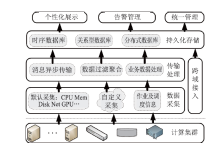
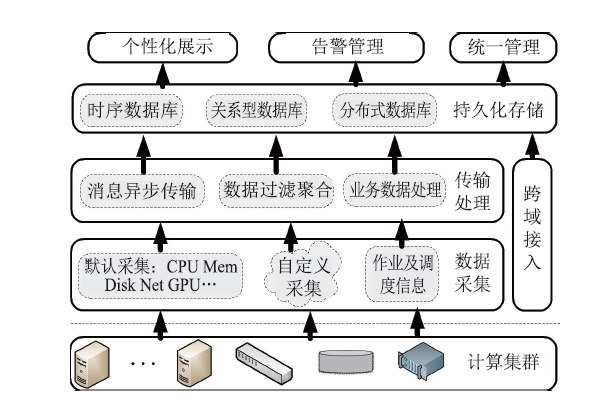
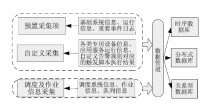
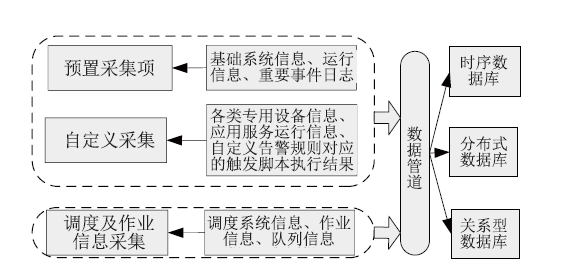
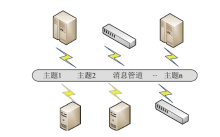
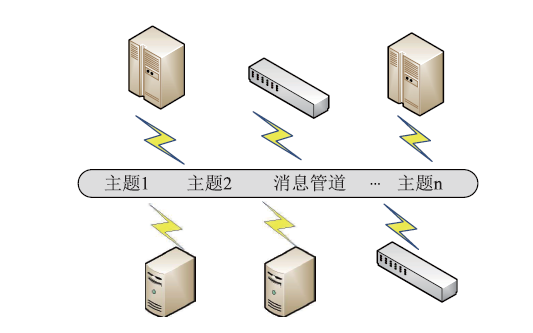
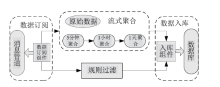
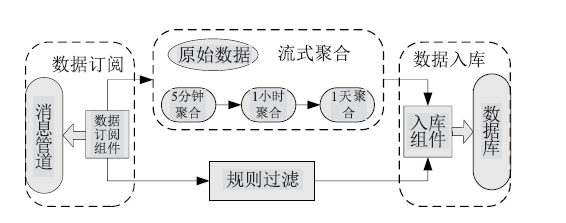
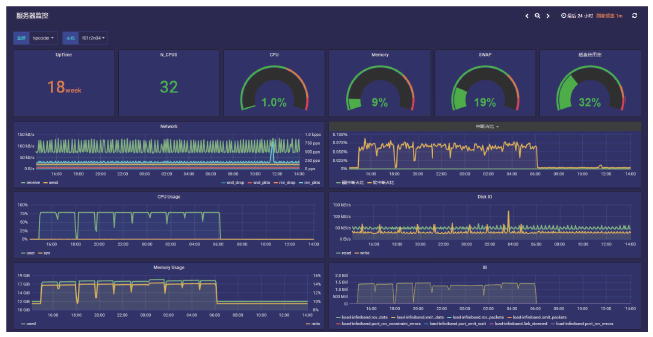
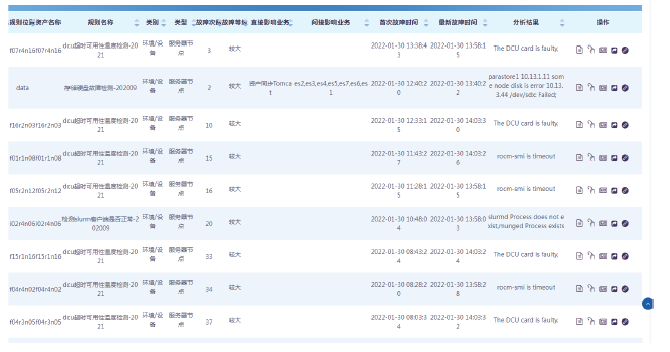
Frontiers of Data and Computing ›› 2023, Vol. 5 ›› Issue (1): 97-103.
CSTR: 32002.14.jfdc.CN10-1649/TP.2023.01.009
doi: 10.11871/jfdc.issn.2096-742X.2023.01.009
• Technology and Application • Previous Articles Next Articles
PENG Liang*( ),NIU Tie,WEI Baoliang,ZHAO Yi
),NIU Tie,WEI Baoliang,ZHAO Yi