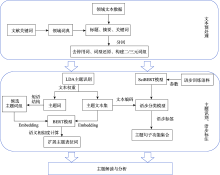
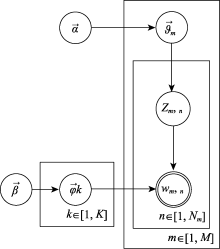
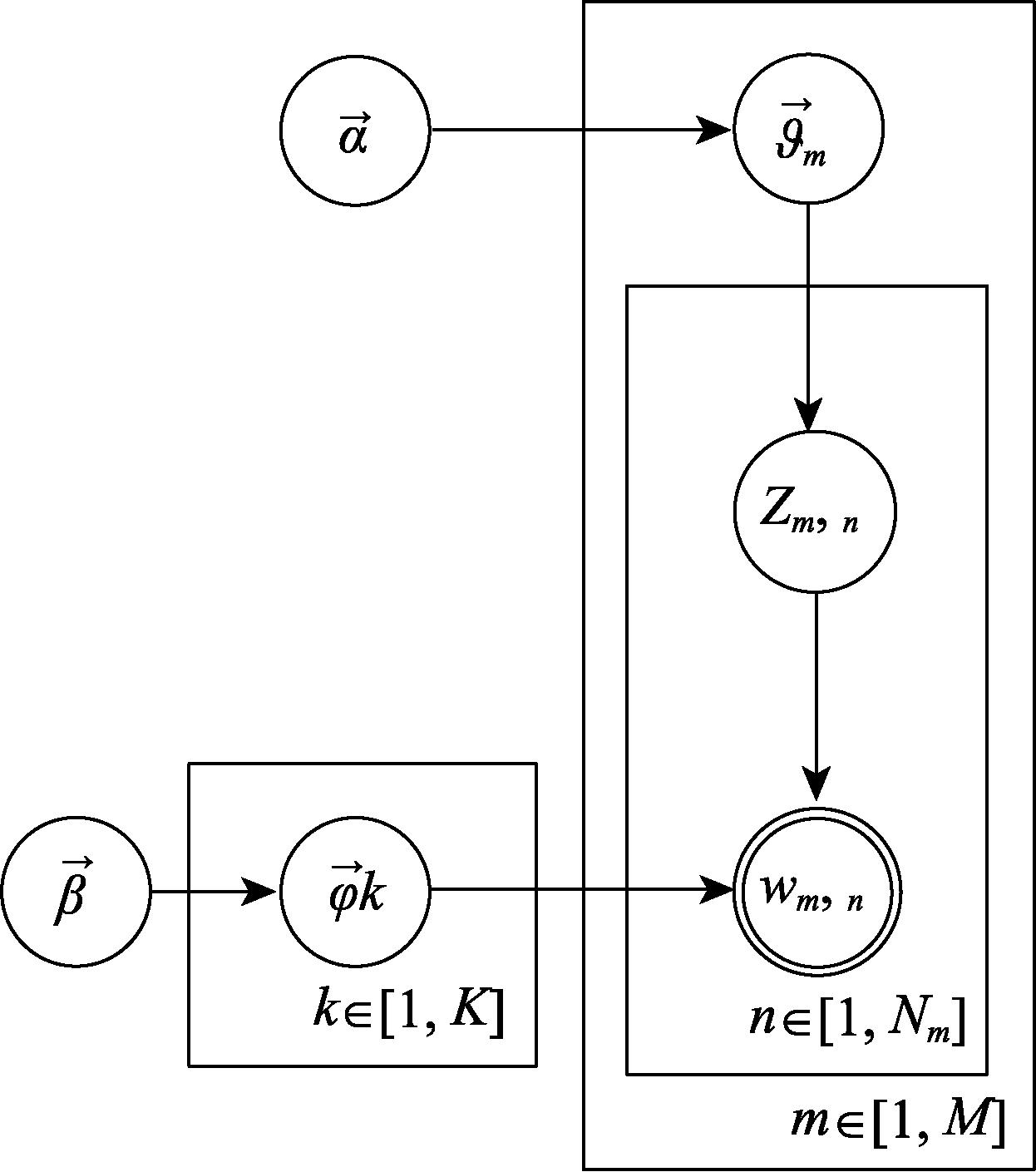
