Frontiers of Data and Computing ›› 2024, Vol. 6 ›› Issue (5): 111-125.
CSTR: 32002.14.jfdc.CN10-1649/TP.2024.05.011
doi: 10.11871/jfdc.issn.2096-742X.2024.05.011
Previous Articles Next Articles
ZHENG Siming1,2( ),ZHU Mingyu3,YUAN Xin3,YANG Xiaoyu1,2,*()
),ZHU Mingyu3,YUAN Xin3,YANG Xiaoyu1,2,*()
Received:2023-04-03
Online:2024-10-20
Published:2024-10-21
ZHENG Siming, ZHU Mingyu, YUAN Xin, YANG Xiaoyu. Video Snapshot Compressive Imaging Based on Elastic Weight Consolidation[J]. Frontiers of Data and Computing, 2024, 6(5): 111-125, https://cstr.cn/32002.14.jfdc.CN10-1649/TP.2024.05.011.
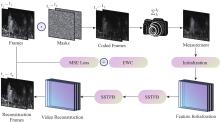
Fig.1
Illustration of the video SCI framework"
Fig.2
Based on EWC the network can adapt flexibly to different compression ratios"
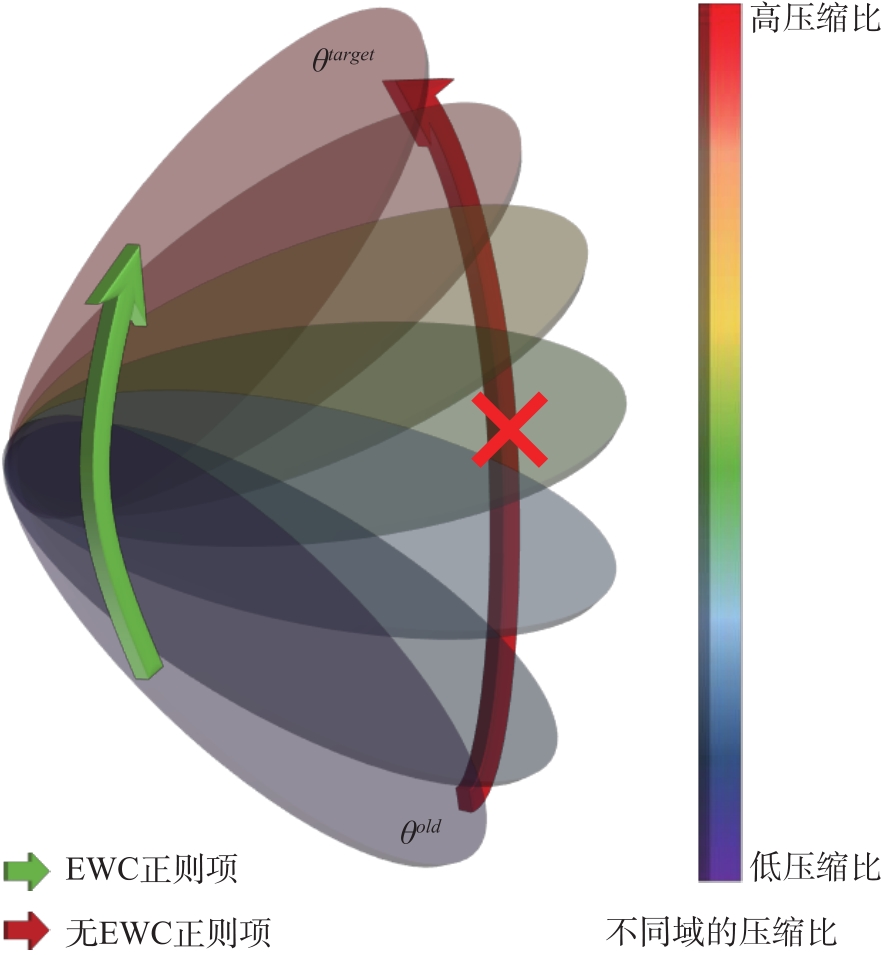
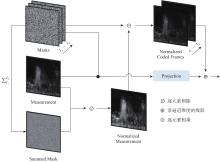
Fig.3
Initialization of network input"
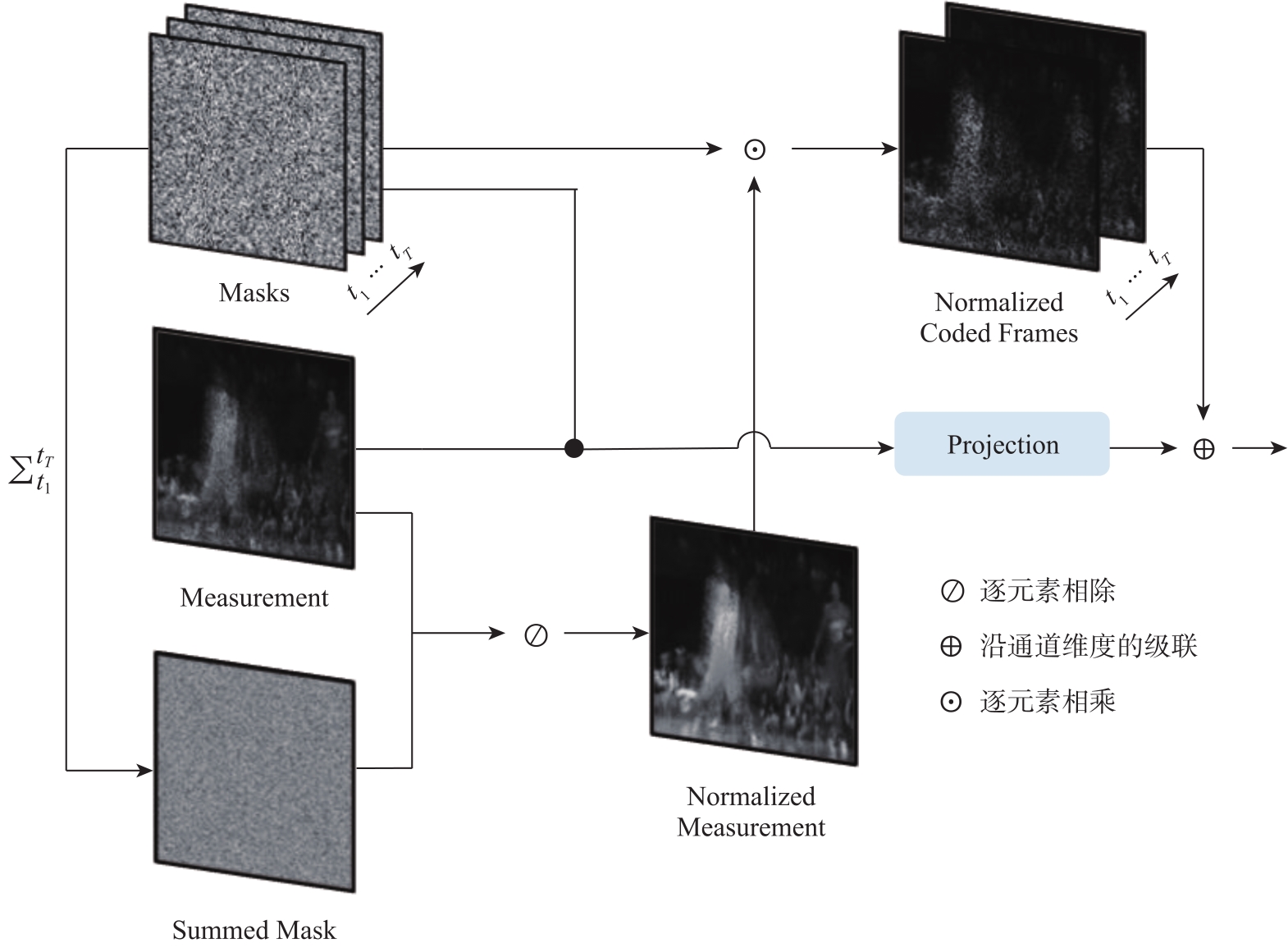
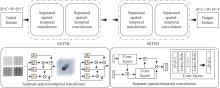
Fig.4
Structural diagram of the Spatio-Temporal Forward Backward (SSTFB) module"
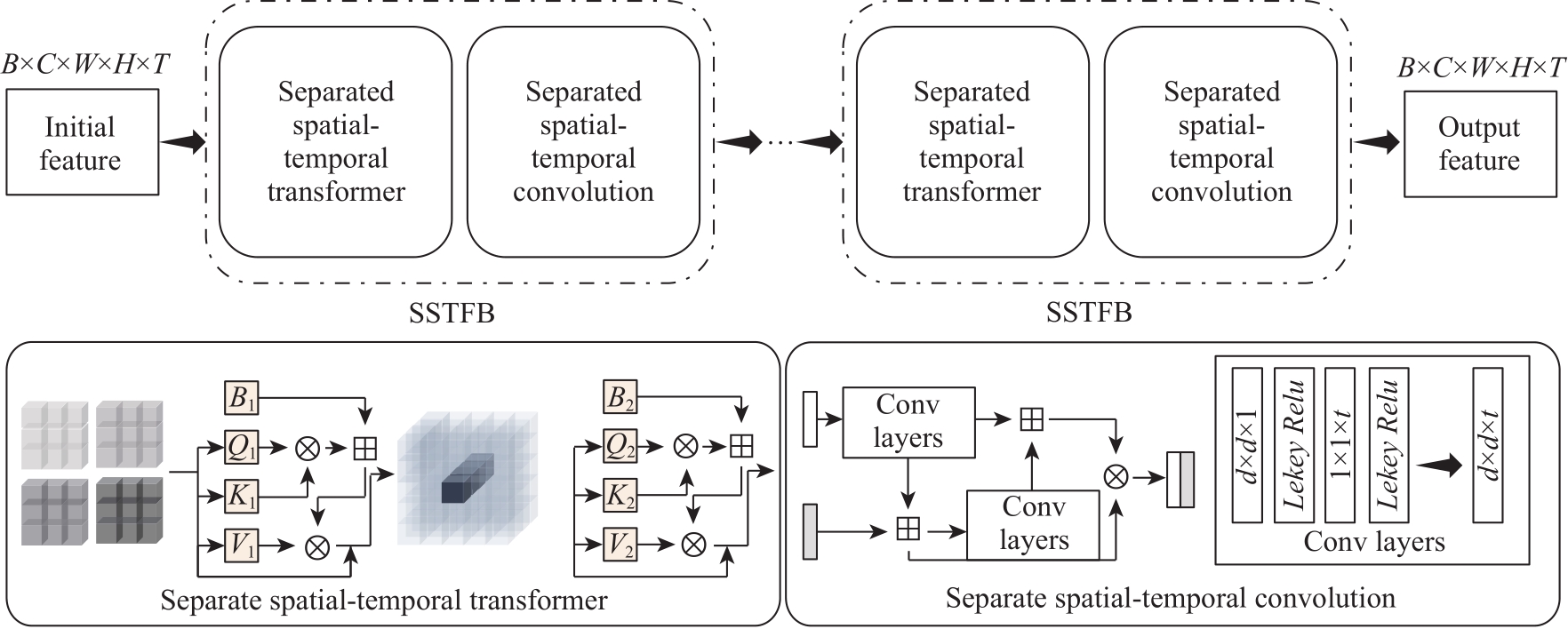
Table 1
Quantitative comparison of different algorithms in the grayscale SCI system"
| 数据集 | Kobe | Traffic | Runner | Drop | Aerial | Crash | Average | 运行时间 |
|---|---|---|---|---|---|---|---|---|
