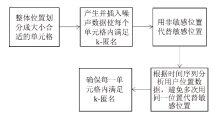
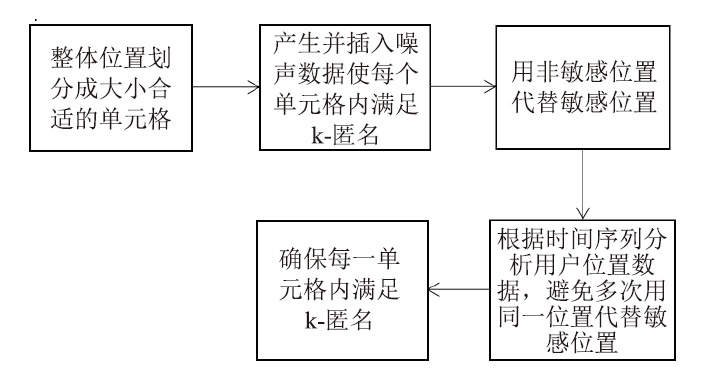
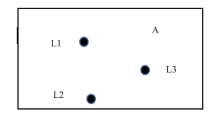
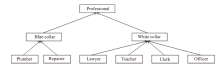
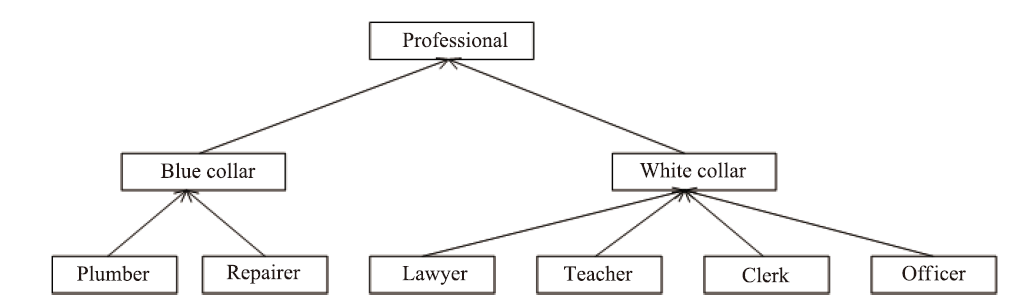
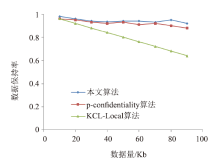
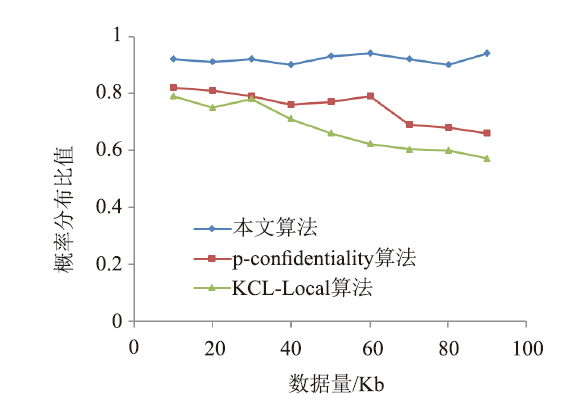
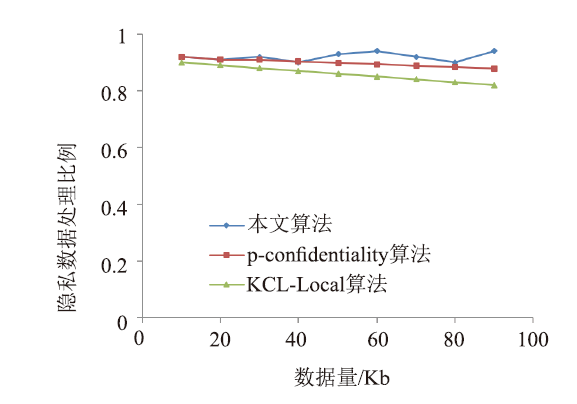
| [1] |
Song Fagen, Ma Tinghuai, Tian Yuan, et al. A new method of privacy protection: random k-anonymous[J]. IEEE Access, 2019, 7: 75434-75445.
doi: 10.1109/ACCESS.2019.2919165
|
| [2] |
Zhang S, Li X, Tan Z, et al. A caching and spatial K-an-onymity driven privacy enhancement scheme in conti-nuous location-based services[J]. Future Generation Co-mputer Systems, 2019, 94: 40-50.
|
| [3] |
Chenglong L I, Xin L V, Xin L I. Dynamic K-anonymity algorithm for resisting prediction attack based on his-torical trajectories[J]. Computer Engineering and Appli-cations, 2018, 54(02):119-124.
|
| [4] |
Chengming Li, Pengda Wu, Yong Yin, Wei Wu. An im-proved partitioning method for dissolving long and narrow patches[J]. Computers and Geosciences, 2020, 138(C):104358-104358.
