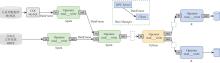
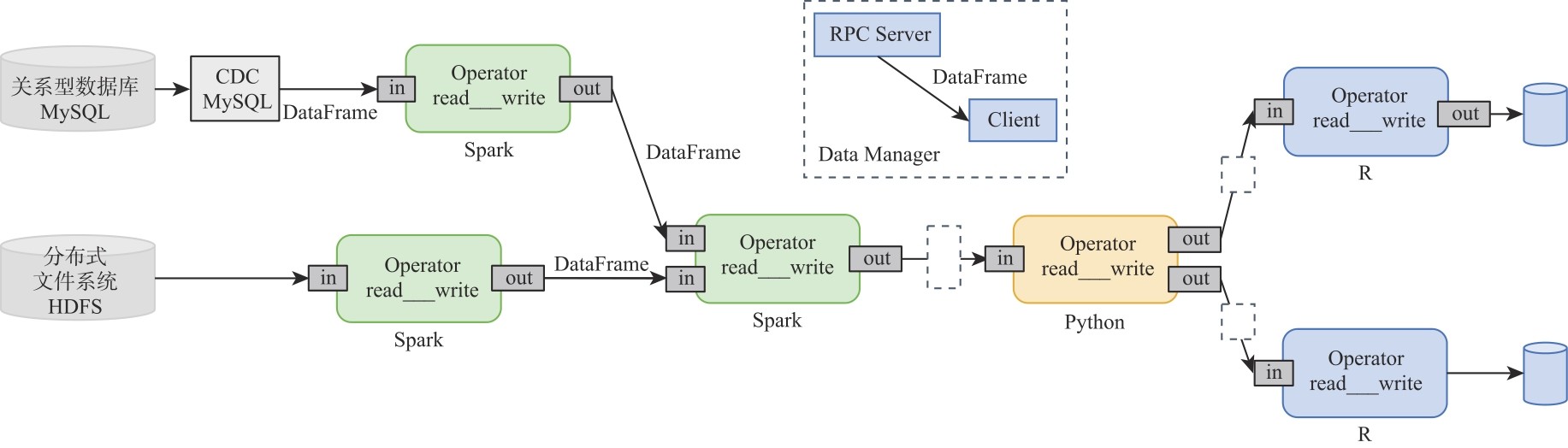
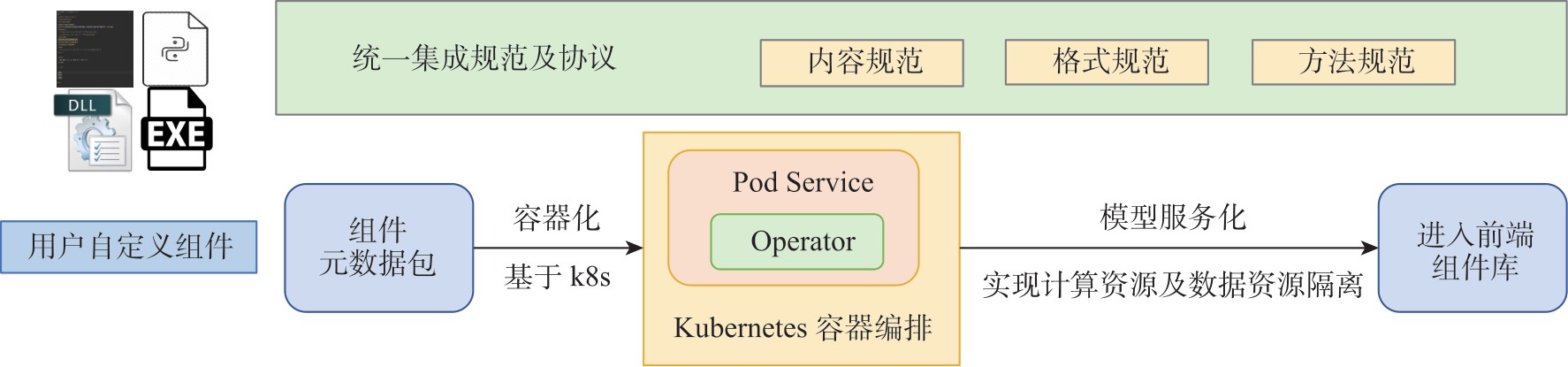
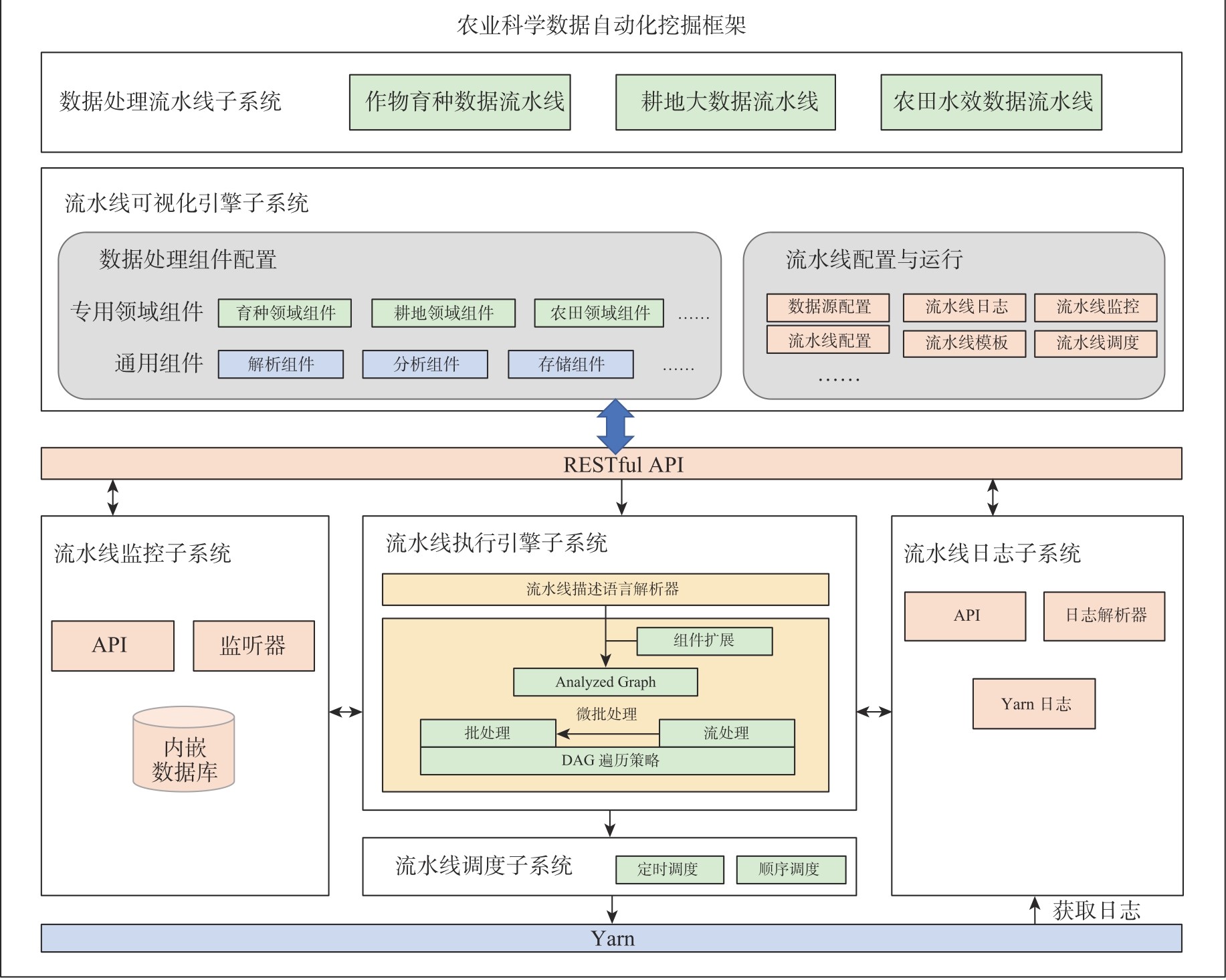
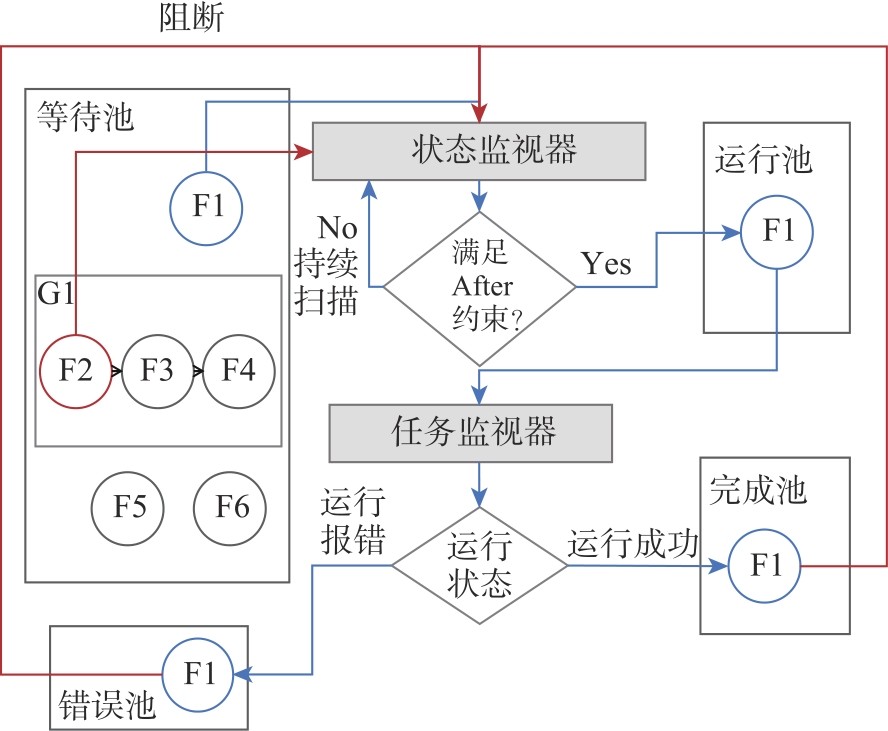
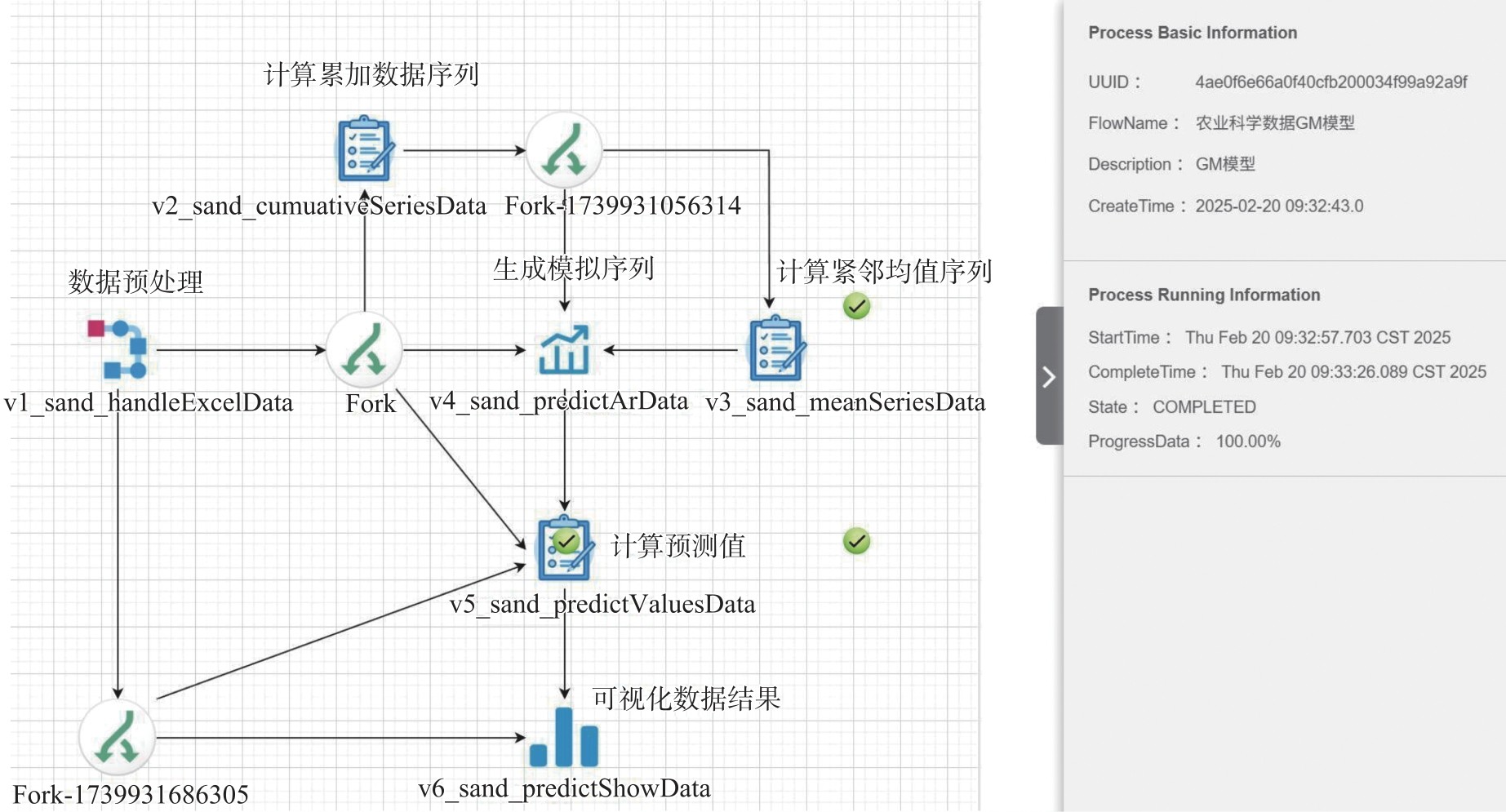