| 评价指标 | PSNR SSIM | PSNR SSIM | PSNR SSIM | PSNR SSIM | PSNR SSIM | PSNR SSIM | PSNR SSIM | 秒(s) |
| GAP-TV[ | 26.45 0.845 | 20.90 0.715 | 28.48 0.899 | 33.81 0.963 | 25.03 0.828 | 24.82 0.838 | 26.58 0.848 | 4.2 |
| E2E-CNN[ | 27.79 0.807 | 24.62 0.840 | 34.12 0.947 | 26.56 0.949 | 27.18 0.869 | 26.43 0.882 | 29.45 0.882 | 0.0312 |
| DeSCI[ | 33.25 0.952 | 28.72 0.925 | 38.76 0.969 | 43.22 0.993 | 25.33 0.860 | 27.04 0.909 | 32.72 0.935 | 6180 |
| PnP-FFDNet[ | 30.47 0.926 | 24.08 0.833 | 32.88 0.938 | 40.87 0.988 | 24.02 0.814 | 24.32 0.836 | 29.44 0.889 | 3.0 |
| PnP-FastDVDNet[ | 32.73 0.946 | 27.95 0.932 | 36.29 0.962 | 41.82 0.989 | 27.98 0.897 | 27.32 0.925 | 32.35 0.942 | 18 |
| BIRNAT[ | 32.71 0.950 | 29.33 0.942 | 38.70 0.976 | 42.28 0.992 | 28.99 0.927 | 27.84 0.927 | 33.31 0.951 | 0.16 |
| GAP-Unet-S12 | 32.09 0.944 | 28.19 0.929 | 38.12 0.975 | 42.02 0.992 | 28.88 0.914 | 27.83 0.931 | 32.86 0.947 | 0.0072 |
| MetaSCI[ | 30.12 0.907 | 26.95 0.888 | 37.02 0.967 | 40.61 0.985 | 28.31 0.904 | 27.33 0.906 | 31.72 0.926 | 0.025 |
| RevSCI[ | 33.72 0.957 | 30.03 0.949 | 39.40 0.977 | 42.93 0.992 | 29.35 0.924 | 28.12 0.937 | 33.92 0.956 | 0.19 |
| DUN-3DUnet[ | 35.00 0.969 | 31.76 0.966 | 40.90 0.983 | 44.46 0.994 | 30.64 0.943 | 29.35 0.955 | 35.32 0.968 | 1.35 |
