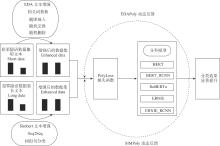
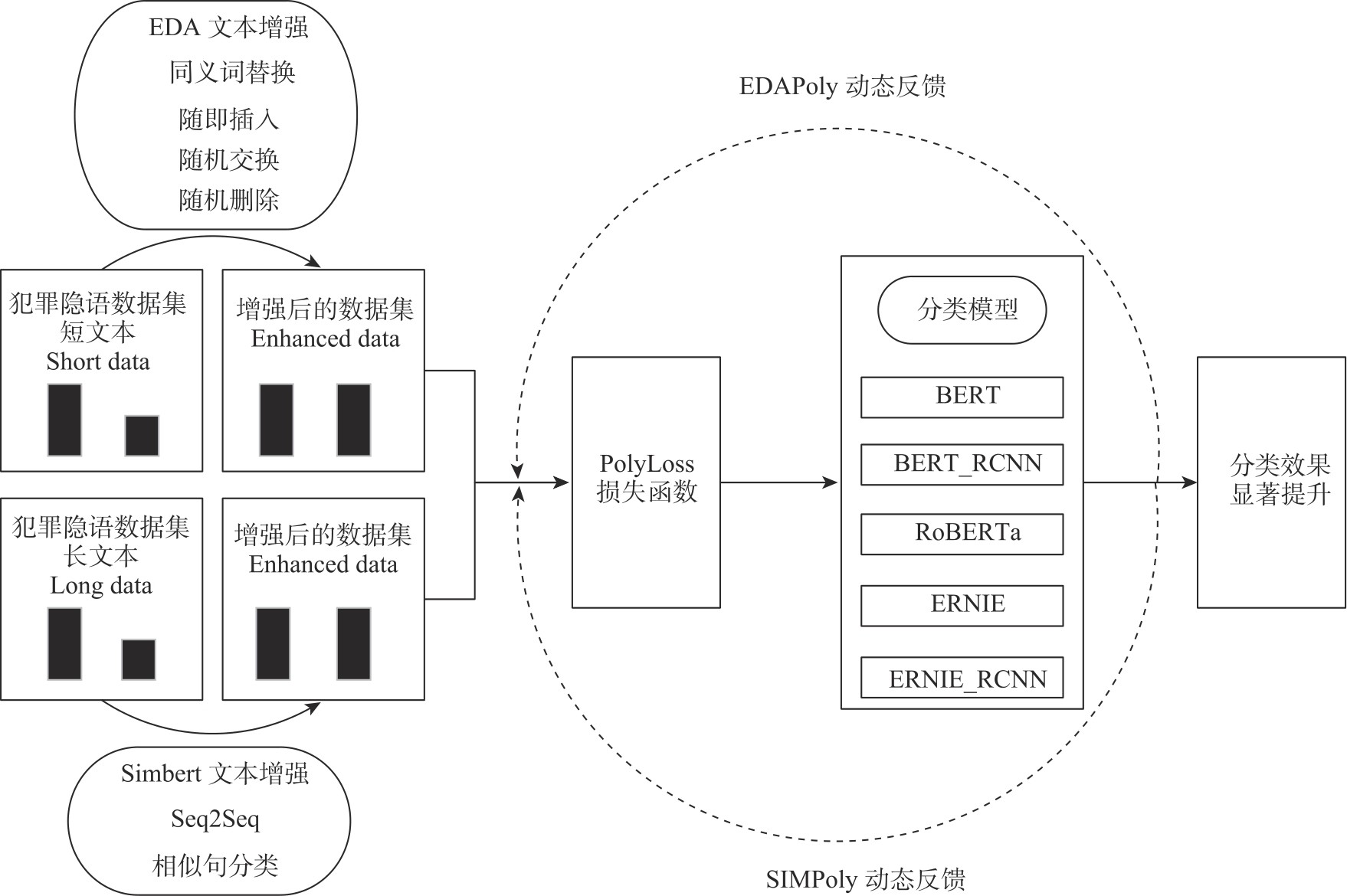
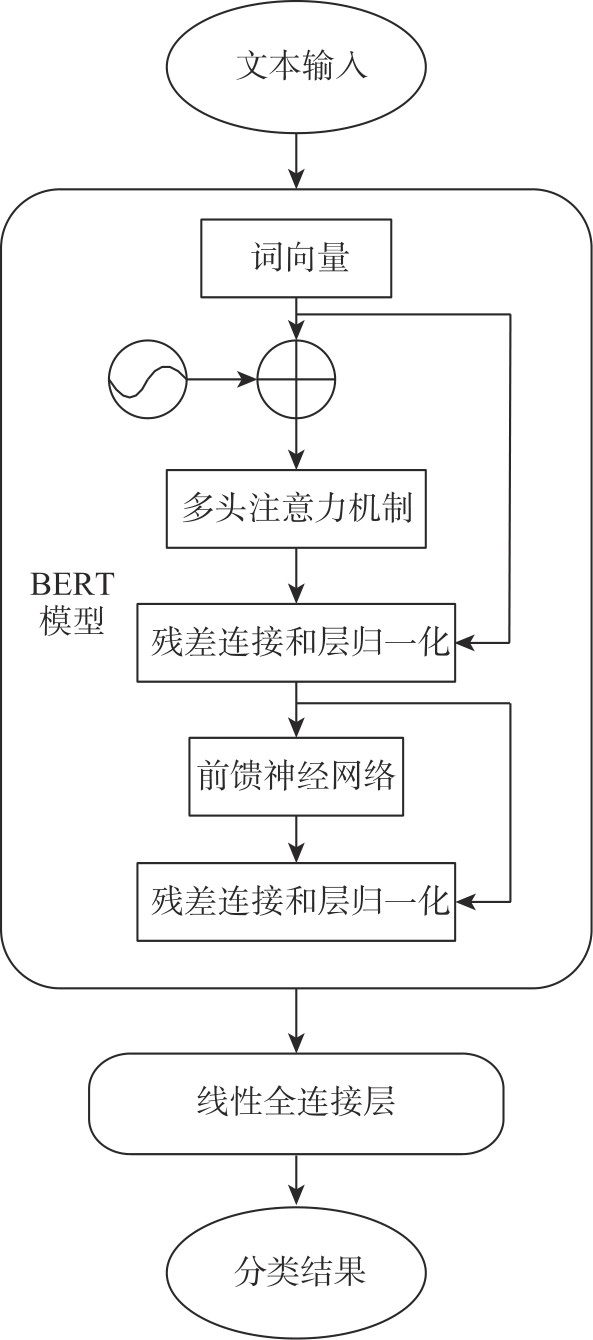
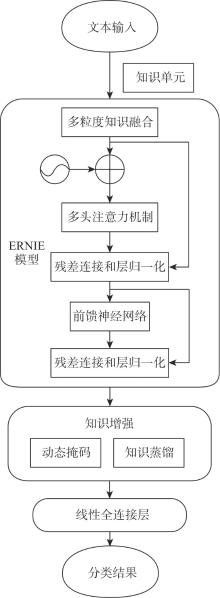
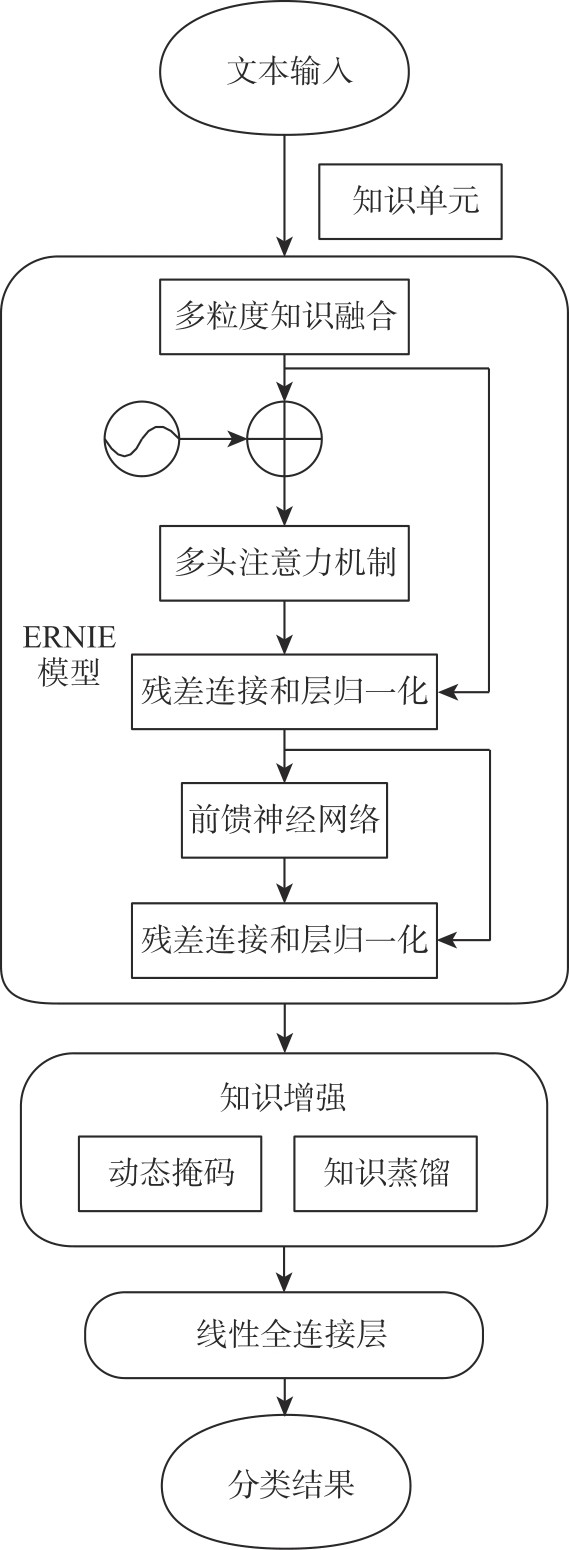
| [1] |
段晨杰. 公安情报分析工作面临的困境及应对措施[J]. 情报探索, 2018(12): 87-91.
|
| [2] |
黄攀. 犯罪隐语侦查情报应用的困境与对策[J]. 中国人民警察大学学报, 2023, 39(4): 5-11.
|
| [3] |
张宁. 网络犯罪隐语的演变趋势、侦查应用困境与纾解路径[J]. 江西警察学院学报, 2024(4): 57-63.
|
| [4] |
冯冉, 陈丹蕾, 化柏林. 文本数据的增强方法研究综述[J/OL]. 数据分析与知识发现, 1-17 [2024-12-02].http://kns.cnki.net/kcms/detail/10.1478.G2.20240911.1803.004.html.
|
| [5] |
林佳瑞, 程志刚, 韩宇, 等. 基于BERT预训练模型的灾害推文分类方法[J]. 图学学报, 2022, 43(3): 530-536.
|
| [6] |
姜钰棋, 侯智文, 王一帆, 等. 社交平台不平衡文本数据处理与应用研究[J]. 计算机科学与探索, 2024, 18(9): 2370-2383.
|
| [7] |
VUJIČIĆ S S, MLADENOVIĆ M. An approach to automatic classification of hate speech in sports domain on social media[J]. Journal of Big Data, 2023, 10(1): 109.
|
| [8] |
施国良, 陈宇奇. 文本增强与预训练语言模型在网络问政留言分类中的集成对比研究[J]. 图书情报工作, 2021, 65(13): 96-07.
