Frontiers of Data and Computing ›› 2021, Vol. 3 ›› Issue (5): 65-81.
doi: 10.11871/jfdc.issn.2096-742X.2021.05.005
• Special Issue: Problems and Counter measures in the field of In fomation Tellnology in China • Previous Articles Next Articles
FAN Zhihua1,2( ),LI Wenming1(),YE Xiaochun1(),FAN Dongrui1,2,*()
),LI Wenming1(),YE Xiaochun1(),FAN Dongrui1,2,*()
Received:2021-09-30
Online:2021-10-20
Published:2021-11-24
Contact:
FAN Dongrui
E-mail:fanzhihua@ict.ac.cn;liwenming@ict.ac.cn;yexiaochun@ict.ac.cn;fandr@ict.ac.cn
FAN Zhihua,LI Wenming,YE Xiaochun,FAN Dongrui. The Research Progress of Dataflow Computing: A Brief Survey[J]. Frontiers of Data and Computing, 2021, 3(5): 65-81.
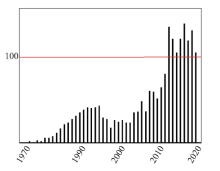
Fig.1
Number of papers related to dataflow computing"
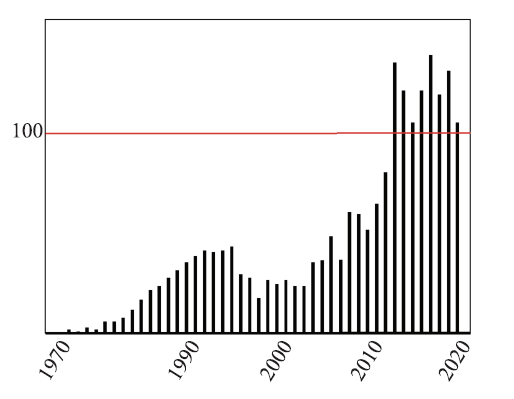
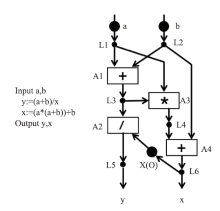
Fig.2
The first dataflow program"
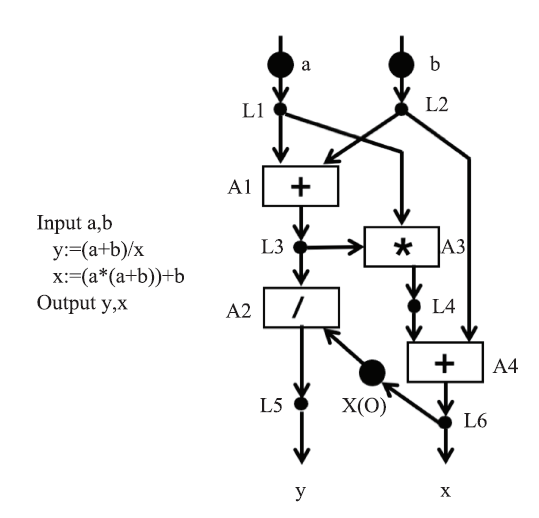
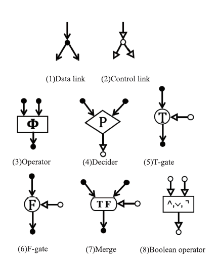
Fig.3
The first dataflow programming language"
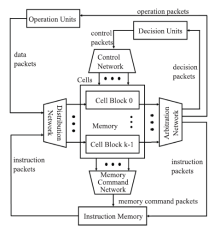
Fig.4
The first abstract model of dataflow computer"
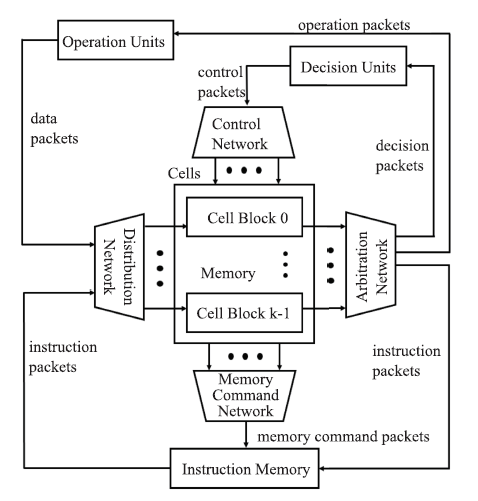
Table 1
Representative works of dataflow computing"
| 成果 | 年份 | 领域 |
|---|---|---|
| Argument-flow[ | 1973 | 数据流起源 |
| DSG [ | 1982 | 程序执行模型 |
| Argument-fetch [ | 1990 | 程序执行模型 |
| Gao等[ | 1993 | 动态数据流 |
