Frontiers of Data and Computing ›› 2025, Vol. 7 ›› Issue (2): 109-119.
CSTR: 32002.14.jfdc.CN10-1649/TP.2025.02.011
doi: 10.11871/jfdc.issn.2096-742X.2025.02.011
• Technology and Application • Previous Articles Next Articles
WANG Qijun1( ),LIU Tinglong2,*()
),LIU Tinglong2,*()
Received:2024-09-17
Online:2025-04-20
Published:2025-04-23
Contact:
LIU Tinglong
E-mail:qjwang@cmhk.com;liutl@dlpu.edu.cn
WANG Qijun,LIU Tinglong. Video Action Recognition Model Based on Attention and Relative Average Discriminator[J]. Frontiers of Data and Computing, 2025, 7(2): 109-119, https://cstr.cn/32002.14.jfdc.CN10-1649/TP.2025.02.011.
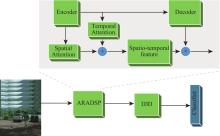
Fig.1
ARADSP video action network architecture"
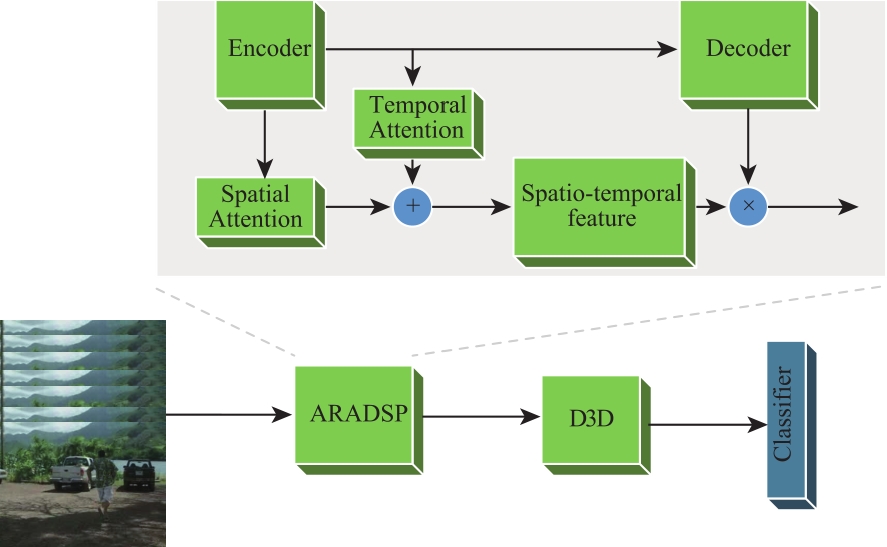
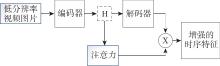
Fig.2
Attention mechanisms generate adversarial network processing flows"
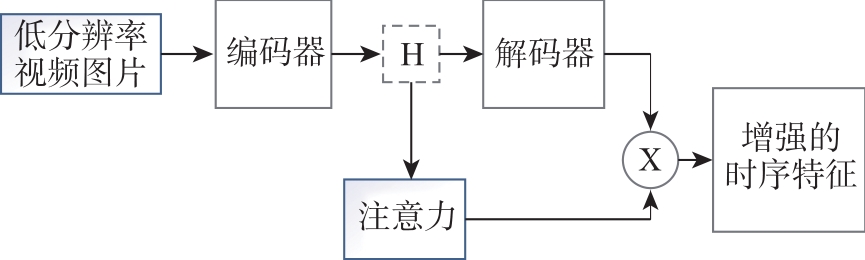
Table 1
The performance of this method is compared on HMDB51 and UCF101 datasets"
| 相对平均的区分器模块 | 注意力机制的超级分辨率模块 | 精度 | |
|---|---|---|---|
| HMDB51 | UCF101 | ||
| × | × | 78.7% | 97% |
| √ | × | 79.8% | 97.9% |
| × | √ | 79.1% | 97.3% |
| √ | √ | 80.1% | 98.2% |
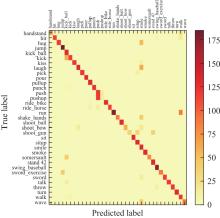
Fig.3
Confusion matrix without attention mechanism and without using relative average discriminator"
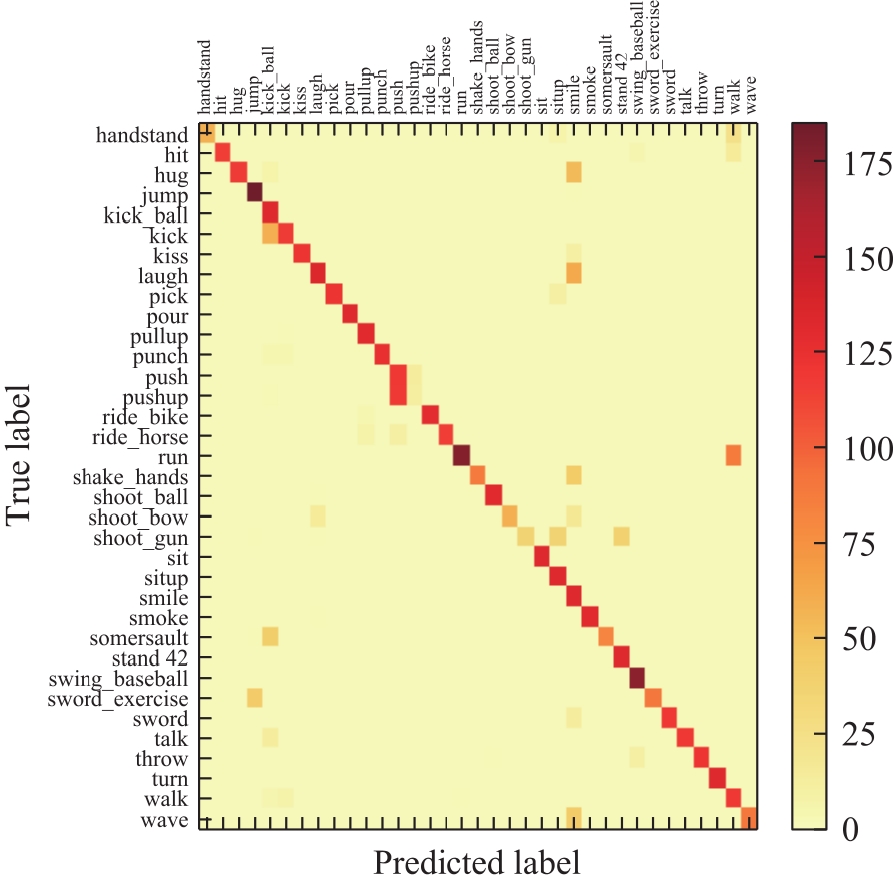
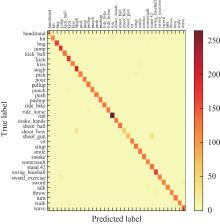
Fig.4
Super-resolution of the attention mechanism generates adversarial networks and confusion matrices using relative average discriminators"

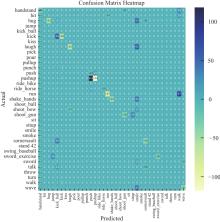
Fig.5
Calculate the difference between the two confusion matrices and generate a heat map"
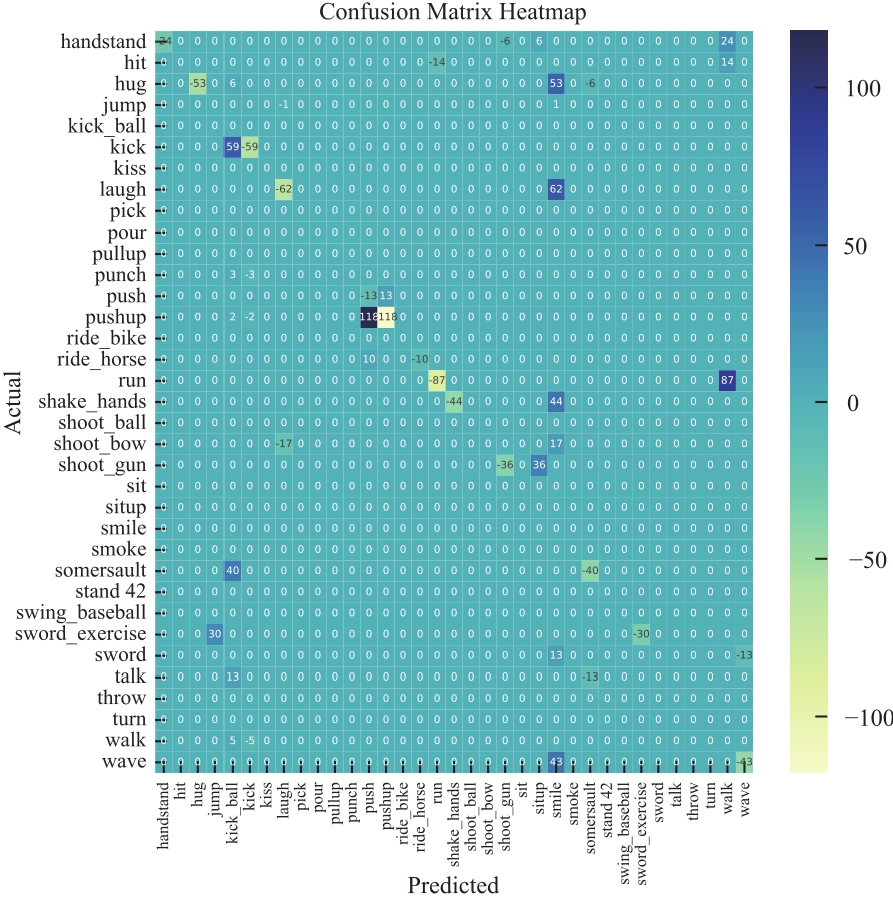
Table 2
The performance of our method is compared with other existing excellent methods on HMDB51 dataset"
| 方法 | 骨架网络 | 预训练 | Top-1 |
|---|---|---|---|
| S3D[ | Inception V2 | Kinetics | 75.9% |
| R(2+1)D[ | ResNet18 | Kinetics | 74.5% |
| TSM[ | Inception V2 | Kinetics | 73.2% |
| STM[ TEA[ TDN[ TCM[ D3D[ UniFormer-B[ ours | ResNet34 ResNet50 ResNet50 ResNet50 ResNet50 ResNet50 ResNet50 | Kinetics Kinetics Kinetics Kinetics Kinetics Kinetics Kinetics | 72.2% 73.3% 76.3% 77.5% 78.7% 79.6% 80.1% |
