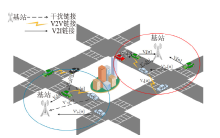
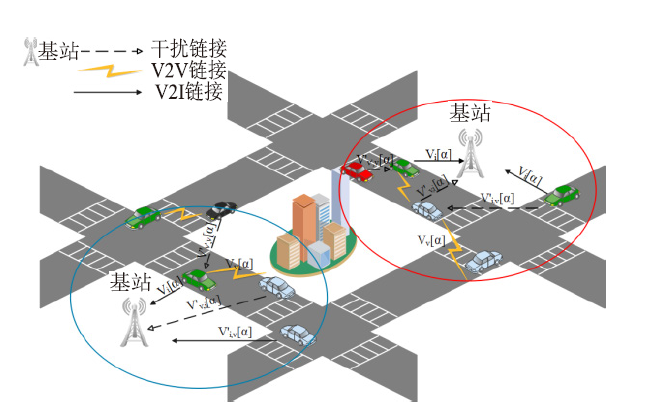
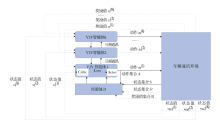
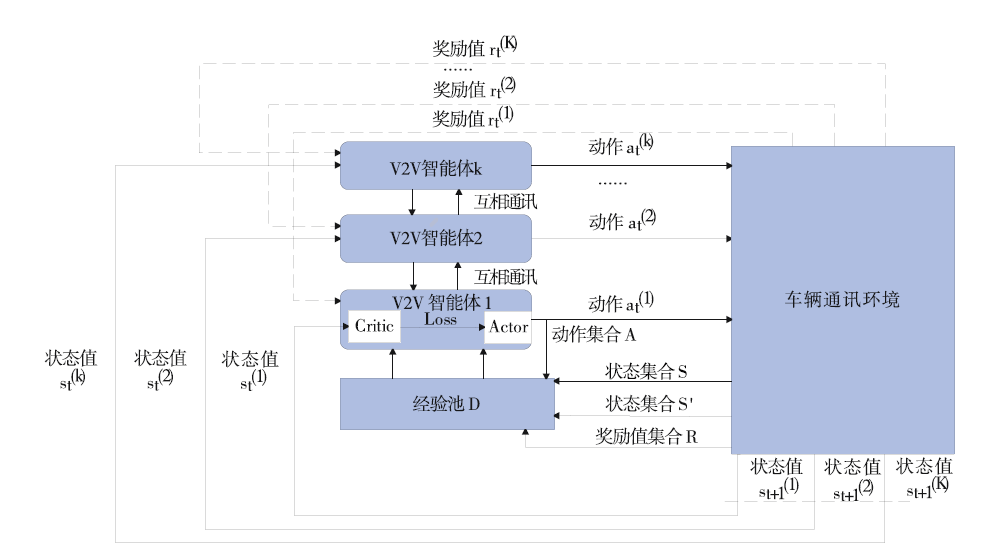
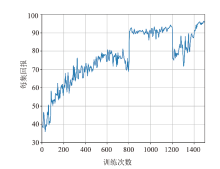
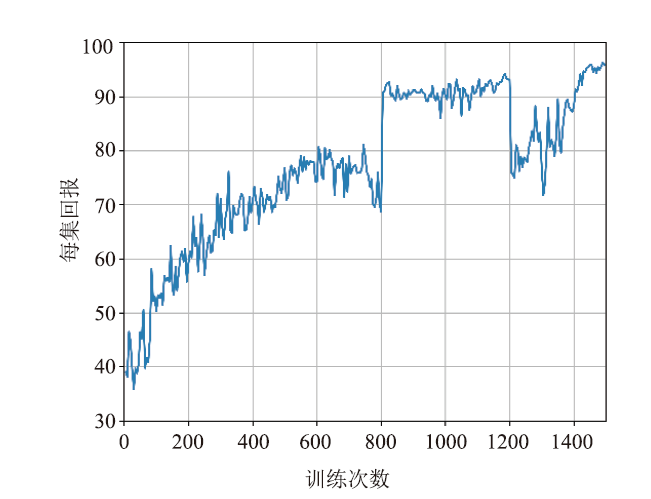
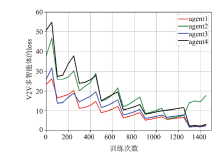
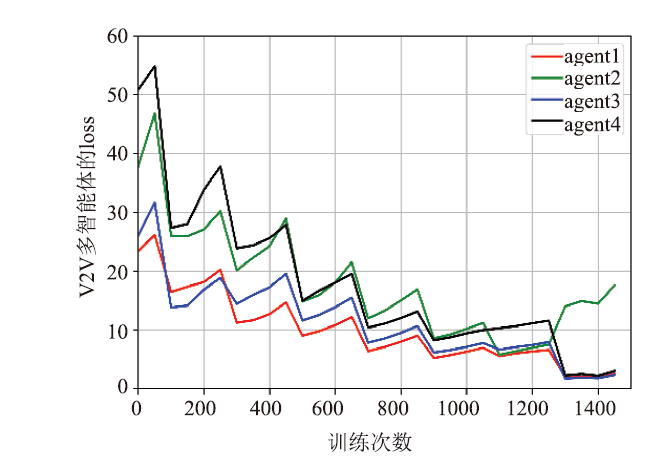
| [1] |
Rasheed A, Chong P H J, Ho I W H, et al. An overview of mobile edge computing: Architecture, technology and direction[J]. KSII Transactions on Internet and Inform-ation Systems (TIIS), 2019, 13(10): 4849-4864.