| Super-actor[ | 1992 | 数/控结合 |
| EARTH- MANNA[ | 1994 | 计算机系统 |
| EARTH[ | 1995 | 程序执行模型 |
| EARTH-c[ | 1997 | 编译 |
| CARE[ | 2003 | 计算机系统 |
| WaveScalar[ | 2003 | 计算机系统 |
| TRIPS[ | 2004 | 数据流芯片 |
| Cyclops64[ | 2006 | 数据流芯片 |
| 渗透模型[ | 2009 | 程序执行模型 |
| NeuFlow[ | 2011 | 数据流芯片 |
| Godson-T[ | 2012 | 高性能处理器 |
| Codelet[ | 2013 | 程序执行模型 |
| COStream[ | 2013 | 编译器 |
| T3[ | 2013 | 计算机系统 |
| Caffe[ | 2014 | 软件框架 |
| Teraflux[ | 2014 | 计算机系统 |
| Fresh Breeze[ | 2014 | 编译 |
| Tensorflow[ | 2016 | 软件框架 |
| Eyeriss[ | 2016 | 数据流芯片 |
| HAMR[ | 2017 | 软件系统 |
| FlexFlow[ | 2017 | 数据流芯片 |
| Stream-dataflow[ | 2017 | 数据流芯片 |
| Tianjic[ | 2019 | 类脑芯片 |
| SPU[ | 2020 | 数据流芯片 |
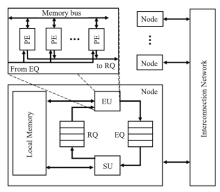
Fig.5
Abstract model of the EARTH"
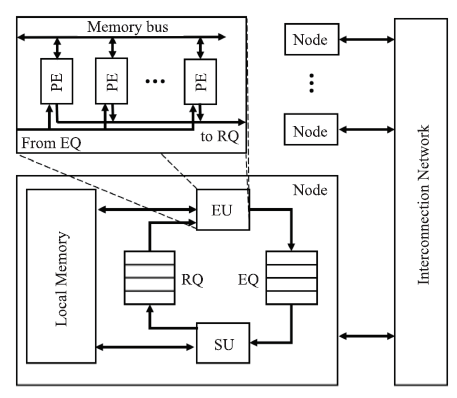
Fig.6
The architecture of CARE and its pipeline"
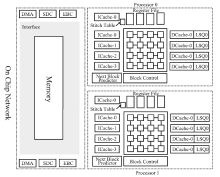
Fig.7
The architecture of TRIPS"
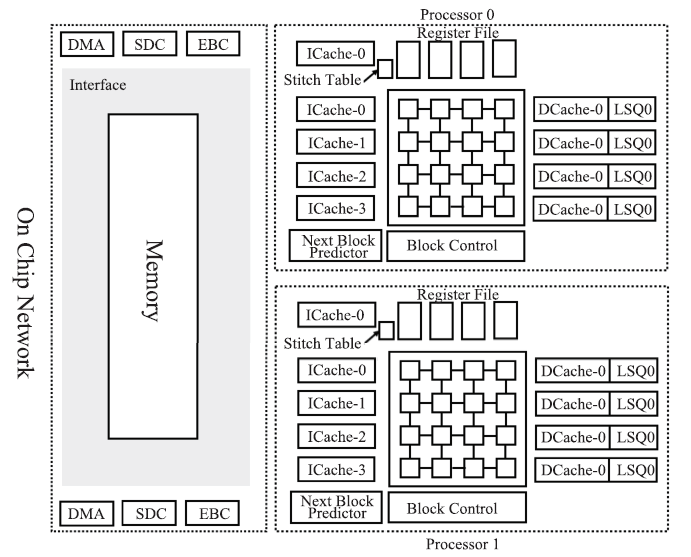
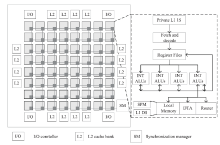
Fig.8
The architecture of Godson-T"
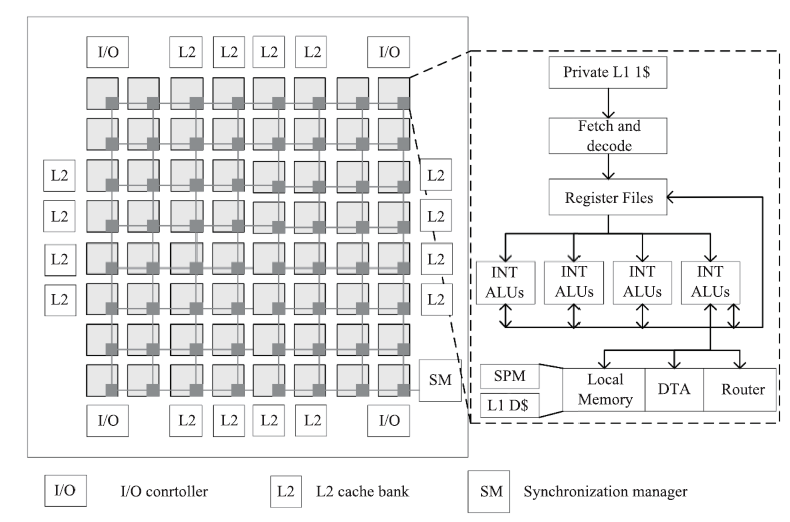
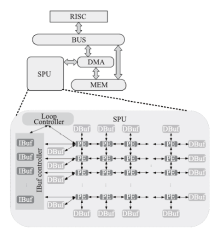
Fig.9
The architecture of SPU"
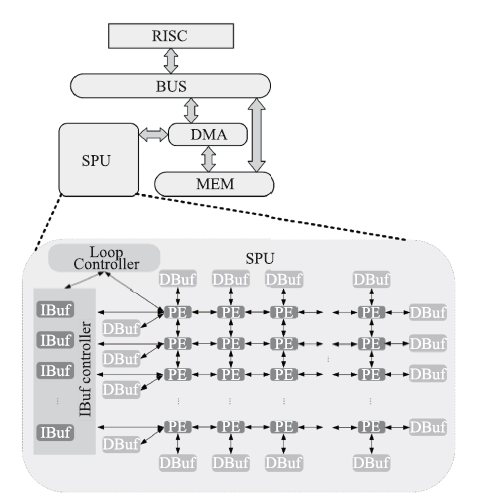
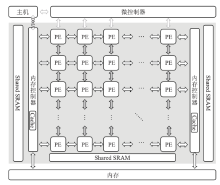
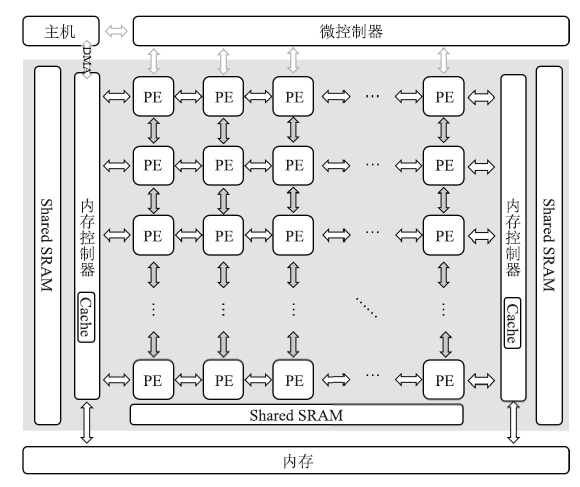
Fig.10
The architecture of DPU"