Table 3
The performance of our method is compared with other existing excellent methods on the UCF101 dataset"
| 方法 | 骨架网络 | 预训练 | Top-1 |
|---|---|---|---|
| S3D[ | Inception V2 | Kinetics | 96.8% |
| R(2+1)D[ | ResNet18 | Kinetics | 96.8% |
| TSM[ | Inception V2 | Kinetics | 96.0% |
| STM[ TEA[ TDN[ TCM[ D3D[ UniFormer-B[ Two-Stream I3D[ Ours | ResNet34 ResNet50 ResNet50 ResNet50 ResNet50 ResNet50 ResNet50 ResNet50 | Kinetics Kinetics Kinetics Kinetics Kinetics Kinetics Kinetics Kinetics | 96.2% 96.9% 97.4% 97.1% 97.0% 97.1% 97.8% 98.2% |
Table 4
The performance of our method is compared with other existing excellent methods on the Something-SomethingV1&V2 dataset"
| 方法 | 骨架网络 | Param. | GFLOPs | Top1(Sth-Sth V1) |
|---|---|---|---|---|
| S3D[ | Inception V2 | 20.5M | 78G | 47.3% |
| TSM[ | Inception V2 | 24.3M | 98G | 49.7% |
| STM[ TEA[ TDN[ TCM[ Ours | ResNet34 ResNet50 ResNet50 ResNet50 ResNet50 | 24.0M 43.1M 35.4M 49.0M 33.0M | 67×30G 65G 108G 105G 48G | 50.7% 52.6% 55.1% 57.2% 60.5% |
| 方法 | 骨架网络 | Param. | GFLOPs | Top1(Sth-Sth V2) |
| TSM[ | Inception V2 | 35.3M | 65×6G | 66.6% |
| STM[ TEA[ TDN[ TCM[ UniFormer-B[ Ours | ResNet34 ResNet50 ResNet101 ResNet50 ResNet50 ResNet50 | 24.0M 24.5M 35.4M 49.0M 50.0M 33.0M | 67×30G 65G 198G 105G 777G 48G | 67.2% 67.9% 68.2% 67.8% 71.2% 72.6% |
| [1] | 吴建超, 王利民, 武港山. 视频群体行为识别综述[J]. 软件学报, 2023, 34(2): 964-984. |
| [2] | 丁静, 舒祥波, 黄捧, 等. 基于多模态多粒度图卷积网络的老年人日常行为识别[J]. 软件学报, 2023, 34(5): 2350-64. |
| [3] | 唐超, 王文剑, 李伟, 等. 基于多学习器协同训练模型的人体行为识别方法[J]. 软件学报, 2015, 26(11): 2939-50. |
| [4] | ATAER-CANSIZOGLU E, JONES M, ZHANG Z, et al. Verification of very low-resolution faces using an identity-preserving deep face super-resolution network[J]. arXiv preprint arXiv:190310974, 2019. |
| [5] | BAI Y, ZHANG Y, DING M, et al. Sod-mtgan: Small object detection via multi-task generative adversarial network[C]// Proceedings of the Proceedings of the European Conference on Computer Vision (ECCV), F, 2018. |
| [6] | WANG Z, YE M, YANG F, et al. Cascaded SR-GAN for scale-adaptive low resolution person re-identification[C]// Proceedings of the IJCAI, F, 2018. |
