Frontiers of Data and Computing ›› 2026, Vol. 8 ›› Issue (3): 203-216.
doi: 10.11871/jfdc.issn.2096-742X.2026.03.017
• Technology and Application • Previous Articles Next Articles
ZHANG Chao1,2( ),LI Yanghao1,2,LI Kai1,WANG Zijian1,WANG Yangang1,2,CAO Rongqiang1,2,*()
),LI Yanghao1,2,LI Kai1,WANG Zijian1,WANG Yangang1,2,CAO Rongqiang1,2,*()
Received:2025-08-20
Online:2026-06-20
Published:2026-06-18
Contact:
CAO Rongqiang
E-mail:czhang@cnic.cn;caorq@sccas.cn
ZHANG Chao,LI Yanghao,LI Kai,WANG Zijian,WANG Yangang,CAO Rongqiang. A survey of Checkpointing Techniques for Large-Scale Language Models[J]. Frontiers of Data and Computing, 2026, 8(3): 203-216.
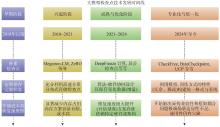
Fig.1
Timeline diagram of the development of checkpoint technology in large-scale language models"
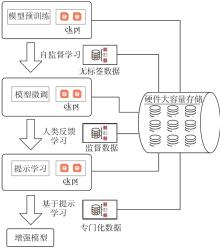
Fig.2
General flow chart of Large-Scale Language Models training"
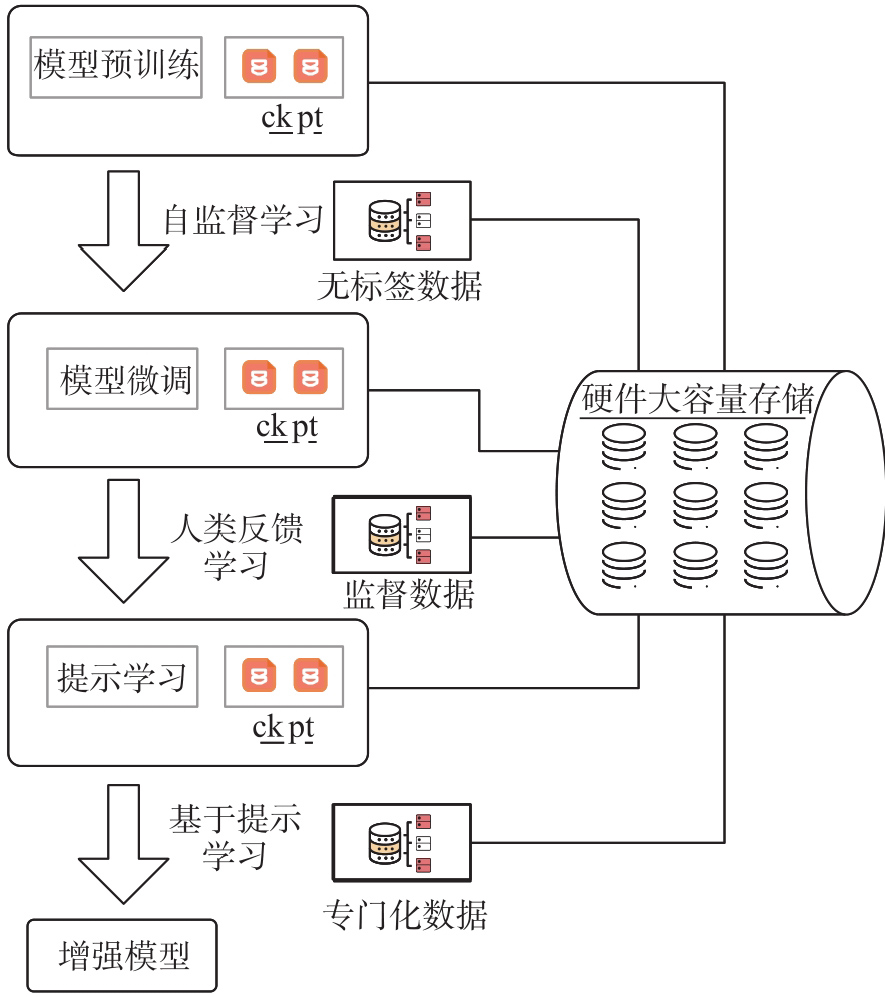
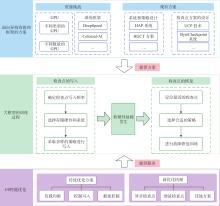
Fig.3
Overview of the Large-Scale Language Models checkpoint management and optimization strategy framework"
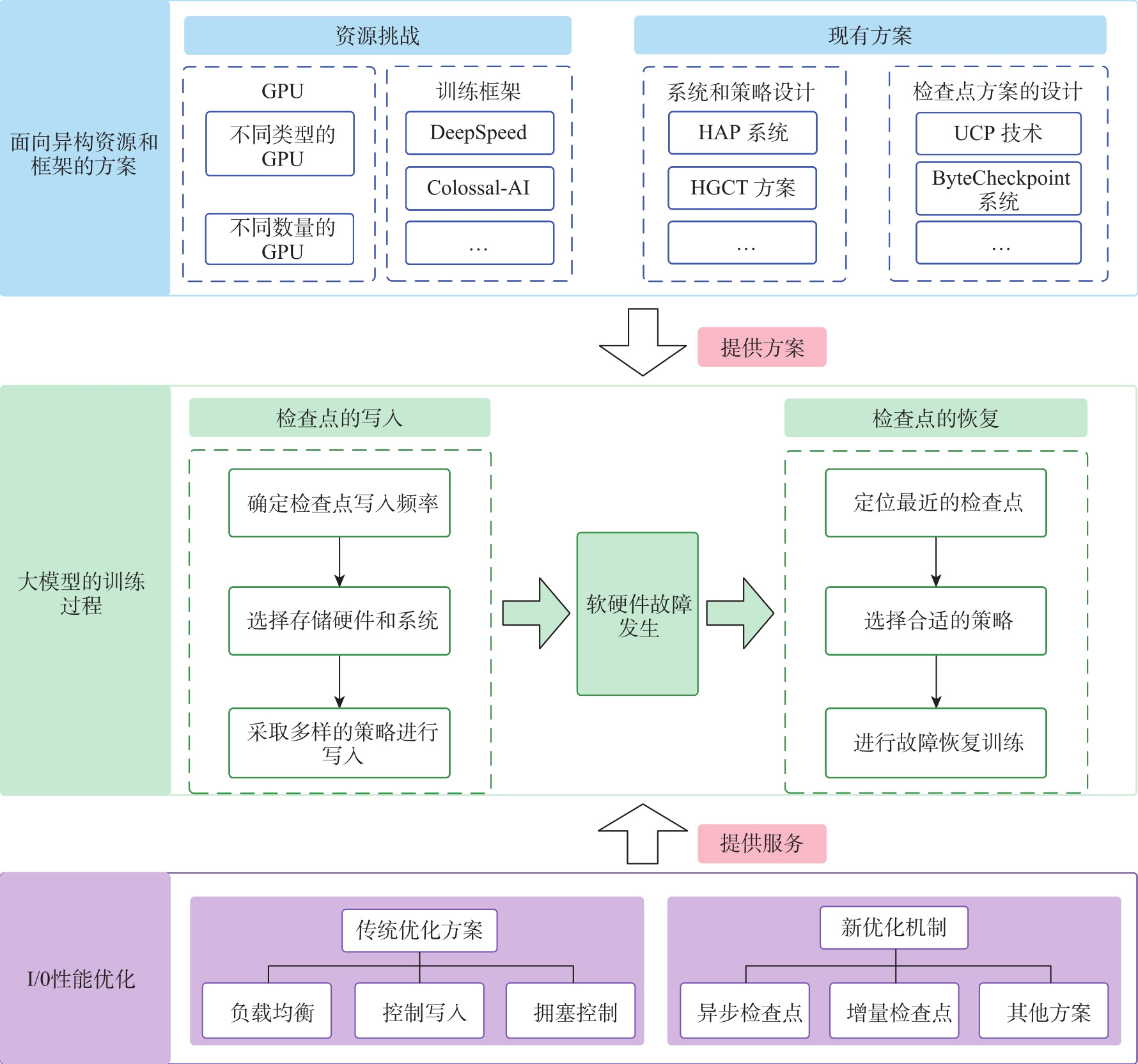
Fig.4
Checkpoint write process diagram"
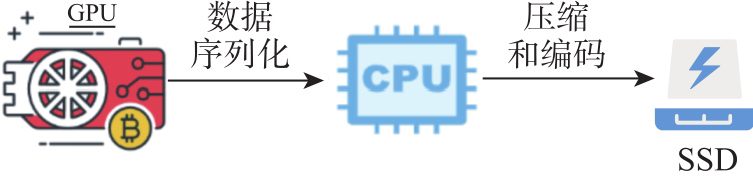
Table 1
Root-cause categorization of unexpected interruptions during a 54-day period of Llama 3 405b pre-training[41]"
| 组件 | 类别 | 中断次数 | 中断占比 |
|---|---|---|---|
| Faulty GPU | GPU | 148 | 30.1% |
| GPU HBM3 Memory | GPU | 72 | 17.2% |
| Software Bug | Dependency | 54 | 12.6% |
| Network Switch/Cable | Network | 32 | 7.3% |
| Host Maintenance | Unplanned Maintenance | 32 | 7.0% |