| ELP-Unfolding[ | 24.41 0.966 | 31.58 0.962 | 41.16 0.986 | 44.99 0.995 | 30.68 0.943 | 29.65 0.960 | 35.41 0.969 | 0.24 |
| Ours | 35.48 0.985 | 31.95 0.979 | 41.17 0.994 | 45.12 0.998 | 31.41 0.968 | 30.95 0.978 | 36.02 0.984 | 1.15 |

Fig.5
Partial reconstruction results of different algorithms on the simulated benchmark test set"

Table 2
Flexibility of masks: Quantitative comparison of different algorithms with different masks but with the same spatial size. PSNR (dB) and SSIM are chosen as evaluation metrics"
| 算法 | Ours | DUN-3DUnet | MetaSCI |
|---|---|---|---|
| 评价指标 | PSNR SSIM | PSNR SSIM | PSNR SSIM |
| 训练中使用掩码 | 36.02 0.985 | 35.26 0.968 | 31.72 0.926 |
| 新任务1 | 36.01 0.985 | 31.74 0.937 | 31.71 0.926 |
| 新任务2 | 36.03 0.985 | 31.66 0.937 | 31.68 0.925 |
Table 3
Large-scale data (compression ratio: 8): Quantitative comparison of existing algorithms applicable to large-scale data. The best results are shown in bold, and the second-best results are shown underlined. PSNR (dB) and SSIM are chosen as evaluation metrics"
| 数据尺寸 | 算法 | Beauty | Bosphorus | HoneyBee | Jockey | ShakeNDry | Average | 运行时间 |
|---|---|---|---|---|---|---|---|---|
| 评价指标 | PSNR SSIM | PSNR SSIM | PSNR SSIM | PSNR SSIM | PSNR SSIM | PSNR SSIM | PSNR SSIM | 秒(s) |