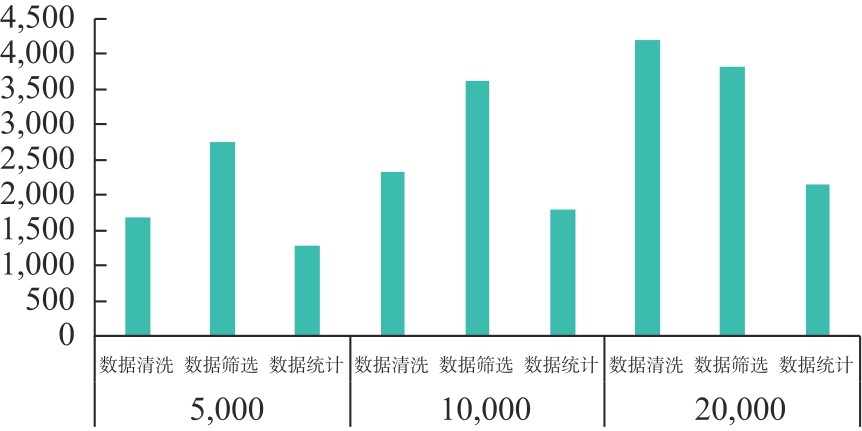
| [1] |
周国民. 我国农业大数据应用进展综述[J]. 农业大数据学报, 2019, 1(1): 16-23.
|
| [2] |
张学福, 孙巍, 吴蕾. 农业大数据研究进展(2024)[J]. 农业大数据学报, 2024, 6(4): 433-468.
|
| [3] |
DEAN J, GHEMAWAT S. MapReduce: simplified data processing on large clusters[J]. Communications of the ACM, 51(1): 107-113.
|
| [4] |
ZAHARIA M, CHOWDHURY M, FRANKLIN M J, et al. Spark: Cluster Computing with Working Sets[C]// Proceedings of the 2nd USENIX Conference on Hot Topics in Cloud Computing, 2010: 10-10.
|
| [5] |
SHVACHKO K, KUANG H, RADIA S, et al. The Hadoop Distributed File System[C/OL]// IEEE Symposium on Mass Storage Systems & Technologies. 2010[2025-04-02]. https://www.zhangqiaokeyan.com/academic-conference-foreign_meeting-257960_thesis/0705010576461.html.