| GPU SRAM Memory | GPU | 19 | 4.6% |
| GPU System Processor | GPU | 17 | 4.0% |
| NIC | Host | 7 | 1.7% |
| NCCL Watchdog Timeouts | Unknown | 7 | 1.7% |
| Silent Data Corruption | GPU | 7 | 1.4% |
| GPU Thermal Interface+Sensor | GPU | 6 | 1.3% |
| SSD | Host | 3 | 0.7% |
| Power Supply | Host | 3 | 0.7% |
| Server Chassis | Host | 3 | 0.7% |
| IO Expansion Board | Host | 2 | 0.5% |
| Dependency | Dependency | 2 | 0.5% |
| CPU | Host | 2 | 0.5% |
| System Memory | Host | 2 | 0.5% |
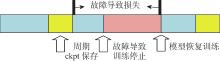
Fig.5
Recovery process after interruption in Large-Scale Language Models training"
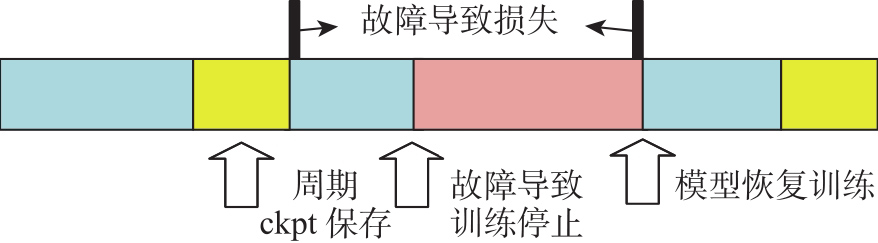
Table 2
Multi-Dimensional Comparison of Core Checkpointing Technologies for Large-Scale Language Models?"