| [7] | HOU M, LIU S, ZHOU J, et al. Extreme low-resolution activity recognition using a super-resolution-oriented generative adversarial network[J]. Micromachines, 2021, 12(6): 670. |
| [8] | JOLICOEUR-MARTINEAU A. The relativistic discriminator: a key element missing from standard GAN[J]. arXiv preprint arXiv:180700734, 2018. |
| [9] | KUEHNE H, JHUANG H, GARROTE E, et al. HMDB: A Large Video Database for Human Motion Recognition[J]. IEEE, 2011: 2556-2563. |
| [10] | SOOMRO K, ZAMIR A R, SHAH M. UCF101: A dataset of 101 human actions classes from videos in the wild[C]// CRCV-TR-12-01, University of Central Florida, 2012. |
| [11] | KARPATHY A, TODERICI G, SHETTY S, et al. Large-scale video classification with convolutional neural networks[C]// Proceedings of the Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, F, 2014. |
| [12] | SIMONYAN K, ZISSERMAN A. Two-stream convolutional networks for action recognition in videos[J]. Advances in neural information processing systems, 2014: 568-576. |
| [13] | WANG L, XIONG Y, WANG Z, et al. Temporal segment networks for action recognition in videos[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 41(11): 2740-55. |
| [14] | TRAN D, BOURDEV L, FERGUS R, et al. Learning spatiotemporal features with 3d convolutional networks[C]// Proceedings of the Proceedings of the IEEE international conference on computer vision, F, 2015. |
| [15] | SUN L, JIA K, YEUNG D-Y, et al. Human action recognition using factorized spatio-temporal convolutional networks[C]// Proceedings of the Proceedings of the IEEE international conference on computer vision, F, 2015. |
| [16] | DIBA A, FAYYAZ M, SHARMA V, et al. Temporal 3d convnets: New architecture and transfer learning for video classification[J]. arXiv preprint arXiv:171108200, 2017. |
| [17] | RYOO M, KIM K, YANG H. Extreme low resolution activity recognition with multi-siamese embedding learning[C]// Proceedings of the Proceedings of the AAAI conference on artificial intelligence, F, 2018. |
| [18] | CHEN J, WU J, KONRAD J, et al. Semi-coupled two-stream fusion convnets for action recognition at extremely low resolutions[C]// Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), F, 2017. IEEE. |
