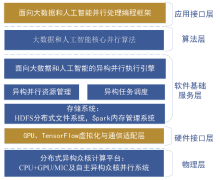
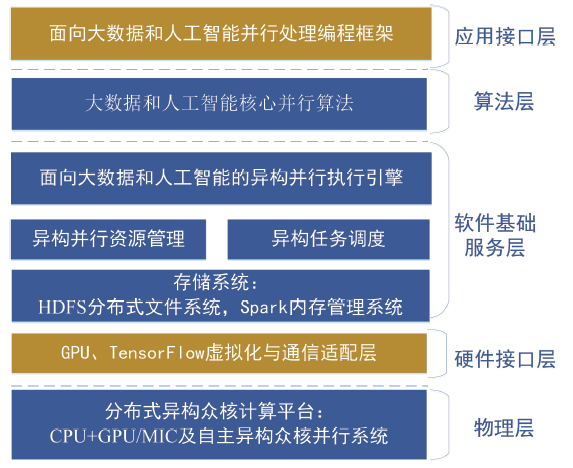
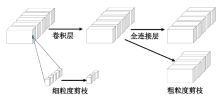
| [1] |
John Walker S . Big data:A revolution that will transform how we live, work, and think[M]. 2014.
|
| [2] |
McAfee A, Brynjolfsson E, Davenport T H , et al. Big data: the management revolution[J]. Harvard business review, 2012,90(10):60-68.
|
| [3] |
Zhang Q, Yang L T, Chen Z , et al. A survey on deep learning for big data[J]. Information Fusion, 2018,42:146-157.
|
| [4] |
程学旗, 靳小龙, 王元卓, 郭嘉丰, 张铁赢, 李国杰 . 大数据系统和分析技术综述[J]. 软件学报, 2014,25(9):1889-1908.
|
| [5] |
O'Leary D E . Artificial intelligence and big data[J]. IEEE Intelligent Systems, 2013,28(2):96-99.
|
| [6] |
LeCun Y, Bengio Y, Hinton G . Deep learning[J]. nature, 2015,521(7553):436.
|
| [7] |
Deng J, Dong W, Socher R, et al. Imagenet: A large-scale hierarchical image database [C]//2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009: 248-255.
|
| [8] |
Srivastava N, Salakhutdinov R R. Multimodal learning with deep boltzmann machines [C]//Advances in neural information processing systems. 2012: 2222-2230.
|
| [9] |
top500. . 2008.
|
| [10] |
Zhang Y, Sun J, Yuan G , et al. Perspectives of China’s HPC system development: a view from the 2009 China HPC TOP100 list[J]. Frontiers of Computer Science in China, 2010,4(4):437-444.
|
| [11] |
Zhang Y, Sun J, Yuan G , et al. A Brief Introduction to China HPC TOP100: from2002 to 2006[C]. In: Proc of Proceedings of the 2007 Asian technology informationprogram’s (ATIP’s) 3rd workshop on High performance computing in China: solutionapproaches to impediments for high performance computing. ACM, 2007, 32-36.
|
| [12] |
J.C. Chaves . Enabling High Productivity Computing through Virtualization[J]. Information Sciences, 2018,435:124-149.
|
| [13] |
李斌, 周清雷 , 等. 基于拟态计算的大数据高效能平台设计方法[J]. 计算机应用研究, 2019 ( 07):19-25.
|
| [14] |
祁琛 . 应用于神经网络的高效能计算单元的研究与实现[D]. 南京:东南大学, 2018.
|
| [15] |
D.H. Jones, A. Powell, C.-S. Bouganis, P.Y.K. Cheung. GPU Versus FPGA for High Productivity Computing [C]. IEEE International Conference on Field Programmable Logic and Applications (FPL). 2010 ( 06):112-119.
|
| [16] |
张小庆 . 高效能云计算虚拟机优化部署策略[J]. 计算机工程与应用, 2016 ( 04):28-36.
|
| [17] |
王永桂 . 流域大尺度水环境模型的高效能集群计算方法研究及其在三峡库区的应用[D]. 武汉: 武汉大学, 2015.
