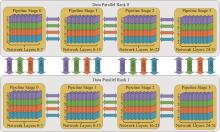
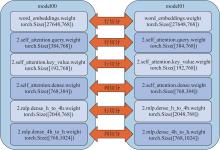
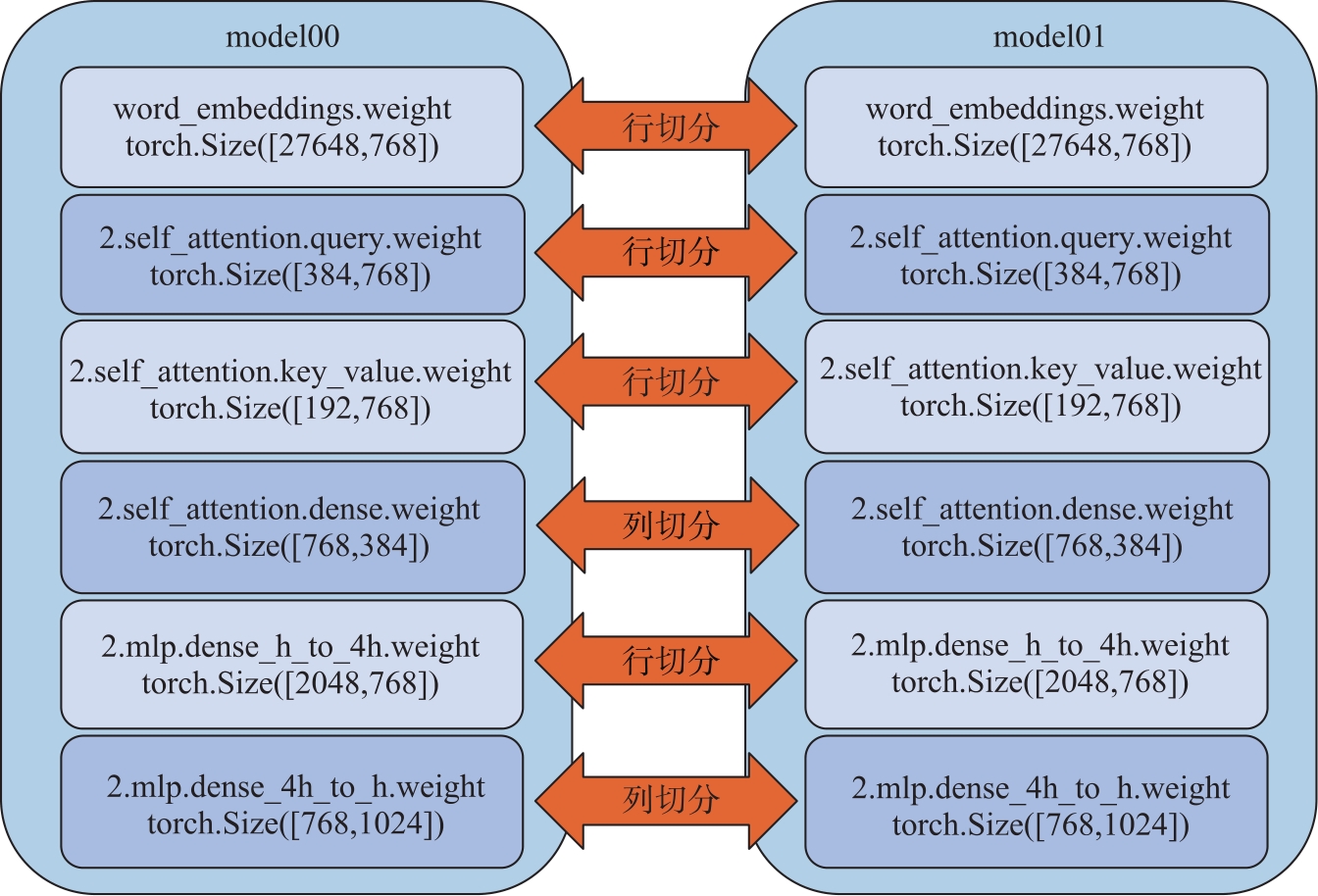