| [19] | XU M, SHARGHI A, CHEN X, et al. Fully-coupled two-stream spatiotemporal networks for extremely low resolution action recognition[C]// Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), F, 2018. |
| [20] | RYOO M, ROTHROCK B, FLEMING C, et al. Privacy-preserving human activity recognition from extreme low resolution[C]// Proceedings of the Proceedings of the AAAI conference on artificial intelligence, F, 2017. |
| [21] | GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial networks[J]. Communications of the ACM, 2020, 63(11): 139-44. |
| [22] | TRAN D, WANG H, TORRESANI L, et al. A closer look at spatiotemporal convolutions for action recognition[C]// Proceedings of the Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, F, 2018. |
| [23] | ZHOU Y, SUN X, LUO C, et al. Spatiotemporal fusion in 3D CNNs: A probabilistic view[C]// Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, F, 2020. |
| [24] | CHEN Y, GE H, LIU Y, et al. Agpn: Action granularity pyramid network for video action recognition[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(8): 3912-3923. |
| [25] | HEDEGAARD L, IOSIFIDIS A. Continual 3D convolutional neural networks for real-time processing of videos[C]// Proceedings of the European Conference on Computer Vision, F, 2022. |
| [26] | KAHATAPITIYA K, RYOO M S. Coarse-fine networks for temporal activity detection in videos[C]// Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, F, 2021. |
| [27] | LI S, WANG Z, LIU Y, et al. FSformer: Fast-Slow Transformer for video action recognition[J]. Image and Vision Computing, 2023, 137. |
| [28] | HUANG Y, LU Z, SHAO Z, et al. Simultaneous denoising and super-resolution of optical coherence tomography images based on generative adversarial network[J]. Optics express, 2019, 27(9): 12289-307. |
| [29] | STROUD J, ROSS D, SUN C, et al. D3d: Distilled 3d networks for video action recognition[C]// Proceedings of the Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, F, 2020. |
| [30] | RAGHAV G, SAMIRA E K, VINCENT M, et al. The ”something something” video database for learning and evaluating visual common sense[J]. In ICCV, 2017, 1(5): 5843-5851. |