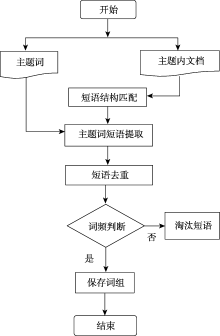
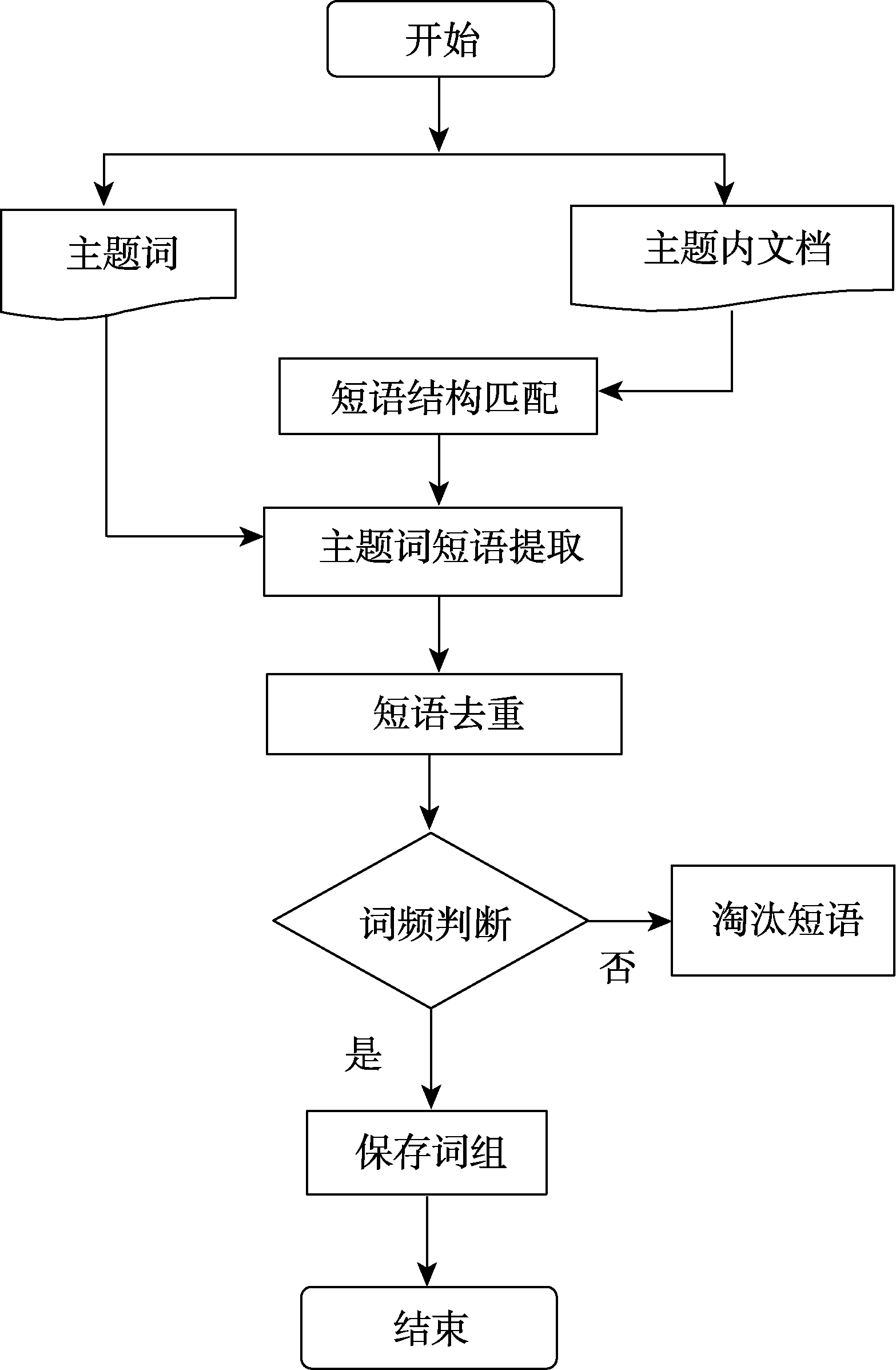
| [1] |
李璐萍, 赵小兵. 基于文本聚类的主题发现方法研究综述[J]. 情报探索, 2020(11): 121-127.
