | 80.11 | 80.05 | 79.99 | 79.92 | 79.86 | 79.80 | 79.74 | 79.68 | 79.62 |
| 0.7 | 80.09 | 80.15 | 80.22 | 80.29 | 80.35 | 80.42 | 80.49 | 80.55 | 80.62 |
| 0.8 | 80.32 | 80.48 | 80.64 | 80.80 | 80.96 | 81.12 | 81.28 | 81.44 | 81.60 |
| 0.9 | 80.47 | 80.72 | 80.98 | 81.23 | 81.48 | 81.73 | 81.99 | 82.24 | 82.49 |
Table 5
The results of two branches using different structures on the Kinetics-400 dataset"
| 模型 | top-1 | top-5 | |
|---|---|---|---|
| MViTv2 32×3, MViTv2 16×4 | 0.3 | 83.11 | 95.07 |
| MVITv2 32×3, MVITv1 32×3 | 0.21 | 83.14 | 95.73 |
| MVITv2 32×3, SlowFast 4×16, R50 | 0.02 | 82.98 | 95.64 |
| MVITv2 32×3, SlowFast 8×8, R50 | 0.07 | 83.11 | 95.52 |
| MViTv2 16×4, SlowFast 4×16, R50 | 0.06 | 81.21 | 94.73 |
| MViTv2 16×4, SlowFast 8×8, R50 | 0.09 | 81.47 | 94.75 |
| SlowFast 4×16,R50, SlowFast 8×8, R50 | 0.49 | 77.16 | 92.39 |
Table 6
Specific structural design of different APM models"
| 审视分支 | 浏览分支 | |
|---|---|---|
| D | ||
| S1 | ||
| S2 | ||
| S3 | ||
| S4 | ||
| (a) APM-1模型结构 | ||
| 审视分支 | 浏览分支 | |
| D | ||
| S1 | ||
| S2 | ||
| S3 | ||
| S4 | ||
| (b) APM-2模型结构 | ||
| 审视分支 | 浏览分支 | |
| D | ||
| S1 | ||
| S2 | ||
| S3 | ||
| S4 | ||
| (c) APM-3模型结构 | ||
| [1] | SUN Z, KE Q, RAHMANI H, et al. Human action recognition from various data modalities: A review[J]. IEEE transactions on pattern analysis and machine intelligence, 2022, 45(3): 3200-3225. |
| [2] | LIU T, MA Y, YANG W, et al. Spatial-temporal interaction learning based two-stream network for action recognition[J]. Information Sciences, 2022, 606: 864-876. |
| [3] | HUANG Y, GUO Y, GAO C. Efficient parallel inflated 3D convolution architecture for action recognition[J]. IEEE Access, 2020, 8: 45753-45765. |
| [4] | FEICHTENHOFER C, FAN H, MALIK J, et al. Slowfast networks for video recognition[C]// Proceedings of the IEEE/CVF international conference on computer vision, 2019: 6202-6211. |
| [5] | ARNAB A, DEHGHANI M, HEIGOLD G, et al. Vivit: A video vision transformer[C]// Proceedings of the IEEE/CVF international conference on computer vision, 2021: 6836-6846. |
| [6] | BERTASIUS G, WANG H, TORRESANI L. Is space-time attention all you need for video understanding?[C]// ICML, 2021, 2(3): 4. |
| [7] | ZHENG Z, AN G, WU D, et al. Global and local knowledge-aware attention network for action recognition[J]. IEEE transactions on neural networks and learning systems, 2020, 32(1): 334-347. |
| [8] | CHEN J, HO C M. MM-ViT: Multi-modal video transformer for compressed video action recognition[C]// Proceedings of the IEEE/CVF winter conference on applications of computer vision, 2022: 1910-1921. |
| [9] | ZHU Y, LAN Z, NEWSAM S, et al. Hidden two-stream convolutional networks for action recognition[C]// Computer Vision-ACCV 2018: 14th Asian Conference on Computer Vision, Perth, Australia, December 2-6, 2018, Revised Selected Papers, Part III 14. Springer International Publishing, 2019: 363-378. |
| [10] | WEI D, TIAN Y, WEI L, et al. Efficient dual attention slowfast networks for video action recognition[J]. Computer Vision and Image Understanding, 2022, 222: 103484. |
| [11] | LI Y, WU C Y, FAN H, et al. MViTv2: Improved Multiscale Vision Transformers for Classification and Detection[C]// Computer Vision and Pattern Recognition, 2022: 4794-4804. |
| [12] | DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv:2010. 11929, 2020: 1-1. |
| [13] | SIMONYAN K, ZISSERMAN A. Two-stream convolutional networks for action recognition in videos[J]. Advances in neural information processing systems, 2014, 1: 568-576. |
| [14] | WANG L, XIONG Y, WANG Z, et al. Temporal segment networks: Towards good practices for deep action recognition[C]// European conference on computer vision, Springer, Cham, 2016: 20-36. |