|
| [9] |
许楠桸, 柯圆圆, 胡晓莉. 基于增强语言表示模型的网络新闻长文本分类的研究[J]. 江汉大学学报(自然科学版), 2024, 52(4): 37-44.
|
| [10] |
傅薛林, 金红, 郑玮浩, 等. 知识增强的BERT短文本分类算法[J]. 计算机工程与设计, 2024, 45(7):2027-2033.
|
| [11] |
FENG S Y, GANGAL V, KANG D, et al. GenAug: Data Augmentation for Finetuning Text Generators[C]// Proceedings of Deep Learning Inside Out (DeeLIO): The First Workshop on Knowledge Extraction and Integration for Deep Learning Architectures. 2020: 29-42.
|
| [12] |
KARIMI A, ROSSI L, PRATI A. AEDA: An Easier Data Augmentation Technique for Text Classification[C]// Findings of the Association for Computational Linguistics:EMNLP 2021 2021: 2748-2754.
|
| [13] |
YE J, XU N, WANG Y, et al. LLM-da: Data augmentation via large language models for few-shot named entity recognition[J]. arXiv preprint arXiv: 2402. 14568, 2024.
|
| [14] |
COULOMBE C. Text Data Augmentation Made Simple By Leveraging NLP Cloud APIs[J]. arXiv preprint arXiv: 2004. 14926, 2020.
|
| [15] |
淦亚婷, 安建业, 徐雪. 基于深度学习的短文本分类方法研究综述[J]. 计算机工程与应用, 2023, 59(4):43-53.
|
| [16] |
LENG Z, TAN M, LIU C, et al. PolyLoss: A Polynomial Expansion Perspective of Classification Loss Functions[C]// International Conference on Learning Representations.
|
| [17] |
MACDERMOTT Á, MOTYLINSKI M, IQBAL F, et al. Using deep learning to detect social media ‘trolls’[J]. Forensic Science International: Digital Investigation, 2022, 43: 301446.
|
| [18] |
RESENDE DE M R, FELIX DE B D, DE FRANCO R F, et al. A framework for detecting intentions of criminal acts in social media: A case study on twitter[J]. Information, 2020, 11(3): 154.
|
| [19] |
李贺, 杨心苗, 沈旺, 等. 启发式图结构增强的社交媒体短文本谣言检测研究[J]. 情报理论与实践, 2025, 48(3): 151-159.
|
| [20] |
施鑫, 蒋志伟. 网络时代构建犯罪隐语识别机制的困境和出路[J]. 长春市委党校学报, 2024(4): 36-40.
|
| [21] |
DEVLIN J, CHANG M W, LEE K, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[C]// Proceedings of NAACL-HLT. 2019.
|
| [22] |
LIU Y, OTT M, GOYAL N, ET AL. ROBERTA: A Robustly Optimized BERT Pretraining Approach[J]. ArXiv Preprint ArXiv:1907.11692, 2019.
|
| [23] |
ZHANG Z, HAN X, LIU Z, et al. ERNIE: Enhanced Language Representation with Informative Entities[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019: 1441-1451.
|
| [24] |
WEI J, ZOU K. EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP).
|
| [25] |
BAI J, XUE H, JIANG X, et al. Classification and recognition of milk somatic cell images based on PolyLoss and PCAM-Reset50[J]. Mathematical Biosciences and Engineering: MBE, 2023, 20(5): 9423-9442.
|
| [26] |
LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]// Proceedings of the IEEE International Conference on Computer Vision. 2017: 2980-2986.
|
| [27] |
PEKER O, UYSAL F, HARDALAç F. Boost loss functions for better change detection[C]// 2022 3rd International Informatics and Software Engineering Conference (IISEC). IEEE, 2022: 1-4.
|
 ),颜靖华*(
),颜靖华*(