| [1] | Dennis J. B. First version of a data flow procedure lang-uage[C]. Paris: In Proceeding of the Colloque sur la Programmation, 1974. |
| [2] | 李国杰. 一种新的体系结构-数据流计算机[J]. 电子计算机动态, 1981, 11:1-8. |
| [3] | Adams D.A. A. A Computation Model with DataFlow Sequencing[Z]. Technical Report CS 117, Computer Science Department, School of Humanities and Sciences, Stanford University, Calif, 1968. |
| [4] | Dennis J. B. First version of a data flow procedure language[C]. Paris: In Proceeding of the Colloque sur la Programmation, 1974. |
| [5] | Dennis J B, David P M. A preliminary architecture for a basic data-flow processor[C]. Proceedings of the 2nd Annual Symposium on Computer Architecture, 1974. |
| [6] | Dennis J.B., J.B. Fosseen. Introduction to DataFlow Schemas[Z]. 1973. |
| [7] | Kosinski P.R. A DataFlow Programming Language[Z]. IBM, 1973. |
| [8] | Kosinski P.R. A DataFlow Language for opreating sys-tems programming[C]. Proceeding of ACM SIGP-LAN-SIGOPS Interface Meeting, 1973. |
| [9] | G. R. Gao. An implementation scheme for array oper-ations in static data flow computers[Z]. Technical report, Cambridge, 1982. |
| [10] | G. R. Gao. A pipelined code mapping scheme for static data flow computers[D]. Massachusetts Institute of Tech-nology, 1986. |
| [11] |
G. R. Gao. An efficient hybrid dataflow architecture model[J]. Journal of Parallel and Distributed Computing, 1993, 19(4):293-307.