| 512x512 | GAP-TV[ | 32.13 0.857 | 29.18 0.934 | 31.40 0.887 | 31.01 0.940 | 32.52 0.882 | 31.25 0.900 | 44.67 |
| PnP-FFDNet[ | 30.70 0.855 | 35.36 0.952 | 31.94 0.872 | 34.88 0.955 | 30.72 0.875 | 32.72 0.902 | 14.22 | |
| MetaSCI[ | 35.10 0.901 | 38.37 0.950 | 34.27 0.913 | 36.45 0.962 | 33.16 0.901 | 35.47 0.925 | 0.12 | |
| Ours | 41.32 0.983 | 42.04 0.989 | 43.62 0.991 | 41.57 0.988 | 37.25 0.965 | 41.16 0.983 | 4.67 | |
| 数据尺寸 | 算法 | Beauty | Bosphorus | HoneyBee | Jockey | ShakeNDry | Average | 测试时间 |
| 1024x1024 | GAP-TV[ | 33.59 0.852 | 33.27 0.971 | 33.86 0.913 | 27.49 0.948 | 24.39 0.937 | 30.52 0.924 | 178.11 |
| PnP-FFDNet[ | 32.36 0.857 | 35.25 0.976 | 32.21 0.902 | 31.87 0.965 | 30.77 0.967 | 32.49 0.933 | 52.47 | |
| MetaSCI[ | 35.23 0.929 | 37.15 0.978 | 36.06 0.939 | 33.34 0.973 | 32.68 0.955 | 34.89 0.955 | 0.59 | |
| Ours | 40.38 0.979 | 42.15 0.989 | 39.04 0.978 | 40.09 0.989 | 37.53 0.982 | 39.84 0.983 | 19.93 | |
| 数据尺寸 | 算法 | City | Kids | Lips | RaceNight | RiverBank | Average | 测试时间 |
| 2048x2048 | GAP-TV[ | 21.27 0.902 | 26.05 0.956 | 26.46 0.890 | 26.81 0.875 | 27.74 0.848 | 25.67 0.894 | 764.75 |
| PnP-FFDNet[ | 29.31 0.926 | 30.01 0.966 | 27.99 0.902 | 31.18 0.891 | 30.38 0.888 | 29.77 0.915 | 205.62 | |