| 技术类别 | 核心技术方案 | 存储效率 | 恢复速度 | 适用场景 | 优点 | 缺点 | 对应文献 |
|---|---|---|---|---|---|---|---|
| 检查点写入 | 智能压缩策略 | 高 | 中 | 存储受限场景、大规模模型训练 | 压缩率高,恢复速度提升;近乎无损恢复 | 有损压缩可能丢失梯度信息;高计算复杂度需额外GPU算力 | [ |
| 动态频率管理 | 中 | 中 | 各类模型训练、高频保存需求场景 | 基于训练状态自适应调整频次;CPU内存实现低延迟高频保存 | 数学模型假设与实际环境存在偏差;CPU内存容量限制 | [ | |
| 硬件-算法协同写入 | 中 | 较高 | 稀疏神经网络、计算密集型训练 | 序列长度或网络规模数倍扩展;利用内存加速创建 | 依赖专用硬件;大规模节点内存协调复杂 | [ | |
| 中间检查点合并 | 中 | 中 | 预训练阶段,混合专家模型预训练、参数高效微调 | 近乎零额外成本,提升模型推理泛化能力 | 依赖验证集选择,早期训练阶段效果有限,跨任务泛化能力弱 | [ | |
| 检查点恢复与容错 | 自动化故障感知恢复 | 高 | 较高 | 大规模分布式训练、国产化硬件环境 | 自动检测大部分故障;千亿级模型快速恢复 | 超高频故障稳定性不足;非 NVIDIA硬件支持有限 | [ |
| 极速无阻塞恢复 | 高 | 极高 | 弱计算节点环境、数据并行架构 | 无备份恢复;零训练阻塞 | 依赖模型层间冗余;仅支持非加密通信 | [ | |
| 结构化恢复框架 | 高 | 中 | Sparse MoE 模型、分布式训练 | 降低存储开销;分层快照保障一致性 | 通用模型兼容性差;分层管理复杂度高 | [ | |
| I/O性能优化 | 传统I/O调度优化 | 中 | 中 | OpenMP应用、Lustre文件系统环境 | 减少线程负载不均衡;稳定吞吐量 | 适配性有限;需人工调试延迟参数 | [ |
| 异步加载与切分 | 高 | 高 | 异构框架、超大模型训练 | 存储性能提升;零冗余加载 | 弱网络环境延迟增加;依赖P2P通信 | [ | |
| 计算-I/O重叠技术 | 较高 | 较高 | 动态计算图框架(如PyTorch) | 嵌入张量副本实现并行,降低GPU空闲时间 | 不支持静态计算图框架(如TensorFlow) | [ | |
| 异构兼容 | 通用格式与切分方案 | 中 | 中 | 多并行策略、跨框架迁移 | 支持多种并行策略;元数据与张量分离实现解耦 | 依赖手动脚本转换;新型硬件兼容性待验证 | [ |
| 混合集群训练实践 | 中 | 中 | 多厂商GPU集群、70B以下模型 | 首次实现异构混合训练开源,精度损失<1% | 千亿级模型稳定性不足;仅支持 PyTorch | [ | |
| 通信与张量优化 | 中 | 中 | 异构GPU集群、复杂并行场景 | 优化分片策略与通信方式;降低跨设备延迟 | 对3D并行+MoE适配有限;大规模部署成本高 | [ |
| [1] | MIHALCEA R, LIU H, LIEBERMAN H. NLP (Natural Language Processing) for NLP (Natural Language Programming)[C]. Proceedings of the 7th International Conference on Computational Linguistics and Intelligent Text Processing (CICLing 2006), Berlin Heidelberg: Springer, 2006: 319-330. |
| [2] | VOULODIMOS A, DOULAMIS N, DOULAMIS A, et al. Deep Learning for Computer Vision: A Brief Review[J]. Computational Intelligence and Neuroscience, 2018, 2018(1): 7068349. |
| [3] |
BURKE R, FELFERNIG A, GÖKER M H. Recommender Systems: An Overview[J]. AI Magazine, 2011, 32(3): 13-18.
doi: 10.1609/aimag.v32i3.2361 |
| [4] | SHAW P, USZKOREIT J, VASWANI A. Self-Attention with Relative Position Representations[J]. arXiv Preprint arXiv:1803.02155, 2018. |
| [5] |
ROUMELIOTIS K I, TSELIKAS N D. ChatGPT and Open-AI Models: A Preliminary Review[J]. Future Internet, 2023, 15(6): 192.