|
| [6] |
孟祥宝, 谢秋波, 刘海峰, 等. 农业大数据应用体系架构和平台建设[J]. 广东农业科学, 2014(14): 173-178.
|
| [7] |
YASMIN J, WANG J A, TIAN Y, et al. An empirical study of developers’ challenges in implementing Workflows as Code: A case study on Apache Airflow[J]. The Journal of Systems and Software, 2025, 219: 1222-1269.
|
| [8] |
席磊, 马新明, 余华, 等. 农业智能决策系统开发平台的研究[J]. 河南农业大学学报, 2002, 36(3): 288-292.
|
| [9] |
JIA L, WANG J, LIU Q, et al. Application Research of Artificial Intelligence Technology in Intelligent Agriculture[C]// The 10th International Conference on Computer Engineering and Networks. Singapore: Springer, 2021: 219-225.
|
| [10] |
CARBONE P, KATSIFODIMOS A, Ewen S, et al. Apache flink : Stream and batch processing in a single engine[J/OL]. IEEE Computer Society, 2015[2025-04-02]. http://www.researchgate.net/publication/308993790_Apache_Flink_Stream_and_Batch_Processing_in_a_ Single_Engine.
|
| [11] |
Flink在农业物联网实时数据处理中的应用[EB/OL]. [2025-04-02].https://www.dtstack.com/bbs/article/14985.
|
| [12] |
BISONG E. Google Cloud Dataflow[J/OL]. Building Machine Learning and Deep Learning Models on Google Cloud Platform, 2019[2025-04-02]. http://www.semanticscholar.org/paper/143607fde87c76083 5656b34a5e05ec733ad0ca2.
|
| [13] |
朱小杰, 赵子豪, 杜一. 模型驱动的大数据流水线框架PiFlow[J]. 计算机应用, 2020, 40(6): 1638-1647.
|
| [14] |
GIUSI M, GENNARO C, JACK K, et al. Using Directed Acyclic Graphs in Epidemiological Research in Psychosis: An Analysis of the Role of Bullying in Psychosis[J]. Schizophrenia Bulletin, 2017, 43(6): 1273-1279.
|
| [15] |
HE P, ZHU J, XU P, et al. A Directed Acyclic Graph Approach to Online Log Parsing[J/OL]. [2025-04-02]. http://arxiv.org/abs/1806.04356v1.
|
| [16] |
NORCOTT W D.High-performance change capture for data warehousing[P/OL]. 2003[2025-04-02].https://wenku.baidu.com/view/4e4dd014fc00bed5b9f3f90f76c66137ee064ff5?fr=xueshu_top.
|
| [17] |
羌翼亭, 陈昊鹏. 一种基于新型事件驱动机制的Java构件交互方法[J]. 计算机工程, 2007(15): 103-105.
|
| [18] |
ARDAGNA C A, BELLANDI V, CERAVOLO P, et al. A Model-Driven Methodology for Big Data Analytics-as-a-Service[J]. 2017 IEEE International Congress on Big Data (BigData Congress), 2017: 105-112.
|
| [19] |
KLEPPE A, WARMER J, BAST W. MDA Explained:The Model Driven Architecture : Practice and Promise[M]. USA: Addison-Wesley Longman Publishing Co., Inc., 2003.
|
| [20] |
BRAMBILLA M, CABOT J, WIMMER M. Model-Driven Software Engineering in Practice[M]. 2nd Ed. Cham: Springer, 2017.
|
| [21] |
PUERTA A, EISENSTEIN J. Towards a general computational framework for model-based interface development systems[J]. Knowledge-Based Systems, 1999, 12(8): 433-442.
|
| [22] |
杜一, 邓昌智, 田丰. 一种可扩展的用户界面描述语言[J]. 软件学报, 2013, 24(5): 1127-1142.
|
| [23] |
杜一, 郭旦怀, 陈昕, 等. 一种模型驱动的可视化生成系统[J]. 软件学报, 2016, 27(5): 1199-1211.
|
 ),路长发,朱小杰*(
),路长发,朱小杰*(