| [15] | GIRDHAR R, RAMANAN D, GUPTA A, et al. Actionvlad: Learning spatio-temporal aggregation for action classification[C]// Proceedings of the IEEE conference on computer vision and pattern recognition, 2017: 971-980. |
| [16] | DIBA A, SHARMA V, VAN GOOL L. Deep temporal linear encoding networks[C]// Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2017: 2329-2338. |
| [17] | FEICHTENHOFER C, PINZ A, WILDES R P. Spatiotemporal multiplier networks for video action recognition[C]// Proceedings of the IEEE conference on computer vision and pattern recognition, 2017: 4768-4777. |
| [18] | CHEN Y, GE H, LIU Y, et al. AGPN: Action Granularity Pyramid Network for Video Action Recognition[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2023: 1-1. |
| [19] | BACCOUCHE M, MAMALET F, WOLF C, et al. Sequential deep learning for human action recognition[C]// Human Behavior Understanding: Second International Workshop, HBU 2011, Amsterdam, The Netherlands, November 16, 2011. Proceedings 2. Springer Berlin Heidelberg, 2011: 29-39. |
| [20] | TRAN D, BOURDEV L, FERGUS R, et al. Learning spatiotemporal features with 3d convolutional networks[C]// Proceedings of the IEEE international conference on computer vision, 2015: 4489-4497. |
| [21] | CARREIRA J, ZISSERMAN A. Quo vadis, action recognition? a new model and the kinetics dataset[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 6299-6308. |
| [22] | TRAN D, WANG H, TORRESANI L, et al. A closer look at spatiotemporal convolutions for action recognition[C]// Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2018: 6450-6459. |
| [23] | ZHOU Y, SUN X, ZHA Z J, et al. Mict: Mixed 3d/2d convolutional tube for human action recognition[C]// Proceedings of the IEEE conference on computer vision and pattern recognition, 2018: 449-458. |
| [24] | DU W, WANG Y, QIAO Y. Rpan: An end-to-end recurrent pose-attention network for action recognition in videos[C]// Proceedings of the IEEE international conference on computer vision, 2017: 3725-3734. |
| [25] | SUN L, JIA K, CHEN K, et al. Lattice long short-term memory for human action recognition[C]// Proceedings of the IEEE international conference on computer vision, 2017: 2147-2156. |
| [26] | PERRETT T, DAMEN D. DDLSTM: dual-domain LSTM for cross-dataset action recognition[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 7852-7861. |
| [27] | MENG Y, LIN C C, PANDA R, et al. Ar-net: Adaptive frame resolution for efficient action recognition[C]//Computer Vision-ECCV 2020: 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings, Part VII 16. Springer International Publishing, 2020: 86-104. |
| [28] | DONAHUE J, ANNE HENDRICKS L, GUADARR-AMA S, et al. Long-term recurrent convolutional networks for visual recognition and description[C]// Proceedings of the IEEE conference on computer vision and pattern recognition, 2015: 2625-2634. |
| [29] | SHI Y, TIAN Y, WANG Y, et al. Learning long-term dependencies for action recognition with a biologi-cally-inspired deep network[C]// Proceedings of the IEEE International Conference on Computer Vision, 2017: 716-725. |
| [30] | DWIBEDI D, SERMANET P, TOMPSON J. Temporal reasoning in videos using convolutional gated recurrent units[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2018: 1111-1116. |
| [31] | KIM P S, LEE D G, LEE S W. Discriminative context learning with gated recurrent unit for group activity recognition[J]. Pattern Recognition, 2018, 76: 149- 161. |
| [32] | CHO K, VAN MERRIËNBOER B, GULCEHRE C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[J]. arXiv preprint arXiv:1406.1078, 2014: 1-1. |
| [33] | ZHANG M, YANG Y, JI Y, et al. Recurrent attention network using spatial-temporal relations for action recognition[J]. Signal Processing, 2018, 145: 137-145. |