doi: 10.3390/fi15060192 |
| [6] | ACHIAM J, ADLER S, AGARWAL S, et al. GPT-4 Technical Report[J]. arXiv Preprint arXiv:2303.08774, 2023. |
| [7] | ROUMELIOTIS K I, TSELIKAS N D, NASIOPOULOS D K. Llama 2: Early Adopters' Utilization of Meta’s New Open-Source Pretrained Model[J]. arXiv Preprint, 2023. |
| [8] | CHOWDHERY A, NARANG S, DEVLIN J, et al. PaLM: Scaling Language Modeling with Pathways[J]. Journal of Machine Learning Research, 2023, 24(240): 1-113. |
| [9] | SUN Y, WANG S, FENG S, et al. ERNIE 3.0: Large-Scale Knowledge Enhanced Pre-Training for Language Understanding and Generation[J]. arXiv Preprint arXiv:2107.02137, 2021. |
| [10] | ZENG W, REN X, SU T, et al. PanGu-α: Large-Scale Autoregressive Pretrained Chinese Language Models with Auto-Parallel Computation[J]. arXiv Preprint arXiv:2104.12369, 2021. |
| [11] | LIU J, ZHU X, LIU F, et al. OPT: Omni-Perception Pre-Trainer for Cross-Modal Understanding and Generation[J]. arXiv Preprint arXiv:2107.00249, 2021. |
| [12] | LIAO H, TU J, XIA J, et al. Ascend: A Scalable and Unified Architecture for Ubiquitous Deep Neural Network Computing: Industry Track Paper[C]. Proceedings of 2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA), New York: IEEE, 2021: 789-801. |
| [13] | LI S, LIU H, BIAN Z, et al. Colossal-AI: A Unified Deep Learning System for Large-Scale Parallel Training[C]. Proceedings of the 52nd International Conference on Parallel Processing, 2023: 766-775. |
| [14] | RAJBHANDARI S, RASLEY J, RUWASE O, et al. ZeRO: Memory Optimizations toward Training Trillion Parameter Models[C]. Proceedings of SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, New York: IEEE, 2020: 1-16. |
| [15] | LIU Y, NASSAR R, LEANGSUKSUN C, et al. An Optimal Checkpoint/Restart Model for a Large Scale High Performance Computing System[C]. Proceedings of 2008 IEEE International Symposium on Parallel and Distributed Processing, New York: IEEE, 2008: 1-9. |
| [16] | ROJAS E, KAHIRA A N, MENESES E, et al. A Study of Checkpointing in Large Scale Training of Deep Neural Networks[J]. arXiv Preprint arXiv:2012.00825, 2020. |
| [17] | CHANG Y S, CHO S Y, KIM B Y. Performance Evaluation of the Striped Checkpointing Algorithm on the Distributed RAID for Cluster Computer[C]. Proceedings of the 3rd International Conference on Computational Science (ICCS 2003), Berlin Heidelberg: Springer, 2003: 955-962. |
| [18] | RODAMILANS C B, BORIN E. Análise de Desempenho dos Serviços de Armazenamento da Nuvem Computacional para Execução de Checkpoint[C]. Proceedings of Escola Regional de Alto Desempenho de São Paulo (ERAD-SP), Porto Alegre: SBC, 2020: 86-89. |
| [19] | XU Q, SIYAMWALA H, GHOSH M, et al. Performance Analysis of NVMe SSDs and Their Implication on Real World Databases[C]. Proceedings of the 8th ACM International Systems and Storage Conference, New York: ACM, 2015: 1-11. |
| [20] | BORTHAKUR D. HDFS Architecture Guide[J]. Hadoop Apache Project, 2008, 53(1-13): 2. |
| [21] | WEIL S, BRANDT S A, MILLER E L, et al. Ceph:A Scalable, High-Performance Distributed File System[C]. Proceedings of the 7th Conference on Operating Systems Design and Implementation (OSDI'06), Berkeley: USENIX Association, 2006: 307-320. |
| [22] | WANG Z, JIA Z, ZHENG S, et al. Gemini: Fast Failure Recovery in Distributed Training with In-Memory Checkpoints[C]. Proceedings of the 29th Symposium on Operating Systems Principles, New York: ACM, 2023: 364-381. |
