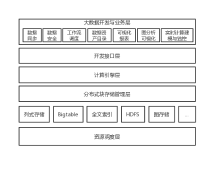
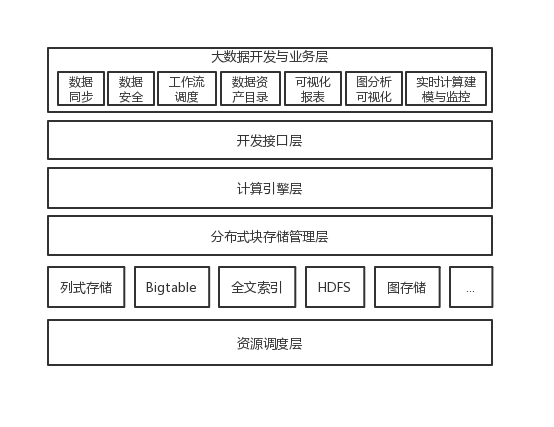
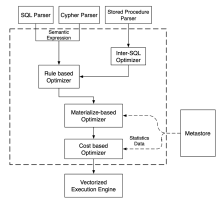
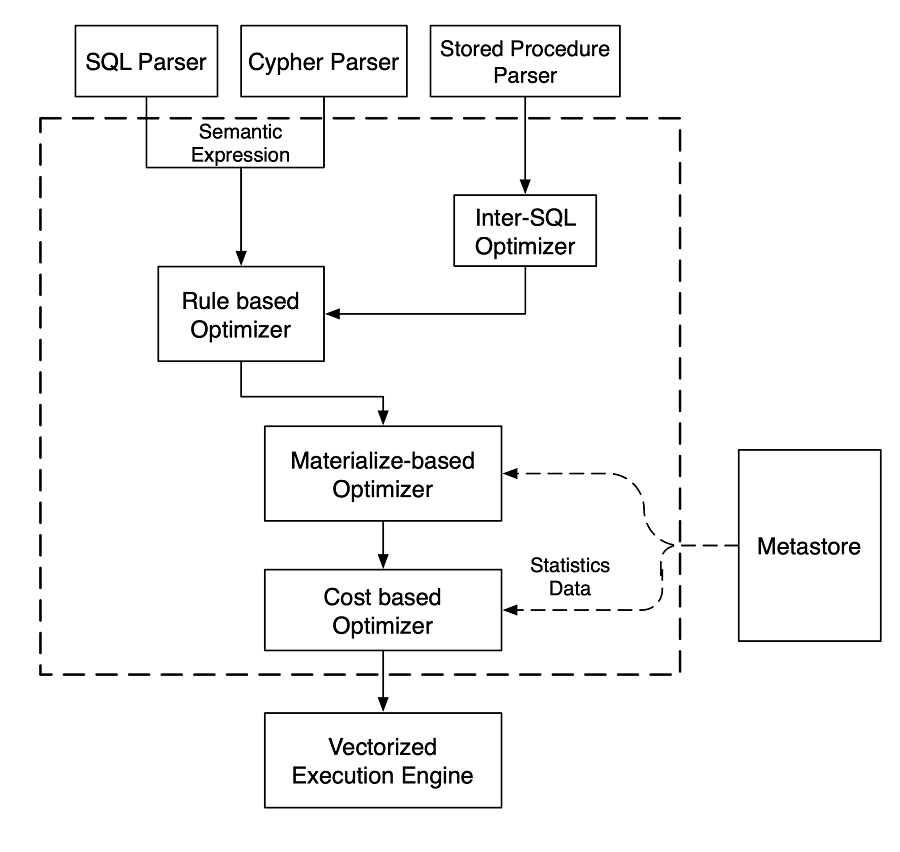
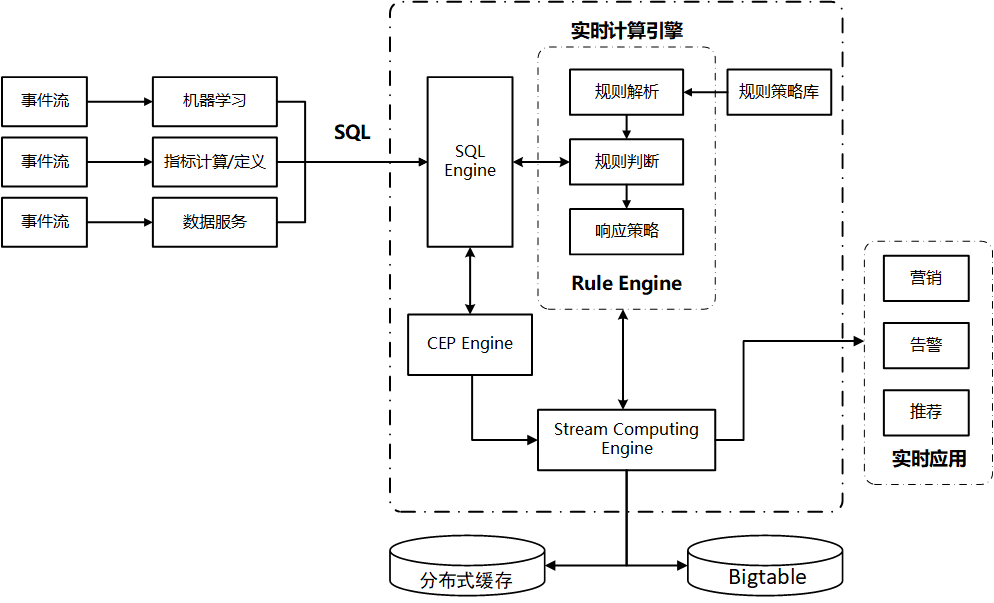
| [1] |
http://hadoop.apache.org/.
|
| [2] |
Matei Zaharia . Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing, NSDI 2012.
|
| [3] |
https://www.docker.com/.
|
| [4] |
Brendan Burns, Brian Grant , etc. Borg, Omega, and Kubernetes. Magazine Queue - Containers, Volume 14 Issue 1, January-February 2016.
|
| [5] |
A Thusoo, JS Sarma ,etc. Hive: a warehousing solution over a map-reduce framework,Proceedings of the VLDB Endowment , Volume 2 Issue 2, August 2009 .
|
| [6] |
P Carbone, A Katsifodimos, S Ewen ,etc. Apache flink: Stream and batch processing in a single engine, Bulletin of the IEEE Computer Society Technical Committee on Data Engineering, 36(4).
|
| [7] |
M Kornacker, A Behm, V Bittorf , Impala: A Modern, Open-Source SQL Engine for Hadoop.In Proc.CIDR’15.
|
| [8] |
M Armbrust, RS Xin , etc. Spark SQL: Relational Data Processing in Spark, Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data.
|
| [9] |
http://www.transwarp.cn/transwarp/assembly-inceptor.html.
|
| [10] |
http://www.transwarp.cn/transwarp/assembly-slipstream.html.
|
| [11] |
V Vavilapalli ,etc. Apache Hadoop YARN: yet another resourcenegotiator. Proceedings of the 4th annual Symposium on Cloud Computing.
|
| [12] |
https://en.wikipedia.org/wiki/Directed_acyclic_graph.
|
| [13] |
A Buchmann, B Koldehofe , etc. Complex event processing, Methods and Applications of Informatics and Information Technology, 2009.
|
| [14] |
https://en.wikipedia.org/wiki/Business_rules_engine.
|
| [15] |
L Lamport , Paxos made simple - ACM Sigact News , 2001.
|
| [16] |
D Ongaro, J Ousterhout , In search of an understandable consensus algorithm,Proceedings of USENIX ATC ’14: 2014 USENIX Annual Technical Conference.
|