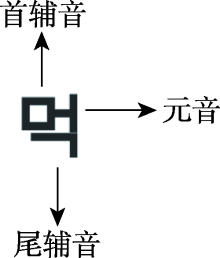
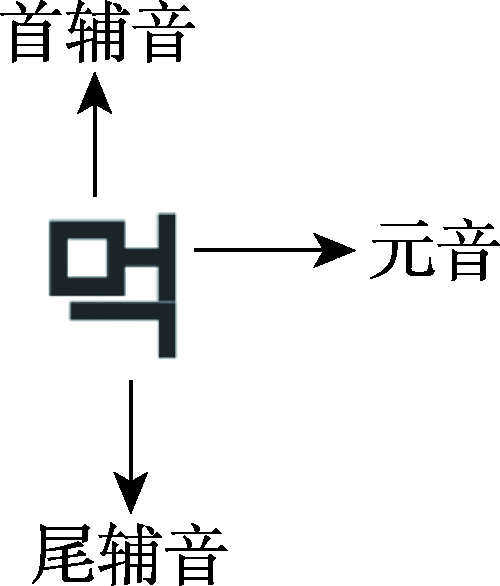
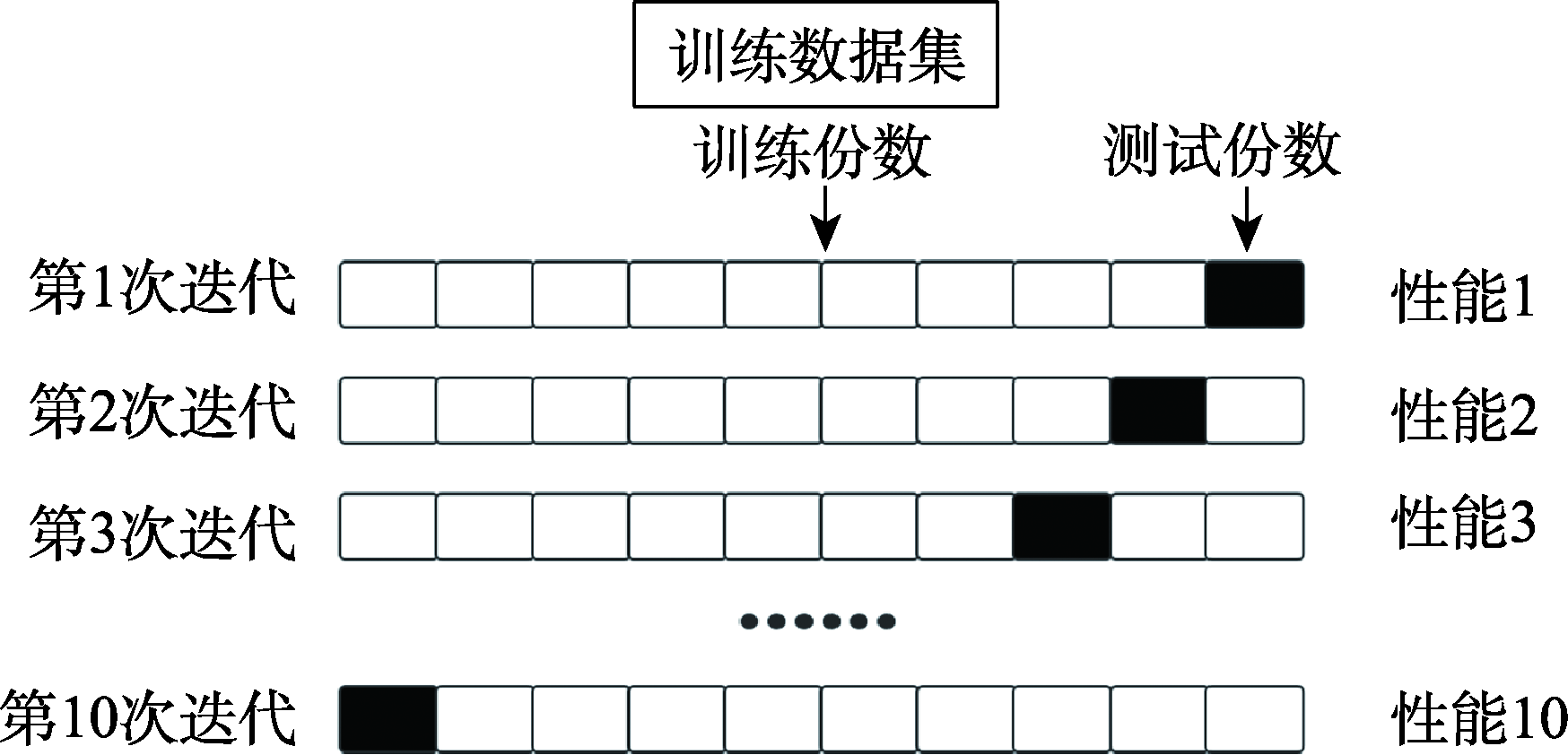
| [1] |
WANG Y C, TZONG R, HAN T. Rule-based Korean Grapheme to Phoneme Conversion Using Sound Patterns[C]// Proceedings of the 23rd Pacific Asia Conference on Language, Information and Computation, 2009:843-850.