doi: 10.1006/jpdc.1993.1113 |
| [12] | J. B. Dennis. General parallel computation can be perfor-med with a cycle-free heap[C]. In Proceedings. 1998 Inter national Conference on Parallel Architectures and Comp-ilation Techniques, 1998. |
| [13] | A. L. Davis and R. M. Keller. Data flow program graphs [C]. 1982. |
| [14] | D. E. Culler and Arvind. Resource requirements of data-flow programs[C]. Washington: In proceedings of the 15th Annual International Symposium on Computer Archi-tecture, IEEE Computer Society Press, 1988. |
| [15] | J. B. Dennis. Compiling fresh breeze codelets[C]. New York: In Proceedings of Programming Models and Appli-cations on Multicores and Manycores, 2014. |
| [16] | A. Danalis, K. Y. Kim, L. Pollock, M. Swany. Transformations to parallel codes for communication-computation overlap[C]. Seattle In Acm/ieee Conference on Supercomputing, 2005. |
| [17] | 张维维, 魏海涛, 于俊清, 李鹤, 黎昊, 杨秋吉. Costream: 一种面向数据流的编程语言和编译器实现[J]. 计算机学报, 2013, 36(10):1993-2006. |
| [18] | S. Zuckerman, J. Suetterlein, R. Knauerhase, G. R. Gao. Position paper: Using a ”codelet”program execution model for exascale machines[J]. New York :In ACM International Conference Proceeding Series, ACM Press, 2011. |
| [19] | G. R. Gao, H. H. Hum, Y.-B. Wong. Parallel function invocation in a dynamic argument-fetching dataflow architecture[C]. Miami Beach,Flor:In Proceedings. PAR-BASE-90: International Conference on Databases, Parallel Architectures, and Their Applications, IEEE, 1990. |
| [20] |
G. R. Gao. Maximum pipelining linear recurrence on static data flow computers[J]. International journal of parallel programming, 1986, 15(2):127-149.
doi: 10.1007/BF01414442 |
| [21] | G. R. Gao. A pipelined code mapping scheme for static data flow computers[D]. Massachusetts Institute of Technology, 1986. |
| [22] |
G. R. Gao. Algorithmic aspects of balancing techniques for pipelined data flow code generation[J]. Journal of Parallel and Distributed Computing, 1989, 6(1):39-61.
doi: 10.1016/0743-7315(89)90041-5 |
| [23] | G. R. Gao. A pipelined code mapping scheme for solving tridiagonal linear system equations[C]. Nice Frtance :In Proceeding of IFIP Highly Parallel Computer Conference, 1986. |
| [24] | G. R. Gao. A Code Mapping Scheme for Dataflow Soft-ware Pipelining[C]. Springer Science & Business Media, 2012. |
| [25] |
G. R. Gao. An efficient hybrid dataflow architecture model[J]. Journal of Parallel and Distributed Computing, 1993, 19(4):293-307.