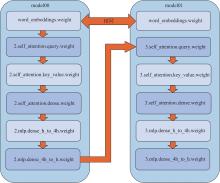
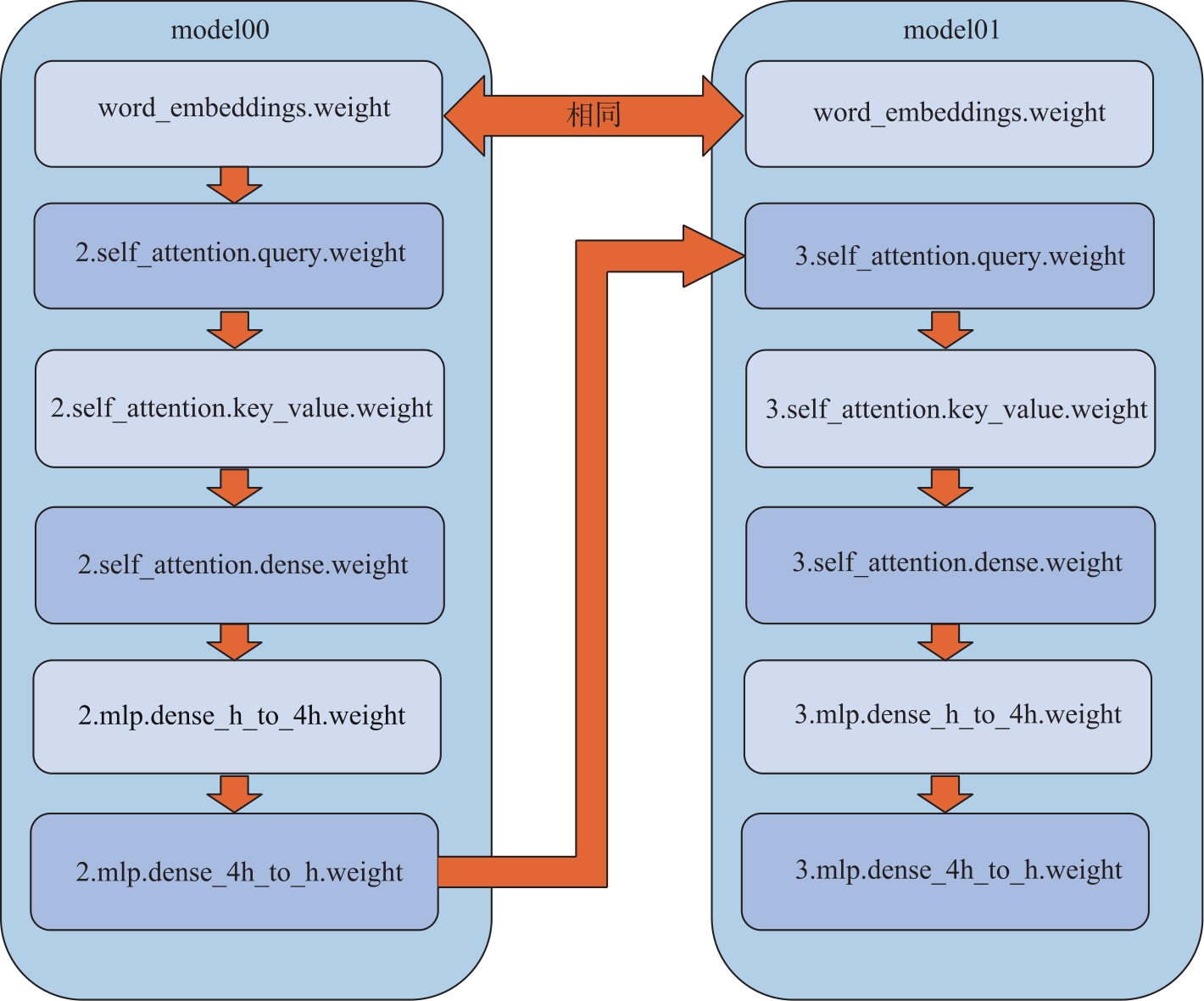
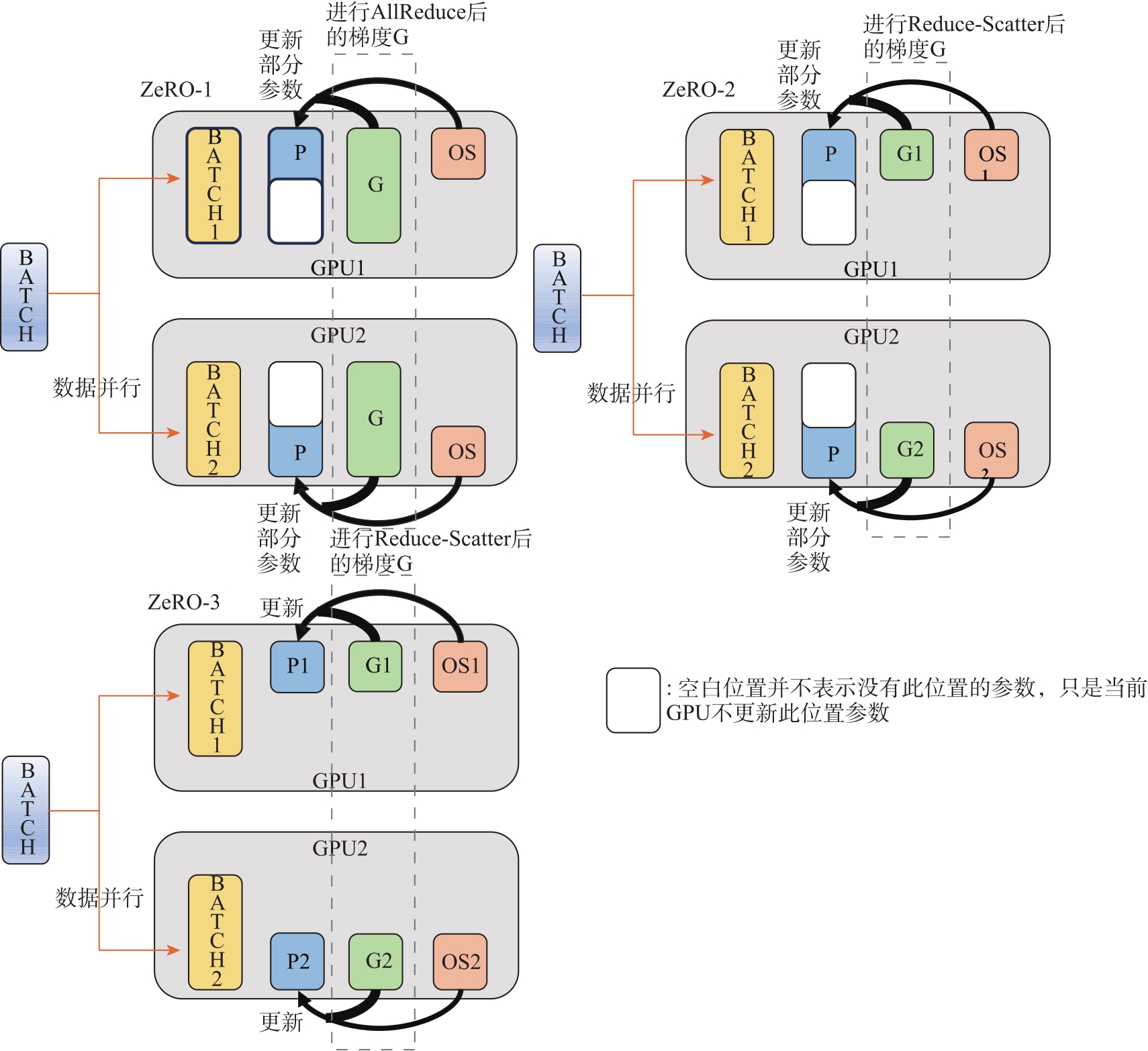
| [1] |
TOUVRON H, LAVRIL T, IZACARD G, et al. Llama: Open and efficient foundation language models[EB/OL]. [2023-02-27]. https://arxiv.org/abs/2302.13971.