|
| [2] |
Chen C, Ding Y, Xie X, et al. TrajCompressor: An online map-matching-based trajectory compression framework leveraging vehicle heading direction and change[J]. IEEE Transactions on Intelligent Transportation Systems, 2019, 21(5): 2012-2028.
doi: 10.1109/TITS.2019.2910591
|
| [3] |
Xiao Z, Shen X, Zeng F, et al. Spectrum resource sharing in heterogeneous vehicular networks: A noncooperative game-theoretic approach with correlated equilibrium[J]. IEEE Transactions on Vehicular Technology, 2018, 67 (10): 9449-9458.
doi: 10.1109/TVT.2018.2855683
|
| [4] |
Luo Q, Li C, Luan T H, et al. Optimal utility of vehicles in LTE-V scenario: An immune clone-based spectrum allocation approach[J]. IEEE Transactions on Intelligent Transportation Systems, 2018, 20(5): 1942-1953.
doi: 10.1109/TITS.2018.2850311
|
| [5] |
Li R, Jin L. Improved cuckoo algorithm for spectrum allocation in cognitive vehicular network[C]// 2018 5th International Conference on Systems and Informatics (ICSAI), IEEE, 2018: 828-833.
|
| [6] |
Li Q, Qi W, Guo L. A Prediction-Based Spectrum Al-location Scheme for Two-Layer Cellular Vehicular Netw-orks[C]// 2020 IEEE/CIC International Conference on Communications in China (ICCC), IEEE, 2020: 858-863.
|
| [7] |
Liu J, Wang S, Wang J, et al. A task oriented computation offloading algorithm for intelligent vehicle network with mobile edge computing[J]. IEEE Access, 2019, 7: 180491-180502.
doi: 10.1109/ACCESS.2019.2958883
|
| [8] |
Zia K, Javed N, Sial M N, et al. A distributed multi-agent RL-based autonomous spectrum allocation scheme in D2D enabled multi-tier HetNets[J]. IEEE Access, 2019, 7: 6733-6745.
doi: 10.1109/ACCESS.2018.2890210
|
| [9] |
Liang L, Ye H, Li G Y. Spectrum sharing in vehicular networks based on multi-agent reinforcement learning[J]. IEEE Journal on Selected Areas in Communications, 2019, 37(10): 2282-2292.
doi: 10.1109/JSAC.2019.2933962
|
| [10] |
Yang H, Xie X, Kadoch M. Intelligent resource manag-ement based on reinforcement learning for ultra-reliable and low-latency IoV communication networks[J]. IEEE Transactions on Vehicular Technology, 2019, 68(5): 4157-4169.
doi: 10.1109/TVT.2018.2890686
|
| [11] |
Prasad R. OFDM for wireless communications systems[M]. Artech House, 2004:83-116
|
| [12] |
Li B, He D, Feng Y, et al. Spectrum resource alloca-tion scheme for alarm information delivery in V2V communication[C]// 2018 IEEE 88th Vehicular Techn-ology Conference (VTC-Fall), IEEE, 2018: 1-5.
|
| [13] |
Wang Y, He H, Tan X. Truly proximal policy optim-ization[C]// Uncertainty in Artificial Intelligence, PMLR, 2020: 113-122.
|
| [14] |
Schulman J, Wolski F, Dhariwal P, et al. Proximal policy optimization algorithms[J]. arXiv preprint arXiv: 1707. 06347, 2017.
|
| [15] |
LeCun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015, 521(7553): 436-444.
doi: 10.1038/nature14539
|
| [16] |
Wang X, Mao S, Gong M X. An overview of 3GPP cell-ular vehicle-to-everything standards[J]. GetMobile: Mobile Computing and Communications, 2017, 21(3): 19-25.
|
| [17] |
Chen S, Hu J, Shi Y, et al. Vehicle-to-everything (V2X) services supported by LTE-based systems and 5G[J]. IE-EE Communications Standards Magazine, 2017, 1(2): 70-76.
|
| [18] |
R1-165704. WF on SLS evaluation assumptions for eV2X[S]. 3GPP TSG RAN WG 1 Meeting #85, 2016.
|
| [19] |
Marsch P, Da Silva I, Bulakci O, et al. 5G radio access network architecture: Design guidelines and key consid-erations[J]. IEEE Communications Magazine, 2016, 54 (11): 24-32.
|
| [20] |
3rd Generation Partnership Project. Technical specific-ation group radio access network[S]. Study on LTE-based V2X Services (Release14). 3GPP TR 36.885 V14.0.0, 2016.
|
| [21] |
Li S, Hu X, Du Y. Deep Reinforcement Learning and Game Theory for Computation Offloading in Dynamic Edge Computing Markets[J]. IEEE Access, 2021, 9: 121456-121466.
doi: 10.1109/ACCESS.2021.3109132
|
| [22] |
Li S, Hu X, Du Y. Deep Reinforcement Learning for Computation Offloading and Resource Allocation in Unm-anned-Aerial-Vehicle Assisted Edge Computing[J]. Sen-sors, 2021, 21(19): 6499.
|
 ),HU Xiaohui,DU Xinxin
),HU Xiaohui,DU Xinxin