| [23] | SADI S, YAGOUBI B. On the Optimum Checkpointing Interval Selection for Variable Size Checkpoint Dumps[C]. Proceedings of the 5th IFIP TC 5 International Conference on Computer Science and Its Applications (CIIA 2015), Cham: Springer International Publishing, 2015: 599-610. |
| [24] | MOHAN J, PHANISHAYEE A, CHIDAMBARAM V. CheckFreq:Frequent, Fine-Grained DNN Checkpointing[C]. Proceedings of the 19th USENIX Conference on File and Storage Technologies (FAST 21), Berkeley: USENIX Association, 2021: 203-216. |
| [25] | WANG G, RUWASE O, XIE B, et al. FastPersist: Accelerating Model Checkpointing in Deep Learning[J]. arXiv Preprint arXiv:2406.13768, 2024. |
| [26] | HIRAGA S K K, TATEBE O. Fast Checkpointing of Large Language Models with TensorStore CHFS[J]. IEEE Transactions on Parallel and Distributed Systems, 2024. |
| [27] | COLLET Y, KUCHERAWY M. Zstandard Compression and the Application/zstd Media Type[R]. Fremont: Internet Engineering Task Force, 2018. |
| [28] | ISLAM T Z, MOHROR K, BAGCHI S, et al. MCREngine: A Scalable Checkpointing System Using Data-Aware Aggregation and Compression[C]. Proceedings of SC'12: International Conference on High Performance Computing, Networking, Storage and Analysis, New York: IEEE, 2012: 1-11. |
| [29] | CHEN Y, LIU Z, REN B, et al. On Efficient Constructions of Checkpoints[J]. arXiv Preprint arXiv:2009. 13003, 2020. |
| [30] | LI W, CHEN X, SHU H, et al. ExCP: Extreme LLM Checkpoint Compression via Weight-Momentum Joint Shrinking[J]. arXiv Preprint arXiv:2406.11257, 2024. |
| [31] | MOODY A, BRONEVETSKY G, MOHROR K, et al. Design, Modeling, and Evaluation of a Scalable Multi-Level Checkpointing System[C]. Proceedings of SC’10: 2010 ACM/IEEE International Conference for High Performance Computing, Networking, Storage and Analysis, New York: IEEE, 2010: 1-11. |
| [32] | AGARWAL S, GARG R, GUPTA M S, et al. Adaptive Incremental Checkpointing for Massively Parallel Systems[C]. Proceedings of the 18th Annual International Conference on Supercomputing, New York: ACM, 2004: 277-286. |
| [33] | LI L, FAN Y, TSE M, et al. A Review of Applications in Federated Learning[J]. Computers & Industrial Engineering, 2020, 149: 106854. |
| [34] | EISENMAN A, MATAM K K, INGRAM S, et al. Check-N-Run: A Checkpointing System for Training Deep Learning Recommendation Models[C]. Proceedings of the 19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22), Berkeley: USENIX Association, 2022: 929-943. |
| [35] | BENCHEIKH W, FINKBEINER J, NEFTCI E. Optimal Gradient Checkpointing for Sparse and Recurrent Architectures Using Off-Chip Memory[J]. arXiv Preprint arXiv:2412.11810, 2024. |
| [36] | LIU D, WANG Z, WANG B, et al. Maximizing Intermediate Checkpoint Value in LLM Pretraining with Bayesian Optimization[C]. Proceedings of the 42nd International Conference on Machine Learning, New York: PMLR, 2025. |
| [37] | HENDRYCKS D, BURNS C, BASART S, et al. Measuring Massive Multitask Language Understanding[J]. arXiv Preprint arXiv:2009.03300, 2020. |
| [38] | COBBE K, KOSARAJU V, BAVARIAN M, et al. Training Verifiers to Solve Math Word Problems[J]. arXiv Preprint arXiv:2110.14168, 2021. |
| [39] | LI Y, MA Y, YAN S, et al. Model Merging in Pre-Training of Large Language Models[J]. arXiv Preprint arXiv:2505.12082, 2025. |
| [40] | YU S J, CHOI S. Parameter-Efficient Checkpoint Merging via Metrics-Weighted Averaging[J]. arXiv Preprint arXiv:2504.18580, 2025. |
