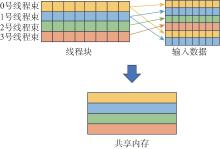
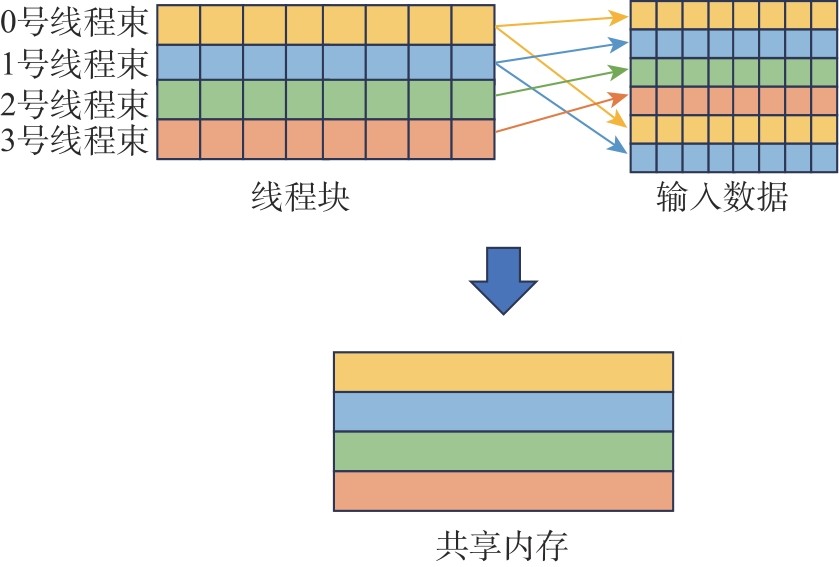
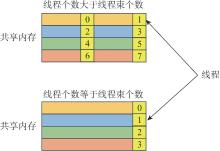
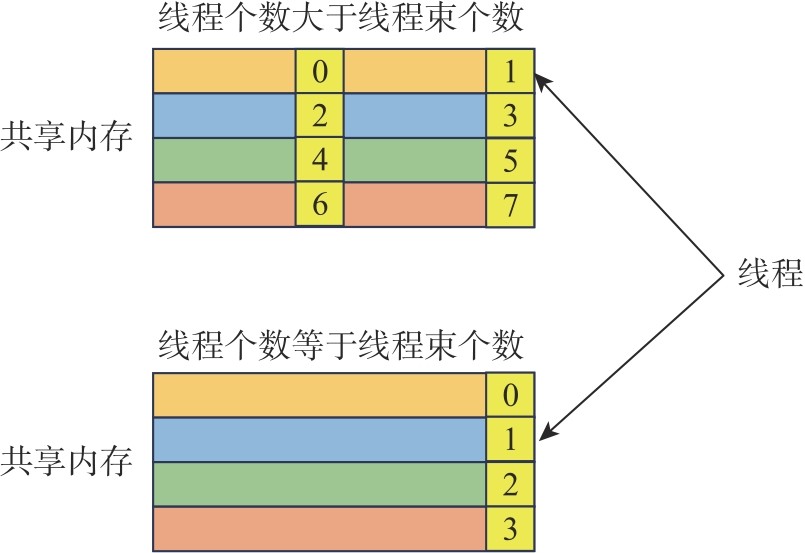
| [1] |
BROWN T, MANN B, RYDER N, et al. Language models are few-shot learners[J]. Advances in neural information processing systems, 2020, 33: 1877-1901.
|
| [2] |
ACHIAM J, ADLER S, AGARWAL S, et al. Gpt-4 technical report[J]. arXiv preprint arXiv:2303.08774, 2023.
|
| [3] |
TOUVRON H, LAVRIL T, IZACARD G, et al. LLaMA: Open and efficient foundation language models[J]. arXiv preprint arXiv: 2302.13971, 2023.
|
| [4] |
NARAYANAN D, SHOEYBI M, CASPER J, et al. Efficient large-scale language model training on gpu clusters using megatron-lm[C]// Proceedings of the international conference for high performance computing, networking, storage and analysis, 2021: 1-15.
|
| [5] |
MICIKEVICIUS P, NARANG S, ALBEN J, et al. Mixed precision training[J]. arXiv preprint arXiv:1710.03740, 2017.
|
| [6] |
尹宝才, 王文通, 王立春. 深度学习研究综述[J]. 北京工业大学学报, 2015, 41(1): 48-59.
|
| [7] |
ABADI M, BARHAM P, CHEN J, et al. TensorFlow: a system for Large-Scale machine learning[C]// 12th USENIX symposium on operating systems design and implementation (OSDI 16), 2016: 265-283.
|
| [8] |
PASZKE A. Pytorch: An imperative style, high-performance deep learning library[J]. arXiv preprint arXiv:1912.01703, 2019.
|
| [9] |
Huawei Technologies Co., Ltd. Huawei mindspore ai development framework[M]// Artificial Intelligence T-echnology. Singapore: Springer Nature Singapore, 2022: 137-162.
|
| [10] |
MA Y, YU D, WU T, et al. PaddlePaddle: An open-source deep learning platform from industrial practice[J]. Frontiers of Data and Computing, 2019, 1(1): 105-115.
|
| [11] |
郝萌, 田雪洋, 鲁刚钊, 等. 基于国产DCU异构平台的图匹配算法移植与优化[J]. 计算机科学, 2024, 51 (4): 67-77.
|
| [12] |
GHORPADE J, PARANDE J, KULKARNI M, et al. GPGPU processing in CUDA architecture[J]. arXiv preprint arXiv:1202.4347, 2012.
|
| [13] |
KIRK D. NVIDIA CUDA software and GPU parallel computing architecture[C]// ISMM. 2007, 7: 103-104.
|
| [14] |
What is ROCm?[EB/OL]. AMD ROCm Documentation, [2025-03-09]. https://rocm.docs.amd.com/en/latest/what-is-rocm.html.
|
| [15] |
What is HIP?[EB/OL]. AMD HIP Documentation, [20250309]. https://rocm.docs.amd.com/projects/H-IP/en/latest/what_is_hip.html.
|
 ),LIU Fang2,*(
),LIU Fang2,*(