doi: 10.1006/jpdc.1993.1113 |
| [26] | Xiaochun Ye, Xu Tan, Meng Wu, Yujing Feng, Da Wang, Hao Zhang, Songwen Pei, Dongrui Fan, An efficient dataflow accelerator for scientific applications[J]. Future Generation Computer Systems, 2020, Volume 112, 580-588. |
| [27] | Taoran Xiang and Lunkai Zhang, et al. RISC-NN: Use RISC, NOT CISC as Neural Network Hardware Infrastruc-ture[J]. arXiv preprint, arXiv:2103.12393.2021. [2021-09-27]https://arxiv.org/abs/2103.12393v1 |
| [28] |
Baumgarte V, Ehlers G, May F, et al. PACT XPP—A Self-Reconfigurable Data Processing Architecture[J]. Journal of Supercomputing, 2003, 26(2):167-184.
doi: 10.1023/A:1024499601571 |
| [29] | Swanson S, Schwerin A, Mercaldi M, et al. The WaveScalar architecture[J]. ACM Transactions on Computer Systems, 2007, 25(2):4. |
| [30] | Mattson P, Dally W J. A programming system for the imagine media processor[D]. Stanford: Stanford Univer-sity, 2002. |
| [31] |
Khailany B, Dally W J, Kapasi U J, et al. Imagine: media processing with streams[J]. IEEE Micro, 2001, 21:35-46.
doi: 10.1109/40.918001 |
| [32] | C.A.R. Hoare. Hoare Communicating Sequential Processes[M]. Prentice Hall International, 1985. |
| [33] | Norman P. Jouppi, Cliff Young, Nishant Patil, David Patterson, et al. Google, Inc., Mountain View, CA USA 2017. In-Datacenter Performance Analysis of a Tensor Processing Unit[C]. Toronto :In Proceedings of ISCA, 2017. |
| [34] |
H. T. Kung, Why systolic architectures?[C]. IEEE Computer, 1982,Vol. 15:37-46.
doi: 10.1109/MC.1982.1653825 |
| [35] | H. H.-J. Hum. The Super-actor Machine: A Hybrid Data-flow/Von Neum[D]. Montreal, Que., Canada, 1992. |
| [36] | H. H. J. Hum, K. B. Theobald, and G. R. Gao, Buil-ding multithreaded architectures with off-the-shelf microprocessors[D]. In Proceedings of 8th International Parallel Processing Symposium, IEEE, 1994, pages 288-294. |
| [37] | G. R. Gao. An implementation scheme for array oper-ations in static data flow computers[D]. Technical report, Cambridge, MA, USA, 1982. |
| [38] | H. H. Hum, O. Maquelin, K. B. Theobald, X. Tian, X. Tang, G. R. Gao, P. Cupryk, N. Elmasri, L. J. Hend-ren. A. Jimenez, et al. A design study of the earth multiprocessor[C]. Citeseer: In PACT, 1995. |
| [39] | K. B. Theobald and G. R. Gao. Earth: an efficient arch-itecture for running threads[D]. McGill University Mon-treal, Canada, 1999. |
| [40] |
H. H. Hum and G. R. Gao. A high-speed memory organ-ization for hybrid dataflow/von neumann computing[J]. Future Generation Computer Systems, 1992, 8(4):287-301.
doi: 10.1016/0167-739X(92)90064-I |
| [41] | G. R. Gao and V. Sarkar. Sarkar. Location consistency: Stepping beyond the barriers of memory coherence and serializa-bility [Z]. In McGill University, School of Computer. Citeseer, 1994. |
| [42] | G. R. Gao and V. Sarkar. On the importance of an end-to-end view of memory consistency in future computer systems[C]. Fukuoka,Japan:In International Symposium on High Performance Computing, 1997. |
| [43] |
G. R. Gao and V. Sarkar. Location consistency-a new memory model and cache consistency protocol[J]. IEEE Transactions on Computers, 2000, 49(8):798-813.
doi: 10.1109/12.868026 |
| [44] |
G. Tan, N. Sun, G. R. Gao. Improving performance of dynamic programming via parallelism and locality on multicore architectures[J]. IEEE Trans. Parallel Distrib. Syst. 2009, 20(2):261-274.