|
| [5] |
Komisbani E G, Abadi M, Deldar F. PPTD: Preserving personalized privacy in trajectory data publishing by sensitive attribute generalization and trajectory local suppression[J]. Knowledge-Based Systems, 2016, 94(1): 43-59.
doi: 10.1016/j.knosys.2015.11.007
|
| [6] |
Rasheed F, Yau K, Low Y C. Deep reinforcement lear-ning for traffic signal control under disturbances: A case study on Sunway city, Malaysia[J]. Future Generation Computer Systems, 2020,109 (prepublish): 431-445.
|
| [7] |
Wan Sheng, Li Fenghua, Niu Ben, et al. Research pro-gress on location privacy-preserving techniques[J]. Jour-nal on Communications, 2016, 37(12): 124-141.
|
| [8] |
Li Xingchang, Wang Bin, Wang Chao, et al. Location privacy protection method based encryption and segme-ntation[J]. Application Research of Computers, 2021, 38(10): 3153-3156.
|
| [9] |
Sweeney L. Guaranteeing Anonymity when Sharing Me-dical Data, the Datafly System[C]. Proceedings: a con-ference of the American Medical Informatics Association. AMIA Annual Fall Symposium. AMIA Fall Symposium, 1997, 4:51-55.
|
| [10] |
林国滨, 姚志强, 熊金波, 林铭炜. 基于 KD 树的信息发布隐私保护[J]. 计算机系统应用, 2017, 26(8): 206-211.
|
| [11] |
武思慧. 粗糙集与聚类支持下的 t-closeness 隐私保护模型研究[D]. 山西: 山西师范大学, 2015.
|
| [12] |
Benjamin C. M. Fung, Ke Wang, Rui Chen, Philip S. Yu. Privacy-preserving data publishing[J]. ACM Computing Surveys (CSUR), 2010, 42(4):1-53.
|
| [13] |
Mokbel M F, Chow C Y, Aref W G. The new casper: Query processing for location services without compro-mising privacy[C]// Proceedings of the 32nd international conference on Very large data bases, 2006: 763-774.
|
| [14] |
Xu Y, Fung B C M, Wang K, et al. Publishing sensitive transactions for itemset utility[C]// Proceedings of the8th IEEE International Conference on Data Mining, 2008: 1109-1114.
|
| [15] |
Bonchi F, Lakshmanan L V S, Wang H. Trajectory anon-ymity in publishing personal mobility data[J]. ACM SIG-KDD Explorations Newsletter, 2011, 13(1):30-42.
|
| [16] |
Sui P, Wo T, Wen Z, et al. Privacy-preserving trajectory publication against parking point attacks[C]// Proceedings of the 2013 IEEE 10th International Conference on Ubiq-uitous Intelligence & Computing Autonomic & Trusted Computing, 2013:569-574.
|
| [17] |
Palanisamy B, Ling L. MobiMix: Protecting location privacy with mix-zones over road networks[C]// Procee-dings of the 27th International Conference on Data Eng-ineering, ICDE 2011, April 11-16, 2011, Hannover, Ger-many, IEEE, 2011:779-789.
|
| [18] |
G ötz M, Nath S, Gehrke J. MaskIt: privately releasing user context streams for personalized mobile applications[C]. In Proc. of the 2012 ACM SIGMOD Int’l Conf. on Management of Data, Scottsdale:ACM, 2012: 289-300.
|
| [19] |
Sefati S S, Navimipour N J. A QoS-Aware Service Com-position Mechanism in the Internet of Things Using a Hi-dden-Markov-Model-Based Optimization Algorithm[J]. IEEE Internet of Things Journal, 2021, PP(99):1-1.
|
| [20] |
Chen R, Fung B C M, Mohammed N, et al. Privacy-preserving trajectory data publishing by local suppres-sion[J]. Information Sciences, 2013, 231: 83-97.
doi: 10.1016/j.ins.2011.07.035
|
| [21] |
林国滨. 面向电子病例数据发布的隐私保护算法研究[D]. 福建: 福建师范大学, 2017.
|
| [22] |
LATANYA SWEENEY. k-ANONYMITY: A MODEL FOR PROTECTING PRIVACY[J]. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 2002, 10(5):557-570.
doi: 10.1142/S0218488502001648
|
| [23] |
Ma Chunguang, Zhang Lei, Yang Songtao, et al. Achieve personalized anonymity through query blocks exchanging[J]. China Communications, 2016, 13(11):106-118.
|
| [24] |
Gruteser M, Grunwald D. Anonymous usage of location-based services through spatial and temporal cloaking[C]// Proceedings of the 1st International Conference on Mo-bile Systems, Applications and Services, 2003:31-42.
|
| [25] |
陈磊, 刘文懋. 合规视角下的数据安全技术前沿与应用[J]. 数据与计算发展前沿, 2021, 3(3):19-31.
|
 ),LI Xiaohui*(
),LI Xiaohui*(