| MetaSCI[ | 32.63 0.930 | 32.31 0.965 | 30.90 0.895 | 33.86 0.893 | 32.77 0.902 | 32.49 0.917 | 2.38 | |
| Ours | 40.07 0.982 | 40.15 0.984 | 35.55 0.934 | 36.53 0.956 | 36.80 0.970 | 37.82 0.965 | 79.71 |
Table 4
Parameter count of different algorithms"
| 算法 | Ours | ELP-Unfolding | DUN-3DUnet |
|---|---|---|---|
| 参数量 | 34.06M | 565.60M | 61.89M |
Table 5
Quantization results comparison of our model at different compression ratios. PSNR (dB) and SSIM are chosen as evaluation metrics"
| 压缩比 | 8 | 16 | 24 | 32 | 平均值 |
|---|---|---|---|---|---|
| 评价指标 | PSNR SSIM | PSNR SSIM | PSNR SSIM | PSNR SSIM | PSNR SSIM |
| 压缩比为8的模型 | 36.02 0.985 | 23.38 0.847 | 21.30 0.785 | 20.16 0.747 | 25.22 0.841 |
| 引入EWC的模型 | 31.64 0.964 | 30.84 0.955 | 30.81 0.950 | 30.06 0.940 | 30.83 0.952 |
| 压缩比为32的模型 | 30.13 0.955 | 30.52 0.952 | 30.64 0.948 | 30.01 0.939 | 30.32 0.948 |

Fig.6
Partial reconstruction results of our model under different compression ratios"

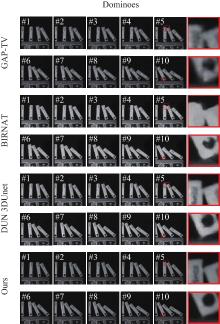
Fig.7
Partial video reconstruction frames of the real dataset "Dominoes""
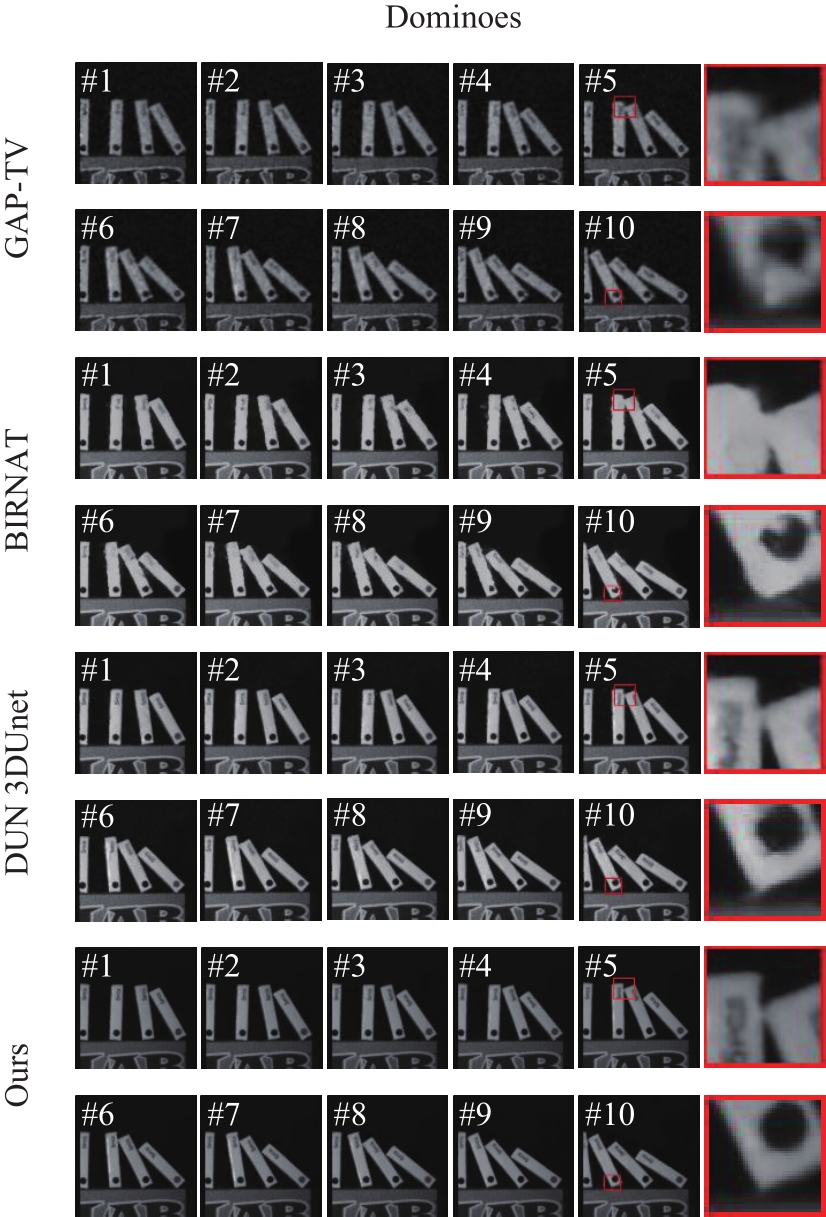

Fig.8
Partial video reconstruction frames of the real dataset "Water Balloon""

| [1] |
LLULL P, LIAO X, YUAN X, et al. Coded aperture compressive temporal imaging[J]. Optics express, 2013, 21(9): 10526-10545.