|
| [2] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// 31st Conference on Neural Information Processing Systems(NIPS 2017), California, USA: Curran Associates, 2017: 5998-6008.
|
| [3] |
PASZKE A, GROSS S, MASSA F, et al. Pyto-rch: An imperative style, high-performance dee-p learning library[J]. Advances in neural infor-mation processing systems, 2019, 32: 8026-8037.
|
| [4] |
SERGEEV A, DEL BALSO M. Horovod: fast a-nd easy distributed deep learning in TensorFlo-w[EB/OL]. [2020-08-10]. https://arxiv.org/abs/1802.05799.
|
| [5] |
BI R, XU T, XU M, et al. PaddlePaddle: A P-roduction-Oriented Deep Learning Platform Fac-ilitating the Competency of Enterprises[C]// 2022IEEE 24th Int Conf on High Performance Co-mputing & Communications; 8th Int Conf on Data Science & Systems; 20th Int Conf on S-mart City; 8th Int Conf on Dependability in S-ensor, Cloud & Big Data Systems & Applicati-on (HPCC/DSS/SmartCity/DependSys), IEEE, 2022: 92-99.
|
| [6] |
MAI L, Li G, WAGENLÄNDER M, et al. {K-ungFu}: Making training in distributed machine learning adaptive[C]// 14th USENIX Symposiumon Operating Systems Design and Implementation (OSDI 20), 2020: 937-954.
|
| [7] |
QIAO A, CHOE S K, SUBRAMANYA S J, et al. Pollux: Co-adaptive cluster scheduling for goodput-optimized deep learning[C]// 15th {USENIX} Symposium on Operating Systems Design and Implementation (OSDI’21), 2021:1.
|
| [8] |
GUO R B, GUO V, KIM A, et al. Hydrozoa: Dynamic Hybrid-Parallel DNN Training on Serverless Containers[C]// Machine Learning and Systems 4, 2020: 779-794.
|
| [9] |
HE C, LI S, SOLTANOLKOTABI M, et al. PipeTransformer: Automated Elastic Pipelining for Distributed Training of Transfor-mers[EB/OL].[2021-02-12]. https://arxiv.org/abs/2102.03161.
|
| [10] |
SHOEYBI M, PATWARY M, PURI R, et al. Megatron-lm: Training multi-billion parameter l-anguage models using model parallelism[EB/OL]. [2020-03-13]. https://arxiv.org/abs/1909.08053.
|
| [11] |
RAJBHANDARI S, RASLEY J, RUWASE O, et al. Zero: Memory optimizations toward train-ing trillion parameter models[C]//SC20:Interna-tional Conference for High Performance Comp-uting, Networking, Storage and Analysis, IEEE, 2020: 1-16.
|
| [12] |
DEAN J, CORRADO G, MONGA R, et al. L-arge scale distributed deep networks[J]. Advan-ces in neural information processing systems, 2012, 25: 1223-1231.
|
| [13] |
HUANG Y, CHENG Y, BAPNA A, et al. Gpi-pe: Efficient training of giant neural networks using pipeline parallelism[J]. Advances in neur-al information processing systems, 2019, 32: 103-112.
|
| [14] |
Microsoft Research. DeepSpeed: Extreme-scale model training for everyone[EB/OL]. (2020-09-10)[2024-06-30]. https://www.microsoft.com/en-us/research/blog/deepspeed-extreme-scale-model-training-for-everyone/.
|
 ),LI Kai1,CAO Rongqiang1,ZHOU Chunbao1,*(
),LI Kai1,CAO Rongqiang1,ZHOU Chunbao1,*(