|
| [2] |
PARK K, LEE S. g2pM: A Neural Grapheme-to-Phoneme Conversion Package for Mandarin Chinese Based on a New Open Benchmark Dataset[C]// Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, 2020:1723-1727.
|
| [3] |
GALESCU L, ALLEN J F. Bi-directional Conversion Between Graphemes and Phonemes Using a Joint N-gram Model[C]// In SWW4, 2001:131-135.
|
| [4] |
JIAMPOJAMARN S, KONDRAK G, SHERIF T. Applying Many-to-Many Alignments and Hidden Markov Models to Letter-to-Phoneme Conversion[C]// The Conference of the North American Chapter of the Association for Computational Linguistics, Proceedings of the Main Conference, 2007:372- 379.
|
| [5] |
HANNEMANN M, TRMAL J, ONDEL L, et al. Bayesian joint-sequence models for grapheme-to-phoneme conversion[C]// IEEE International Conference on Acoustics, 2017:2836-2840.
|
| [6] |
LIM Y W, CHO J R, LEE J M, et al. The development of Grapheme-to-Phoneme conversion Based on LSTM for Korean language[C]// 한국정보과학회학술발표논문집, 2017: 2004-2006.
|
| [7] |
王永生, 柴佩琪, 宣国荣. 英语语音合成中基于DFGA的字音转换算法[J]. 计算机工程与应用, 2006, 42(13):158-161.
|
| [8] |
冯伟, 易绵竹, 马延周. 基于TensorFlow的俄语词汇标音系统[J]. 计算机应用, 2018, 38(4):971-977.
doi: 10.11772/j.issn.1001-9081.2017092149
|
| [9] |
冯伟, 易绵竹, 马延周. 基于WFST的俄语字音转换算法研究[J]. 中文信息学报, 2018, 32(2):87-93.
|
| [10] |
李鹏, 徐波. 单词自动注音方法的研究[J]. 清华大学学报(自然科学版), 2008(S1): 735-740.
|
| [11] |
赵坤, 梁维谦, 刘润生. 面向字音转换的有条件维数扩展算法[J]. 清华大学学报(自然科学版), 2008, 48(10): 1629-1631.
|
| [12] |
王永生, 李立贵. 基于决策树的德语字素音素转换算法[J]. 计算机应用与软件, 2019, 36(1):211-215.
|
| [13] |
徐及. 朝鲜语语音识别研究[D]. 北京: 中国科学院大学, 2014.
|
| [14] |
周志华. 机器学习[M]. 北京: 清华大学出版社, 2016:129-131.
|
| [15] |
李航. 统计学习方法[M]. 北京: 清华大学出版社, 2012:173-175.
|
| [16] |
Zeroth Kaldi-based Korean ASR (한국어 음성인식) open-source project[DB/OL]. [2022-4-30]. https://opensourcelibs.com/lib/zeroth.
|
 ),WU Licheng2,ZHAO Yue2,*(
),WU Licheng2,ZHAO Yue2,*(