doi: 10.1364/OE.21.010526 pmid: 23669910 |
| [2] | YUAN X, LLULL P, LIAO X, et al. Low-cost compressive sensing for color video and depth[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2014: 3318-3325. |
| [3] | HITOMI Y, GU J, GUPTA M, et al. Video from a single coded exposure photograph using a learned over-complete dictionary[C]. Proceedings of the 2011 International Conference on Computer Vision, 2011: 287-294. |
| [4] | REDDY D, VEERARAGHAVAN A, CHELLAPPA R. P2C2: Programmable pixel compressive camera for high speed imaging[C]. Proceedings of the CVPR 2011, 2011: 329-336. |
| [5] | LIU Y, YUAN X, SUO J, et al. Rank minimization for snapshot compressive imaging[J]. IEEE transactions on pattern analysis and machine intelligence, 2018, 41(12): 2990-3006. |
| [6] | CHENG Z, CHEN B, LIU G, et al. Memory-efficient network for large-scale video compressive sensing[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 16246-16255. |
| [7] | YUAN X, BRADY D J, KATSAGGELOS A K. Snapshot compressive imaging: Theory, algorithms, and applications[J]. IEEE Signal Processing Magazine, 2021, 38(2): 65-88. |
| [8] | QIAO M, MENG Z, MA J, et al. Deep learning for video compressive sensing[J]. Apl Photonics, 2020, 5(3): 030801. |
| [9] | WANG Z, ZHANG H, CHENG Z, et al. Metasci: Scalable and adaptive reconstruction for video compressive sensing[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 2083-2092. |
| [10] | CHENG Z, LU R, WANG Z, et al. BIRNAT: Bidirectional recurrent neural networks with adversarial training for video snapshot compressive imaging[C]. Proceedings of the Computer Vision-ECCV 2020, 2020: 258-275. |
| [11] | SUN J, LI H, XU Z. Deep ADMM-Net for compressive sensing MRI[J]. Advances in neural information processing systems, 2016, 29. |
| [12] | YANG Y, SUN J, LI H, et al. ADMM-CSNet: A deep learning approach for image compressive sensing[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 42(3): 521-538. |
| [13] | WU Z, ZHANG J, MOU C. Dense deep unfolding network with 3d-cnn prior for snapshot compressive imaging[C]. Proceedings of the IEEE International Conference on Computer Vision, 2021: 4892-4901. |
| [14] | LI Y, QI M, GULVE R, et al. End-to-end video compressive sensing using anderson-accelerated unrolled networks[C]. Proceedings of the 2020 IEEE International Conference on Computational Photography (ICCP), 2020: 1-12. |
| [15] | ZHANG J, GHANEM B. ISTA-Net: Interpretable optimization-inspired deep network for image compressive sensing[C]. Proceedings of the IEEE conference on computer vision and pattern recognition, 2018: 1828-1837. |
| [16] | YUAN X. Generalized alternating projection based total variation minimization for compressive sensing[C]. Proceedings of the 2016 IEEE International conference on image processing (ICIP), 2016: 2539-2543. |
| [17] | YUAN X, LIU Y, SUO J, et al. Plug-and-play algorithms for large-scale snapshot compressive imaging[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 1447-1457. |
| [18] | YANG J, LIAO X, YUAN X, et al. Compressive sensing by learning a Gaussian mixture model from measurements[J]. IEEE Transactions on Image Processing, 2014, 24(1): 106-119. |
| [19] |
YANG J, YUAN X, LIAO X, et al. Video compressive sensing using Gaussian mixture models[J]. IEEE Transactions on Image Processing, 2014, 23(11): 4863-4878.