|
| [18] |
党林玉 . 可重构高效能计算系统中软硬件协同技术研究[D]. 解放军信息工程大学, 2014.
|
| [19] |
B. Betkaoui, D.B. Thomas, W. Luk. Comparing performance and energy efficiency of FPGAs and GPUs for high productivity computing [C]. IEEE International Conference on Field-Programmable Technology (FPT), 2010 ( 09):74-80.
|
| [20] |
阮利, 秦广军, 肖利民 , 等. 基于龙芯多核处理器的云计算节点机[J]. 通信学报, 2013(12):39-46.
|
| [21] |
刘勇鹏 . 大规模高效能计算的系统软件关键技术研究[D]. 国防科学技术大学, 2012.
|
| [22] |
J. Unpingco . User Friendly High Productivity Computational Workflows Using the VISION /HPC Prototype[C]. IEEE International Conference on High-performance Computing, 2018(03):93-105.
|
| [23] |
吴丹 . 高效能计算型存储器体系结构关键技术研究与实现[D]. 华中科技大学, 2012.
|
| [24] |
李波, 解建仓 , 等. 网格环境下的水利高性能计算平行系统及应用[J]. 华中科技大学学报, 2011 ( 06):73-82.
|
| [25] |
王之元 . 并行计算可扩展性分析与优化——能耗、可靠性与计算性能[D]. 国防科学技术大学, 2011.
|
| [26] |
Chu C, Kim S K, Lin Y, et al. Map-reduce for machine learning on multicore [C]//Proceedings of the 20 th Annual Conference on Neural Information Processing Systems, Amsterdam , 2007: 281-288.
|
| [27] |
Gao M, Pu J, Yang X, et al. TETRIS: Scalable and Efficient Neural Network Acceleration with 3D Memory [C] //Proceedings of the Twenty-Second International Conference on Architectural Support for Programming Languages and Operating Systems. ACM, 2017: 751-764.
|
| [28] |
Jin L, Wang Z, Gu R, et al. Training large scale deep neural networks on the intel xeon phi many- core coprocessor [C] //Proceedings of the International Parallel and Distributed Processing Symposium,Piscataway, 2014: 1622-1630.
|
| [29] |
Mei K, Dong P, Lei H , et al. A distributed approach for large-scale classifier training and image classification[J]. Neurocomputing, 2014,144:304-317.
|
| [30] |
杨柳, 景丽萍, 于剑 . 一种异构直推式迁移学习算法[J]. 软件学报, 2015,26(11):2762-2780.
|
| [31] |
王岳青, 窦勇, 吕启, 李宝峰, 李腾 . DLPF:基于异构体系结构的并行深度学习编程框架[J]. 计算机研究与发展, 2016,53(06):1202-1210.
|
| [32] |
洪文杰, 李肯立, 全哲, 阳王东, 李克勤, 郝子宇, 谢向辉 . 面向神威·太湖之光的PETSc 可扩展异构并行算法及其性能优化[J]. 计算机学报, 2017,40(9):1961-1973.
|
| [33] |
Chen C, Li K, Ouyang A , et al. GPU-Accelerated Parallel Hierarchical Extreme Learning Machine on Flink for Big Data[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2017: 1-14.
|
| [34] |
Xing E P, Ho Q, Dai W , et al. Petuum: A new platform for distributed machine learning on big data[J]. IEEE Transactions on Big Data, 2015,1(2):49-67.
|
| [35] |
Z. Liu, M. Sun, T. Zhou, G. Huang, T. Darrell . Rethinking the Value of Network Pruning. 2018.
|
| [36] |
S. Han, H. Mao, W. J. Dally . A Deep Neural Network Compression Pipeline: Pruning, Quantization, Huffman Encoding. 2015.
|
| [37] |
Y. L. Cun, J. S. Denker, S. A. Solla . Optimal brain damage[J]. Advances in Neural Information Processing Systems, Vol. 2, No. 1, 1990, p. 1990.
|
| [38] |
B. Hassibi, D. G. Stork . Second Order Derivatives for Network Pruning: Optimal Brain Surgeon[J]. Advances in Neural Information Processing Systems, vol. 5, pp. 164-- 171, 1993.