doi: 10.1109/TPDS.2008.78 |
| [45] | 谭光明. 非规则计算中的并行性和局部性[D]. 中国科学院大学, 2005. |
| [46] |
L. J. Hendren, X. Tang, Y. Zhu, S. Ghobrial, G. R. Gao, X. Xue, H. Cai, P. Ouellet. Compiling c for the earth multithreaded architecture[J]. International Journal of Parallel Programming, 1997, 25(4):305-338.
doi: 10.1007/BF02699905 |
| [47] | J. B. Dennis. A parallel program execution model suppor-ting modular software construction[C]. In Mass-ively Parallel Programming Models, IEEE, 1997. |
| [48] | J. B. Dennis. Compiling fresh breeze codelets[C]. New York, NY:In International Symposium on Code Generation and Optimization, ACM, 2014. |
| [49] | J. B. Dennis, G. R. Gao, X. X. Meng. Experiments with the fresh breeze tree-based memory model[J]. Com-puter Science-Research and Development, 2011, 26(3-4):325-337. |
| [50] | J. B. Dennis, L. Huang, W. Y. P. Lim, H. Wu, and Y. Yan. Lim, H. Wu, and Y. Yan. Implementing deep neural networks on fresh breeze[C]. Italy:International Conference on Parallel Computing, 2017. |
| [51] | H. Wei, M. Qin, W. Zhang, J. Yu, D. Fan, G. R. Gao. Streamtmc: Stream compilation for tiled multi-core architectures[J]. Journal of Parallel & Distributed Computing, 2013, 73(4):484-494. |
| [52] | 魏海涛, 秦明康, 于俊清, 范东睿. 一种面向众核架构的数据流编译框架[J]. 计算机学报, 2014, 37(07):128-137. |
| [53] |
Y. Wu, L. Zheng, B. Heilig, G. R. Gao. HAMR: A dataflow-based real-time in-memory cluster computing engine[J]. International Journal of High Performance Computing Applications, 2017, 31(5):361-374.
doi: 10.1177/1094342016672080 |
| [54] | Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S. Guadarrama, T. Darrell. Caffe: Convolutional architecture for fast feature embedding[C]. New York :In Proceedings of the 22nd ACM International Conference on Multimedia, Association for Computing Machinery, 2014. |
| [55] | M. Abadi, P. Barham, J. Chen, Z. Chen, A. Davis, J. Dean, M. Devin, S. Ghemawat, G. Irving, M. Isard, M. Kudlur, J. Levenberg, R. Monga, S. Moore, D. G. Murray, B. Steiner, P. Tucker, V. Vasudevan, P. Warden, M. Wicke, Y. Yu, X. Zheng. TensorFlow: A System for Large-Scale Machine Learning[C]. USA: In Proceedings of the 12th USENIX Conference on Operating Systems Design and Implementation.USENIX Association, 2016. |
| [56] | U. Brüning, W. K. Giloi, W. Schroeder-Preikschat. Latency hiding in message-passing architectures[C]. Mexico :In Proceedings of 8th International Parallel Processing Symposium, IEEE, 1994. |
| [57] |
H. H. Hum, O. Maquelin, K. B. Theobald, X. Tian, G. R. Gao, L. J. Hendren. A study of the earth-manna multithreaded system[J]. International Journal of Parallel Programming, 1996, 24(4):319-348.
doi: 10.1007/BF03356753 |
| [58] | C. Intel Corp. I860 Microprocessor Family Programmer’s Reference Manual[Z]. Intel Corporation, Santa Clara, CA, USA, 1992. |
| [59] | Andres Marquez and Guang R. Gao. CARE: Overview of an Adaptive Multithreaded Architecture[C]. Tokyo, Japan :In Proceedings of Fifth International Symposium on High Performance Computing, 2003. |
| [60] | M. S. S. Govindan D. Burger, and Burger S S. Keckler. Trips: A distributed explicit data graph execution (edge) micropro-cessor[C]. In 2007 IEEE Hot Chips 19 Symposium 2007. |
| [61] | S. Swanson, A. Schwerin, M. Mercaldi, A. Petersen, A. Putnam, K. Michelson, M. Oskin, S. J. Eggers, The wave scalar architecture[C]. ACM Trans. Comput. Syst 2007, 25(2):4:1-4:54. |
| [62] | Ziang Hu Juan del Cuvillo Weirong Zhu, and Guang R. Optimization of Dense Matrix Multiplication on IBM Cyclops-64: Challenges and Experiences[C]. Dresden: In Proceedings of the 12th International European Conference on Parallel Processing (Euro-Par 2006) 2006. |
| [63] | Y. Ji, Y. Zhang, X. Xie, S. Li, P. Wang, X. Hu, Y. Zhang, Y. Xie. Fpsa: A full system stack solution for reconfigurable reram-based nn accelerator architecture[C]. In Proceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems, ACM, 2019. |
| [64] |
Zhang Y., Qu P., Ji Y. et al. A system hierarchy for brain inspired computing[J]. Nature, 2020, 586(7829):378-384.