doi: 10.1109/TIP.2014.2344294 pmid: 25095253 |
| [20] | SHMELKOV K, SCHMID C, ALAHARI K. Incremental learning of object detectors without catastrophic forgetting[C]. Proceedings of the IEEE international conference on computer vision, 2017: 3400-3409. |
| [21] | CASTRO F M, MARíN-JIMéNEZ M J, GUIL N, et al. End-to-end incremental learning[C]. Proceedings of the European conference on computer vision (ECCV), 2018: 233-248. |
| [22] | RANNEN A, ALJUNDI R, BLASCHKO M B, et al. Encoder based lifelong learning[C]. Proceedings of the IEEE International Conference on Computer Vision, 2017: 1320-1328. |
| [23] | GUO Y, HU W, ZHAO D, et al. Adaptive orthogonal projection for batch and online continual learning[C]. Proceedings of the Proceedings of the AAAI Conference on Artificial Intelligence, 2022: 6783-6791. |
| [24] | ALJUNDI R, CHAKRAVARTY P, TUYTELAARS T. Expert gate: Lifelong learning with a network of experts[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 3366-3375. |
| [25] | ZHAI M, CHEN L, TUNG F, et al. Lifelong gan: Continual learning for conditional image generation[C]. Proceedings of the IEEE/CVF international conference on computer vision, 2019: 2759-2768. |
| [26] | WU C, HERRANZ L, LIU X, et al. Memory replay gans: Learning to generate new categories without forgetting[J]. Advances in Neural Information Processing Systems, 2018, 31. |
| [27] | KIRKPATRICK J, PASCANU R, RABINOWITZ N, et al. Overcoming catastrophic forgetting in neural networks[J]. Proceedings of the national academy of sciences, 2017, 114(13): 3521-3526. |
| [28] | DE LANGE M, ALJUNDI R, MASANA M, et al. A continual learning survey: Defying forgetting in classification tasks[J]. IEEE transactions on pattern analysis and machine intelligence, 2021, 44(7): 3366-3385. |
| [29] | LEE S-W, KIM J-H, JUN J, et al. Overcoming catastrophic forgetting by incremental moment matching[J]. Advances in neural information processing systems, 2017, 30. |
| [30] | LIU X, MASANA M, HERRANZ L, et al. Rotate your networks: Better weight consolidation and less catastrophic forgetting[C]. Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), 2018: 2262-2268. |
| [31] | ZENKE F, POOLE B, GANGULI S. Continual learning through synaptic intelligence[C]. Proceedings of the International conference on machine learning, 2017: 3987-3995. |
| [32] | HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]. Proceedings of the IEEE conference on computer vision and pattern recognition, 2016: 770-778. |
| [33] | HUANG G, LIU Z, VAN DER MAATEN L, et al. Densely connected convolutional networks[C]; Proceedings of the IEEE conference on computer vision and pattern recognition, 2017: 4700-4708. |
| [34] | KRIZHEVSKY A, SUTSKEVER I, HINTON G E. Imagenet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84-90. |
| [35] | LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324. |
| [36] | RONNEBERGER O, FISCHER P, BROX T. U-net: Convolutional networks for biomedical image segmentation[C]. Proceedings of the Medical Image Computing and Computer-Assisted Intervention-MICCAI 2015, 2015: 234-241. |
| [37] | JI S, XU W, YANG M, et al. 3D convolutional neural networks for human action recognition[J]. IEEE transactions on pattern analysis and machine intelligence, 2012, 35(1): 221-231. |
| [38] | TAYLOR G W, FERGUS R, LECUN Y, et al. Convolutional learning of spatio-temporal features[C]. Proceedings of the Computer Vision-ECCV 2010, 2010: 140-153. |
| [39] | SHOU Z, WANG D, CHANG S-F. Temporal action localization in untrimmed videos via multi-stage cnns[C]. Proceedings of the IEEE conference on computer vision and pattern recognition, 2016: 1049-1058. |
| [40] | PAN Y, MEI T, YAO T, et al. Jointly modeling embedding and translation to bridge video and language[C]. Proceedings of the IEEE conference on computer vision and pattern recognition, 2016: 4594-4602. |