|
| [39] |
S. Han, J. Pool, J. Tran, W. J. Dally . Learning both Weights and Connections for Efficient Neural Networks. 2015.
|
| [40] |
L. Hao, A. Kadav, I. Durdanovic, H. Samet, H. P. Graf . Pruning Filters for Efficient ConvNets. 2016.
|
| [41] |
P. Molchanov, S. Tyree, T. Karras, T. Aila, J. Kautz . Pruning Convolutional Neural Networks for Resource Efficient Transfer Learning. 2016.
|
| [42] |
J. H. Luo, J. Wu, W. Lin . ThiNet: A Filter Level Pruning Method for Deep Neural Network Compression. 2017.
|
| [43] |
R. Yu, A. Li, C. F. Chen, J. H. Lai, V. I. Morariu, X. Han, M. Gao, C. Y. Lin, L. S. Davis . NISP: Pruning Networks using Neuron Importance Score Propagation. 2017.
|
| [44] |
Y. He, X. Zhang, S. Jian . Channel Pruning for Accelerating Very Deep Neural Networks. 2017.
|
| [45] |
H. Song, X. Liu, H. Mao, P. Jing, A. Pedram, M. A. Horowitz, W. J. Dally . EIE: Efficient Inference Engine on Compressed Deep Neural Network. Acm Sigarch Computer Architecture News, vol. 44, no. 3, pp. 243-254, 2016.
|
| [46] |
X. Gao, Y. Zhao, L. Dudziak, R. Mullins, C. Z. Xu . Dynamic Channel Pruning: Feature Boosting and Suppression. 2018.
|
| [47] |
E. P. Yong-Deok Kim, Sungjoo Yoo, Taelim Choi, Lu Yang, and Dongjun Shin .COMPRESSION OF DEEP CONVOLUTIONAL NEURAL NETWORKS FOR FAST AND LOW POWER MOBILE APPLICATIONS. in ICLR, 2016.
|
| [48] |
E. Denton, W. Zaremba, J. Bruna, Y. Lecun, R. Fergus . Exploiting Linear Structure Within Convolutional Networks for Efficient Evaluation. 2014.
|
| [49] |
T. Cheng, X. Tong, Z. Yi, X. Wang, E. Weinan . Convolutional neural networks with low-rank regularization. Computer Science, 2016.
|
| [50] |
H. Y., Y. Z., J. Liu . End-to-End Learning of Energy-Constrained Deep Neural Networks. in IDLR, 2019.
|
| [51] |
T. J. Yang, Y. H. Chen, V. Sze . Designing Energy-Efficient Convolutional Neural Networks Using Energy-Aware Pruning. 2017.
|
| [52] |
K. Simonyan, A. Zisserman . Very Deep Convolutional Networks for Large-Scale Image Recognition[J]. Computer Science, 2014.
|
| [53] |
M. Denil, B. Shakibi, L. Dinh, M. A. Ranzato, N. D. Freitas . Predicting Parameters in Deep Learning.
|
| [54] |
M. Mathieu, M. Henaff, Y. Lecun . Fast Training of Convolutional Networks through FFTs. Eprint Arxiv, 2013.
|
| [55] |
Y. Gong, L. Liu, Y. Ming, L. Bourdev . Compressing Deep Convolutional Networks using Vector Quantization[J]. Computer Science, 2014.
|
| [56] |
W. Chen, J. T. Wilson, S. Tyree, K. Q. Weinberger, Y. Chen . Compressing Neural Networks with the Hashing Trick[J].Computer Science, pp. 2285-2294, 2015.
|
| [57] |
Y. Cheng, F. X. Yu, R. S. Feris, S. Kumar, A. Choudhary, S. F. Chang . Fast Neural Networks with Circulant Projections. 2015.
|
| [58] |
A. Novikov, D. Podoprikhin, A. Osokin, D. Vetrov . Tensorizing Neural Networks. 2015.
|
| [59] |
X. Zhang, J. Zou, M. Xiang, K. He, S. Jian . Efficient and Accurate Approximations of Nonlinear Convolutional Networks. 2014.
|
 ),Yang Wangdong1,*(
),Yang Wangdong1,*(