| [34] | ZHANG J, HU H, LU X. Moving foreground-aware visual attention and key volume mining for human action recognition[J]. ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), 2019, 15(3): 1-16. |
| [35] | SHARMA S, KIROS R, SALAKHUTDINOV R. Action recognition using visual attention[J]. arXiv preprint arXiv:1511.04119, 2015:1-1. |
| [36] | GIRDHAR R, RAMANAN D. Attentional pooling for action recognition[J]. Advances in neural information processing systems, 2017, 30. |
| [37] | LI Z, GAVRILYUK K, GAVVES E, et al. Videolstm convolves, attends and flows for action recognition[J]. Computer Vision and Image Understanding, 2018, 166: 41-50. |
| [38] | PENG Y, ZHAO Y, ZHANG J. Two-stream collaborative learning with spatial-temporal attention for video classification[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2018, 29(3): 773-786. |
| [39] | FU J, GAO J, XU C. Learning semantic-aware spatial-temporal attention for interpretable action recognition[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2021, 32(8): 5213-5224. |
| [40] | NEIMARK D, BAR O, ZOHAR M, et al. Video transformer network[C]// Proceedings of the IEEE/CVF international conference on computer vision, 2021: 3163-3172. |
| [41] | BULAT A, PEREZ RUA J M, SUDHAKARAN S, et al. Space-time mixing attention for video transformer[J]. Advances in neural information processing systems, 2021, 34: 19594-19607. |
| [42] | ZHA X, ZHU W, XUN L, et al. Shifted chunk transformer for spatio-temporal representational learning[J]. Advances in Neural Information Processing Systems, 2021, 34: 11384-11396. |
| [43] | GUO H, WANG H, JI Q. Uncertainty-guided probabilistic transformer for complex action recognition[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 20052-20061. |
| [44] | LIU C, LI X, CHEN H, et al. Selective feature compression for efficient activity recognition inference[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021: 13628-13637. |
| [45] | YANG J, DONG X, LIU L, et al. Recurring the transformer for video action recognition[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 14063-14073. |
| [46] | PAN B, PANDA R, JIANG Y, et al. IA-RED $^ 2$: Interpretability-Aware Redundancy Reduction for Vision Transformers[J]. Advances in Neural Information Processing Systems, 2021, 34: 24898-24911. |
| [47] | LIU Q, CHE X, BIE M. R-STAN: Residual spatial-temporal attention network for action recognition[J]. IEEE Access, 2019, 7: 82246-82255. |
| [48] | FAN H, XIONG B, MANGALAM K, et al. Multiscale vision transformers[C]// Proceedings of the IEEE/CVF international conference on computer vision, 2021: 6824-6835. |
| [49] | ZHANG H, CISSE M, DAUPHIN Y N, et al. mixup: Beyond empirical risk minimization[J]. arXiv preprint arXiv:1710.09412, 2017: 1-1. |
| [50] | CHEN Y, KALANTIDIS Y, LI J, et al. Multi-fiber networks for video recognition[C]// Proceedings of the european conference on computer vision (ECCV), 2018: 352-367. |
| [51] | LIN J, GAN C, HAN S. Tsm: Temporal shift module for efficient video understanding[C]// Proceedings of the IEEE/CVF international conference on computer vision, 2019: 7083-7093. |
| [52] | WANG X, GIRSHICK R, GUPTA A, et al. Non-local neural networks[C]// Proceedings of the IEEE conference on computer vision and pattern recognition, 2018: 7794-7803. |
| [53] | CHEN Y, FAN H, XU B, et al. Drop an octave: Reducing spatial redundancy in convolutional neural networks with octave convolution[C]// Proceedings of the IEEE/CVF international conference on computer vision, 2019: 3435-3444. |
| [54] | TRAN D, WANG H, TORRESANI L, et al. Video classification with channel-separated convolutional networks[C]// Proceedings of the IEEE/CVF international conference on computer vision, 2019: 5552-5561. |