| [31] | KINGMA D P, BA J L. Adam: A method for stochastic optimization[J]. arXiv, 2014 https://doi.org/10.48550/arXiv.1412.6980. |
| [32] | XIE S, SUN C, HUANG J, et al. Rethinking spatiotemporal feature learning for video understanding[J]. arXiv preprint arXiv:171204851, 2017. |
| [33] | LIN J, GAN C, HAN S. Tsm: Temporal shift module for efficient video understanding[C]// Proceedings of the Proceedings of the IEEE/CVF international conference on computer vision, F, 2019. |
| [34] | JIANG B, YAN J, WANG M, et al. STM: SpatioTemporal and Motion Encoding for Action Recognition[Z]. 2019 |
| [35] | LI Y, JI B, SHI X, et al. Tea: Temporal excitation and aggregation for action recognition[C]// Proceedings of the Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, F, 2020. |
| [36] | WANG L, TONG Z, JI B, et al. Tdn: Temporal difference networks for efficient action recognition[C]// Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, F, 2021. |
| [37] | LIU Y, YUAN J, TU Z. Motion-driven visual tempo learning for video-based action recognition[J]. IEEE Transactions on Image Processing, 2022, 31: 4104-16. |
| [38] | LI K. Uniformer: Unified transformer for efficient spatial-temporal representation learning[C]// in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit, 2022: 2380-2390. |
| [39] | CARREIRA J, ZISSERMAN A. Quo vadis, action recognition? a new model and the kinetics dataset[C]// Proceedings of the proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, F, 2017. |
| [1] | LI Yong,REN Yongmao,YIN Zhuoran,ZHOU Xu. A Lightweight Traffic Identification Model Based on Deep Learning [J]. Frontiers of Data and Computing, 2025, 7(2): 3-11. |
| [2] | JIN Jiali, GAO Siyuan, GAO Manda, WANG Wenbin, LIU Shaozhen, SUN Zhenan. A Survey of Face Age Editing Based on Generative Adversarial Networks and Diffusion Models [J]. Frontiers of Data and Computing, 2025, 7(1): 38-55. |
| [3] | CHEN Yubin, HONG Ye, CUI Wenjuan, HUANG Minyi, ZHANG Jinyu. A Study on Multidimensional Data-Driven Commodity Demand Forecasting [J]. Frontiers of Data and Computing, 2024, 6(5): 169-177. |