|
| [2] |
CALLON M, COURTIAL J P, TURNER W A, et al. From Translations to Problematic Networks: An Introduction to Co-word Analysis[J]. Social Science Information, 1983, 22(2): 191-235.
doi: 10.1177/053901883022002003
|
| [3] |
郭崇慧, 曹梦月. GMAP: 一种基于AP聚类的共词分析方法[J]. 情报学报, 2017, 36(11): 1192-1200.
|
| [4] |
李锋. 基于核心关键词的聚类分析——兼论共词聚类分析的不足[J]. 情报科学, 2017, 35(8): 68-71,78.
|
| [5] |
闫涛. 基于共现分析的文本表示方法研究[D]. 太原: 山西大学, 2021.
|
| [6] |
田鹏伟, 张娴. 基于异构信息网络融合的专利技术主题识别研究[J]. 情报杂志, 2021, 40(8): 45-52.
|
| [7] |
丁敬达, 陈一帆, 刘超, 等. 基于共词和Word2Vec加权向量的文献-主题语义匹配分析方法[J]. 图书情报工作, 2022, 66(12): 108-116.
doi: 10.13266/j.issn.0252-3116.2022.12.010
|
| [8] |
张琴, 张智雄. 基于PhraseLDA模型的主题短语挖掘方法研究[J]. 图书情报工作, 2017, 61(8):120-125.
doi: 10.13266/j.issn.0252-3116.2017.08.015
|
| [9] |
TAJBAKHSH M S, BAGHERZADEH J. Semantic Knowledge LDA with Topic Vector for Recommending Hashtags: Twitter Use Case[J]. Intelligent Data Analysis, 2019, 23(3): 609-622.
doi: 10.3233/IDA-183998
|
| [10] |
赵林静. 结合语义相似度改进LDA的文本主题分析[J]. 计算机工程与设计, 2019, 40(12): 3514-3519.
|
| [11] |
王红斌, 王健雄, 张亚飞, 等. 主题不平衡新闻文本数据集的主题识别方法研究[J]. 数据分析与知识发现, 2021, 5(3): 109-120.
|
| [12] |
张晨晨. 基于LDA模型的舆情情感主题研究[D]. 阜阳: 阜阳师范大学, 2022.
|
| [13] |
SWALES J M. Research Genres: Explorations and Applications[M]. Cambridge: Cambridge University Press, 2004: 228-229.
|
| [14] |
陈果, 许天祥. 基于主动学习的科技论文句子功能识别研究[J]. 数据分析与知识发现, 2019, 3(8): 53-61.
|
| [15] |
王末, 崔运鹏, 陈丽, 等. 基于深度学习的学术论文语步结构分类方法研究[J]. 数据分析与知识发现, 2020, 4 (6) :66-68.
|
| [16] |
欧石燕, 陈嘉文. 科学论文全文语步自动识别研究[J]. 现代情报, 2021, 41(11):3-11.
doi: 10.3969/j.issn.1008-0821.2021.11.001
|
| [17] |
赵旸, 张智雄, 刘欢, 等. 基金项目摘要的语步识别系统设计与实现[J]. 情报理论与实践, 2022, 45(8): 162-168.
|
| [18] |
郭航程, 何彦青, 兰天, 等. 基于Paragraph-BERT-CRF的科技论文摘要语步功能信息识别方法研究[J]. 数据分析与知识发现, 2022, 6(Z1): 298-307.
|
| [19] |
NILS R, IRYNA G. Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks[J]. CoRR, 2019. arXiv: 1908. 10084: 1908.10084.
|
| [20] |
BRUENING B. Idioms, Collocations, and Structure[J]. Natural Language & Linguistic Theory, 2020, 38:365-424.
