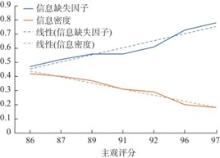
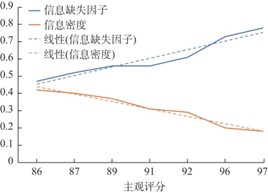
| [1] |
王骞, 雷景生, 唐小岚. 融合多层注意力表示的中文新闻文本摘要生成[J]. 计算机应用与软件, 2023, 40 (10): 191-198.
|
| [2] |
张琪, 范永胜, 金独亮. 基于MMR和WordNet的新闻文本摘要生成研究[J]. 西南师范大学学报(自然科学版), 2023, 48 (5): 77-86.
|
| [3] |
史继筠, 张驰, 王禹桥, 等. 基于知识辅助的结构化医疗报告生成[J/OL]. 计算机科学, 1-13[2024-05-18]. http://kns.cnki.net/kcms/detail/50.1075.TP.20240321.1439.003.html.
|
| [4] |
赵冠博, 张勇入领域知识的跨境民族文化生成式摘要方法[J]. 南京大学学报(自然科学), 2023, 59 (4): 620-628.
|
| [5] |
赵伟, 王文娟, 任彦凝, 等. 基于改进Transformer的生成式文本摘要模型[J]. 重庆邮电大学学报(自然科学版), 2023, 35 (1): 185-192.
|
| [6] |
施国良, 周抒, 王云峰, 等. 基于改进多头注意力机制的专利文本摘要生成研究[J]. 数据分析与知识发现, 2023, 7 (6): 61-72.
|
| [7] |
WANG Q, LIU P, ZHU Z, et al. A text abstraction summary model based on BERT word embedding and reinforcement learning[J]. Applied Sciences, 2019, 9(21): 4701.
|
| [8] |
DING J, LI Y, NI H, et al. Generative text summary based on enhanced semantic attention and gain-benefit gate[J]. IEEE Access, 2020, 8: 92659-92668.
|
| [9] |
魏鑫炀, 秦永彬, 唐向红, 等. 融合法条的司法裁判文书摘要生成方法[J]. 计算机工程与设计, 2023, 44 (9): 2844-2850.
|
| [10] |
祁鹏年, 廖雨伦, 覃飙. 基于深度学习的中文命名实体识别研究综述[J]. 小型微型计算机系统, 2023, 44 (9): 1857-1868.
|
| [11] |
LI J, FEI H, LIU J, et al. Unified named entity recognition as word-word relation classification[C]// Proceedings of the AAAI Conference on Artificial Intelligence, 2022, 36(10): 10965-10973.
|
| [12] |
QI P, QIN B. SSMI: semantic similarity and mutual information maximization based enhancement for Chinese NER[C]// Proceedings of the AAAI Conference on Artificial Intelligence, 2023, 37(11): 13474-13482.
|
| [13] |
ZHAO X, GREENBERG J, AN Y, et al. Fine-tuning BERT model for materials named entity recognition[C]// 2021 IEEE International Conference on Big Data (Big Data), IEEE, 2021: 3717-3720.
|
| [14] |
刘蓓, 许卓明, 陶皖, 等. 少样本关系抽取研究综述[J]. 计算机工程与应用, 2023, 59 (15): 27-37.
|
| [15] |
NAYAK T, NG H T. Effective modeling of encoder-decoder architecture for joint entity and relation extraction[C]// Proceedings of the AAAI conference on artificial intelligence, 2020, 34(05): 8528-8535.
|
| [16] |
XUE F, SUN A, ZHANG H, et al. Gdpnet: Refining latent multi-view graph for relation extraction[C]// Proceedings of the AAAI Conference on Artificial Intelligence, 2021, 35(16): 14194-14202.
|
| [17] |
卢经纬, 郭超, 戴星原, 等. 问答ChatGPT之后: 超大预训练模型的机遇和挑战[J]. 自动化学报, 2023, 49(4):705-717.
|
| [18] |
杨波, 孙晓虎, 党佳怡, 等. 面向医疗问答系统的大语言模型命名实体识别方法[J]. 计算机科学与探索, 2023, 17 (10): 2389-2402.
|
| [19] |
王昀, 胡珉, 塔娜, 等. 大语言模型及其在政务领域的应用[J/OL]. 清华大学学报(自然科学版), 1-10 [2023-11-26] https://doi.org/10.16511/j.cnki.qhdxxb.2023.26.042.
|
| [20] |
徐月梅, 胡玲, 赵佳艺, 等. 大语言模型的技术应用前景与风险挑战[J]. 计算机应用, 2024, 44(6):1655-1662.
|
| [21] |
秦菲. 基于深度学习的自动生成文本摘要及其评估的研究[D]. 桂林: 桂林电子科技大学, 2020.
|
| [22] |
LIN C Y. Rouge: A package for automatic evaluation of summaries[C]// Text summarization branches out, 2004: 74-81.
|
| [23] |
MENG K, SHARMA A S, ANDONION A, et al. Mass-editing memory in a transformer[J]. arXiv preprint arXiv:2210.07229, 2022.
|
| [24] |
SEE A, LIU P J, MANNING C D. Get to the point: Summarization with pointer-generator networks[J]. arXiv preprint arXiv:1704.04368, 2017.
|
| [25] |
GU J, LU Z, LI H, et al. Incorporating copying mechanism in sequence-to-sequence learning[J]. arXiv preprint arXiv:1603.06393, 2016.
|
| [26] |
BLEI D M, NG A Y, JORDAN M I. Latent dirichlet allocation[J]. Journal of machine Learning research, 2003, 3(1): 993-1022.
|
| [27] |
SOUZA F, NOGUEIRA R, LOTUFO R. Portuguese named entity recognition using BERT-CRF[J]. arXiv preprint arXiv:1909.10649, 2019.
|
| [28] |
WU S, SONG X, FENG Z. MECT: Multi-metadata embedding based cross-transformer for Chinese na- med entity recognition[J]. arXiv preprint arXiv: 2107.05418, 2021.
|
| [29] |
SNELL J, SWERSKY K, ZEMEL R. Prototypical networks for few-shot learning[J]. Advances in neural information processing systems, 2017, 30:4077-4087.
|
| [30] |
HE K, HUANG Y, MAO R, et al. Virtual prompt pre-training for prototype-based few-shot relation extraction[J]. Expert Systems with Applications, 2023, 213: 118927.
|
 ),LI Xin*(
),LI Xin*(