| [4] | YAN Zhiyu, RU Yiwei, SUN Fupeng, SUN Zhenan. Research on Video Behavior Recognition Method with Active Perception Mechanism [J]. Frontiers of Data and Computing, 2024, 6(5): 66-79. |
| [5] | LI Haopeng, ZHOU Wanting, CHEN Yu, ZHANG Man. Domain Independent Cycle-GAN for Cross Modal Medical Image Generation [J]. Frontiers of Data and Computing, 2024, 6(2): 80-88. |
| [6] | SHEN Zhihao, LI Na, YIN Shihao, DU Yi, HU Lianglin. Airfare Price Prediction Based on TPA-Transformer [J]. Frontiers of Data and Computing, 2023, 5(6): 115-125. |
| [7] | JI Jingjing, XI Zhenghao, LI Zhongfeng. The Study of Coal Macerals Segmentation and Quantitative Analysis Based on MSR-UNet [J]. Frontiers of Data and Computing, 2023, 5(6): 126-137. |
| [8] | WANG Ziyuan, WANG Guozhong. Application of Improved Lightweight YOLOv5 Algorithm in Pedestrian Detection [J]. Frontiers of Data and Computing, 2023, 5(6): 161-172. |
| [9] | LANG Xiaoqi, ZHANG Juan. Connected Deraining Network Based on Multi-Scale and Cyclic Generative Adversarial [J]. Frontiers of Data and Computing, 2023, 5(5): 128-139. |
| [10] | ZHANG Rong, LIU Yuan. Multi-Level Data Augmentation Method for Aspect-Based Sentiment Analysis [J]. Frontiers of Data and Computing, 2023, 5(5): 140-153. |
| [11] | JU Jiaji, HUANG Bo, ZHANG Shuai, GUO Ruyan. A Dual-Channel Sentiment Analysis Model Integrating Sentiment Lexcion and Self-Attention [J]. Frontiers of Data and Computing, 2023, 5(4): 101-111. |
| [12] | ZHANG Xiaofan, SUN Haichun, LI Xin. Hierarchical Attention-Based Bidirectional Long Short-Term Memory Networks for Knowledge Graph Completion [J]. Frontiers of Data and Computing, 2023, 5(3): 123-137. |
| [13] | LIU Yunfan,LI Qi,SUN Zhenan,TAN Tieniu. Face Age Editing Methods Based on Generative Adversarial Network: A Survey [J]. Frontiers of Data and Computing, 2023, 5(2): 2-23. |
| [14] | ZHANG Shuai,HUANG Bo,JU Jiaji. An Improved Sentiment Analysis Model Incorporating Textual Topic Features [J]. Frontiers of Data and Computing, 2022, 4(6): 118-128. |
| [15] | ZHAO Zhongbin,CAI Manchun,LU Tianliang. Network Malicious Traffic Detection Incorporating Multi-Head Attention Mechanism [J]. Frontiers of Data and Computing, 2022, 4(5): 60-67. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||