|
| [21] |
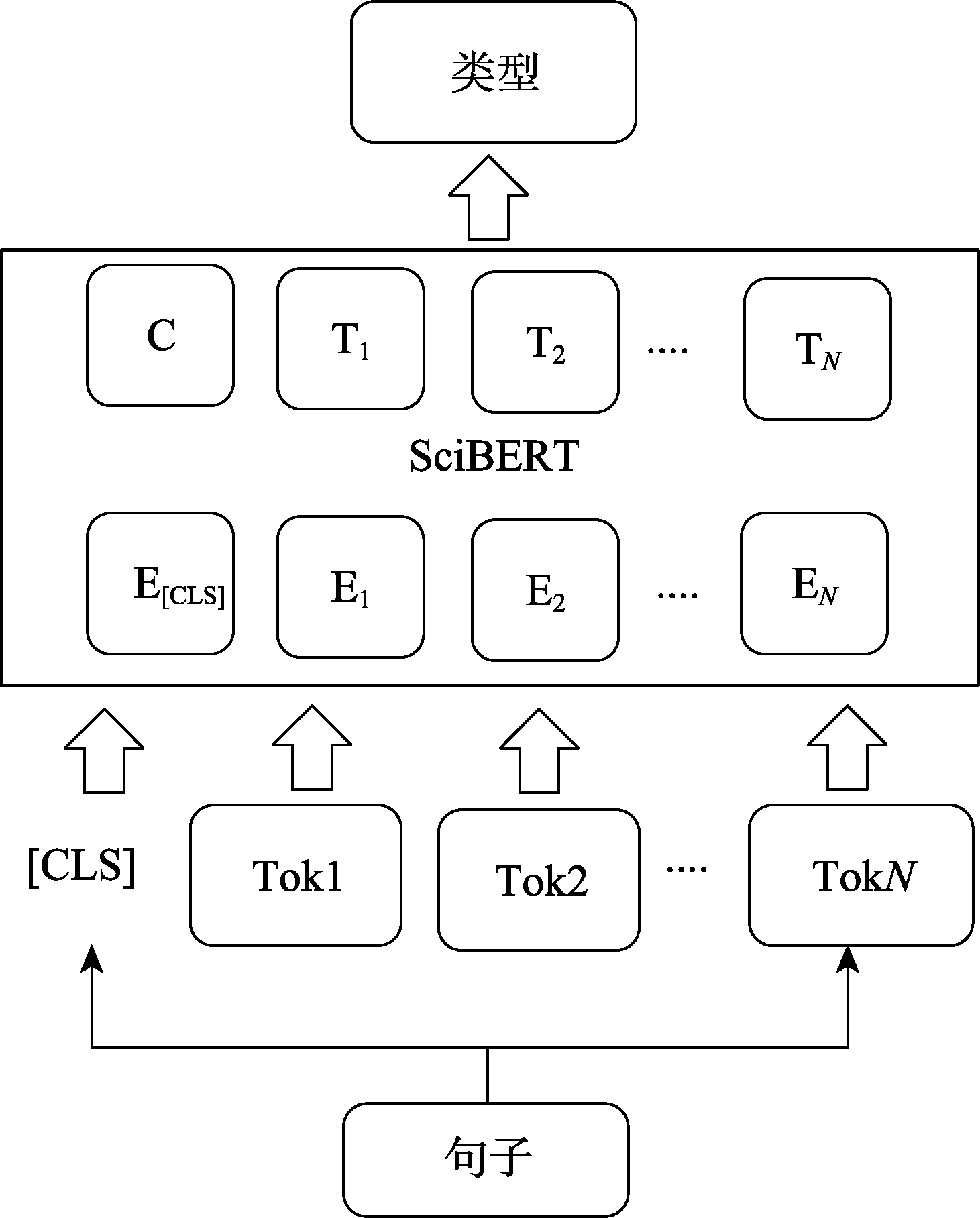
BELTAGY I, LO K, COHAN A. SciBERT: A Pretrained Language Model for Scientific Text[J]. 2019. arXiv: 1903.10676.
|
 ),CHUAN Limin*(
),CHUAN Limin*(