| [41] | MOLCHANOV P, YANG X, GUPTA S, et al. Online detection and classification of dynamic hand gestures with recurrent 3d convolutional neural network[C]. Proceedings of the IEEE conference on computer vision and pattern recognition, 2016: 4207-4215. |
| [42] | TRAN D, BOURDEV L, FERGUS R, et al. Learning spatiotemporal features with 3d convolutional networks[C]. Proceedings of the IEEE international conference on computer vision, 2015: 4489-4497. |
| [43] | TRAN D, WANG H, TORRESANI L, et al. A closer look at spatiotemporal convolutions for action recognition[C]. Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2018: 6450-6459. |
| [44] | WANG X, GIRSHICK R, GUPTA A, et al. Non-local neural networks[C]. Proceedings of the IEEE conference on computer vision and pattern recognition, 2018: 7794-7803. |
| [45] | YIN M, YAO Z, CAO Y, et al. Disentangled non-local neural networks[C]. Proceedings of the Computer Vision-ECCV 2020, 2020: 191-207. |
| [46] | HAN K, XIAO A, WU E, et al. Transformer in transformer[J]. Advances in Neural Information Processing Systems, 2021, 34: 15908-15919. |
| [47] | TOUVRON H, CORD M, DOUZE M, et al. Training data-efficient image transformers & distillation through attention[C]. Proceedings of the International conference on machine learning, 2021: 10347-10357. |
| [48] | WANG W, XIE E, LI X, et al. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions[C]. Proceedings of the IEEE/CVF international conference on computer vision, 2021: 568-578. |
| [49] | YUAN L, CHEN Y, WANG T, et al. Tokens-to-token vit: Training vision transformers from scratch on imagenet[C]. Proceedings of the IEEE/CVF international conference on computer vision, 2021: 558-567. |
| [50] | LIU Z, LIN Y, CAO Y, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]. Proceedings of the IEEE/CVF international conference on computer vision, 2021: 10012-10022. |
| [51] | LIU Z, NING J, CAO Y, et al. Video swin transformer[C]. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022: 3202-3211. |
| [52] | BERTASIUS G, WANG H, TORRESANI L. Is space-time attention all you need for video understanding?[C]. Proceedings of the ICML, 2021: 4. |
| [53] | YANG C, ZHANG S, YUAN X. Ensemble learning priors driven deep unfolding for scalable video snapshot compressive imaging[C]. Proceedings of the Computer Vision-ECCV 2022, 2022: 600-618. |
| [54] | LIAO X, LI H, CARIN L. Generalized alternating projection for weighted-2,1 minimization with applications to model-based compressive sensing[J]. SIAM Journal on Imaging Sciences, 2014, 7(2): 797-823. |
| [55] | PASZKE A, GROSS S, MASSA F, et al. Pytorch: An imperative style, high-performance deep learning library[J]. Advances in Neural Information Processing Systems, 2019, 32. |
| [56] |
WANG Z, BOVIK A C, SHEIKH H R, et al. Image quality assessment: from error visibility to structural similarity[J]. IEEE Transactions on Image Processing, 2004, 13(4): 600-612.
doi: 10.1109/tip.2003.819861 pmid: 15376593 |
| [1] | YAN Zhiyu, RU Yiwei, SUN Fupeng, SUN Zhenan. Research on Video Behavior Recognition Method with Active Perception Mechanism [J]. Frontiers of Data and Computing, 2024, 6(5): 66-79. |
| [2] | SONG Heng, HU Nan, GENG Tianbao, CHENG Weiguo, ZHANG Huan. Research on Intelligent Interpretation Method of Shock Elastic Wave Detection Signal of Grouting Compactness [J]. Frontiers of Data and Computing, 2024, 6(4): 163-172. |
| [3] | GUO Guanchen, LI Jun, CAI Chengfei, JIAO Yiping, XU Jun. Causal Restraint Transformer for Medical Image Segmentation [J]. Frontiers of Data and Computing, 2024, 6(2): 89-100. |
| [4] | CHEN Dong, LI Ming, CHEN Shuwen. Hyperspectral Image Classification Method Combining Transformer and Multi-Layer Feature Aggregation [J]. Frontiers of Data and Computing, 2023, 5(3): 138-151. |
| [5] | LIU Qiwei,LI Jun,GU Beibei,ZHAO Zefang. TSAIE: Text Sentiment Analysis Model Based on Image Enhancement [J]. Frontiers of Data and Computing, 2022, 4(3): 131-140. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||