| [55] | FEICHTENHOFER C. X3d: Expanding architectures for efficient video recognition[C]// Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020: 203-213. |
| [56] | KAY W, CARREIRA J, SIMONYAN K, et al. The kinetics human action video dataset[J]. arXiv preprint arXiv:1705.06950, 2017: 1-1. |
| [57] | CARREIRA J, NOLAND E, BANKI-HORVATH A, et al. A short note about kinetics-600[J]. arXiv preprint arXiv:1808.01340, 2018: 1-1. |
| [58] | KONDRATYUK D, YUAN L, LI Y, et al. Movinets: Mobile video networks for efficient video recognition[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 16020-16030. |
| [59] | LIU Z, NING J, CAO Y, et al. Video swin transformer[C]// Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022: 3202-3211. |
| [1] | ZHENG Siming, ZHU Mingyu, YUAN Xin, YANG Xiaoyu. Video Snapshot Compressive Imaging Based on Elastic Weight Consolidation [J]. Frontiers of Data and Computing, 2024, 6(5): 111-125. |
| [2] | SONG Heng, HU Nan, GENG Tianbao, CHENG Weiguo, ZHANG Huan. Research on Intelligent Interpretation Method of Shock Elastic Wave Detection Signal of Grouting Compactness [J]. Frontiers of Data and Computing, 2024, 6(4): 163-172. |
| [3] | LIAO Libo, WANG Shudong, SONG Weimin, ZHANG Zhaoling, LI Gang, HUANG Yongsheng. The Study of Jet Tagging Algorithm Based on DeepSets at CEPC [J]. Frontiers of Data and Computing, 2024, 6(3): 108-115. |
| [4] | YAN Jin, DONG Kejun, LI Hongtao. A Deep Web Tracker Detection Method with Coordinated Semantic and Co-Occurrence Features [J]. Frontiers of Data and Computing, 2024, 6(3): 127-138. |
| [5] | KOU Dazhi. Automatic Teeth Segmentation on Dental Panoramic Radiographs with Deep Learning [J]. Frontiers of Data and Computing, 2024, 6(3): 162-172. |
| [6] | CAI Chengfei, LI Jun, JIAO Yiping, WANG Xiangxue, GUO Guanchen, XU Jun. Progress and Challenges of Medical Multimodal Data Fusion Methods Based on Deep Learning in Oncology [J]. Frontiers of Data and Computing, 2024, 6(3): 3-14. |
| [7] | ZHENG Yinuo, SUN Muyi, ZHANG Hongyun, ZHANG Jing, DENG Tianzheng, LIU Qian. Application of Deep Learning in Dental Implant Imaging: Research Progress and Challenges [J]. Frontiers of Data and Computing, 2024, 6(3): 41-49. |
| [8] | YUAN Jialin, OUYANG Rushan, DAI Yi, LAI Xiaohui, MA Jie, GONG Jingshan. Assessing the Clinical Utility of a Deep Learning-Based Model for Calcification Recognition and Classification in Mammograms [J]. Frontiers of Data and Computing, 2024, 6(2): 68-79. |
| [9] | LI Haopeng, ZHOU Wanting, CHEN Yu, ZHANG Man. Domain Independent Cycle-GAN for Cross Modal Medical Image Generation [J]. Frontiers of Data and Computing, 2024, 6(2): 80-88. |
| [10] | GUO Guanchen, LI Jun, CAI Chengfei, JIAO Yiping, XU Jun. Causal Restraint Transformer for Medical Image Segmentation [J]. Frontiers of Data and Computing, 2024, 6(2): 89-100. |
| [11] | WANG Ziyuan, WANG Guozhong. Application of Improved Lightweight YOLOv5 Algorithm in Pedestrian Detection [J]. Frontiers of Data and Computing, 2023, 5(6): 161-172. |
| [12] | JU Jiaji, HUANG Bo, ZHANG Shuai, GUO Ruyan. A Dual-Channel Sentiment Analysis Model Integrating Sentiment Lexcion and Self-Attention [J]. Frontiers of Data and Computing, 2023, 5(4): 101-111. |
| [13] | LI JunFei, XU LiMing, WANG Yang, WEI Xin. Review of Automatic Citation Classification Based on Deep Learning Technology [J]. Frontiers of Data and Computing, 2023, 5(4): 86-100. |
| [14] | CHEN Dong, LI Ming, CHEN Shuwen. Hyperspectral Image Classification Method Combining Transformer and Multi-Layer Feature Aggregation [J]. Frontiers of Data and Computing, 2023, 5(3): 138-151. |
| [15] | LI Yan,HE Hongbo,WANG Runqiang. A Survey of Research on Microblog Popularity Prediction [J]. Frontiers of Data and Computing, 2023, 5(2): 119-135. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||