doi: 10.1038/s41586-020-2782-y |
| [65] | Jian Weng, Sihao Liu, Zhengrong Wang, Vidushi Dadu, Tony Nowatzki. A Hybrid Systolic-Dataflow Architecture for Inductive Matrix Algorithms[C]. HPCA 2020. |
| [66] | Dongrui Fan, Hao Zhang, Da Wang, Xiaochun Ye, Fenglong Song, Guojie Li, Ninghui Sun. Godson-T: An Efficient Many-Core Processor Exploring Thread-Level Parallelism[J]. IEEE Micro., 2012, 32:38-47. |
| [67] | Xiang Taotan, Feng Yujing, Ye Xiaochun, et al. Accelerating CNN algorithm with fine-grained dataflow architectures[C]. Piscataway : Proc of 2018 IEEE Conf on High Performance Computing and Communications, 2018. |
| [68] | 申小伟, 叶笑春, 王达, 等. 一种面向科学计算的数据流优化方法[J]. 计算机学报, 2017, 40(9):223-238. |
| [69] | 向陶然, 叶笑春, 李文明, 等. 基于细粒度数据流架构的稀疏神经网络全连接层加速[J]. 计算机研究与发展, 2019, 56(6):1192-1204. |
| [70] | X. Tan, X.-W. Shen, X.-C. Ye, D.-R. Fan, L. Zhang, W.-M. Li, Z.-M. Zhang, Z.-M. Tang. A non-stop double buffering mechanism for dataflow architecture[J]. J.Comput. Sci. Tech., 2018, 33(1):145-157. |
| [71] | X. Tan, X.-C. Ye, X.-W. Shen, Y.-C. Xu, D. Wang, L. Zhang, W.-M. Li, D. R. Fan, Z.-M. Tang. A pipelining loop optimization method for dataflow architecture[J]. J.Comput.Sci.Tech., 2018, 33(1):116-130. |
| [72] | X. Shen, X. Ye, X. Tan, D. Wang, Z. Zhang, D. Fan, Z. Tang. Poster: An optimization of dataflow architectures for scientific applications[C]. in: 2016 International Conference on Parallel Architecture and Compilation Techniques (PACT),2016. |
| [73] | X. Shen, X. Ye, X. Tan, D. Wang, Z. Zhang, Z. Tang, D. Fan. Memory partition for simd in streaming dataflow architectures[C]. in: 2016 Seventh International Green and Sustainable Computing Conference (IGSC), 2016. |
| [74] | Farabet, Clément, et al. Neuflow: A runtime reconfigurable dataflow processor for vision[C]. CVPR 2011 Workshops. IEEE, 2011. |
| [75] | Robatmili, Behnam, et al. How to implement effective prediction and forwarding for fusable dynamic multicore architectures[C]. 2013 IEEE 19th International Sympo-sium on High Performance Computer Architecture (HPCA). IEEE, 2013. |
| [76] |
Giorgi, Roberto, et al. TERAFLUX: Harnessing dataflow in next generation teradevices[J]. Microprocessors and Microsystems, 2014, 38(8):976-990.
doi: 10.1016/j.micpro.2014.04.001 |
| [77] | Chen, Yu-Hsin, Joel Emer, and Vivienne Sze. Eyeriss: A spatial architecture for energy-efficient dataflow for convolutional neural networks[J]. ACM SIGARCH Com-puter Architecture News, 2016, 44(3):367-379. |
| [78] | Lu, Wenyan, et al. Flexflow: A flexible dataflow accelerator architecture for convolutional neural networks[C]. IE-EE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 2017. |
| No related articles found! |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||