| [41] | DUBEY A, JAUHRI A, PANDEY A, et al. The Llama 3 Herd of Models[J]. arXiv Preprint arXiv:2407.21783, 2024. |
| [42] | JIANG Z, LIN H, ZHONG Y, et al. MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs[C]. Proceedings of the 21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24), Berkeley: USENIX Association, 2024: 745-760. |
| [43] | WANG Y, SHI S, HE X, et al. Reliable and Efficient In-Memory Fault Tolerance of Large Language Model Pretraining[J]. arXiv Preprint arXiv:2310.12670, 2023. |
| [44] | LI Y, YANG S L, LIU C C, et al. Resilio: An Elastic Training Fault-Tolerant System for Large Models[J]. Journal of Computer Research and Development, 2025, 62(6): 1380-1395. |
| [45] | BLAGOEV N, ERSOY O, CHEN L Y. All Is Not Lost: LLM Recovery without Checkpoints[J]. arXiv Preprint arXiv:2506.15461, 2025. |
| [46] | MAURYA A, UNDERWOOD R, RAFIQUE M M, et al. DataStates-LLM: Lazy Asynchronous Checkpointing for Large Language Models[C]. Proceedings of the 33rd International Symposium on High-Performance Parallel and Distributed Computing, New York: ACM, 2024: 227-239. |
| [47] | DLROVER TEAM. Flash Checkpoint on DLRover: 千亿参数模型训练秒级导出 Checkpoint[EB/OL]. (2024-02-20) [2026-03-17]. https://github.com/intelligent-machine-learning/dlrover/blob/master/docs/blogs/flash_checkpoint_cn.md. |
| [48] | CHEN L. Deep Learning and Practice with MindSpore[M]. Singapore: Springer Nature, 2021. |
| [49] | CAI W, QIN L, HUANG J. MoC-System: Efficient Fault Tolerance for Sparse Mixture-of-Experts Model Training[C]. Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, New York:ACM, 2025: 655-671. |
| [50] | HUANG Z, NIE H, JIA H, et al. FlowCheck: Decoupling Checkpointing and Training of Large-Scale Models[C]. Proceedings of the 20th European Conference on Computer Systems, New York: ACM, 2025: 1334-1349. |
| [51] | KOROTEEV M V. BERT: A Review of Applications in Natural Language Processing and Understanding[J]. arXiv Preprint arXiv:2103.11943, 2021. |
| [52] |
LOSADA N, MARTÍN M J, RODRÍGUEZ G, et al. Portable Application-Level Checkpointing for Hybrid MPI-OpenMP Applications[J]. Procedia Computer Science, 2016, 80: 19-29.
doi: 10.1016/j.procs.2016.05.294 |
| [53] | WANG N, SUN Q, LIU Y, et al. Mitigating I/O Impact of Checkpointing on Large Scale Parallel Systems[C]. Proceedings of 2018 IEEE 20th International Conference on High Performance Computing and Communications; IEEE 16th International Conference on Smart City; IEEE 4th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), New York: IEEE, 2018: 117-123. |
| [54] | QIAN Y, YI R, DU Y, et al. Dynamic I/O Congestion Control in Scalable Lustre File System[C]. Proceedings of 2013 IEEE 29th Symposium on Mass Storage Systems and Technologies (MSST), New York: IEEE, 2013: 1-5. |
| [55] | CHIEN W D. Large-Scale I/O Models for Traditional and Emerging HPC Workloads on Next-Generation HPC Storage Systems[D]. Stockholm: Kungliga Tekniska Högskolan, 2022. |
| [56] | WAN B, HAN M, SHENG Y, et al. ByteCheckpoint: A Unified Checkpointing System for LLM Development[J]. arXiv Preprint arXiv:2407.20143, 2024. |
| [57] | NICOLAE B, LI J, WOZNIAK J M, et al. DeepFreeze: Towards Scalable Asynchronous Checkpointing of Deep Learning Models[C]. Proceedings of 2020 20th IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing (CCGRID), New York: IEEE, 2020: 172-181. |
| [58] | XIONG H, BIAN J, YANG S, et al. Natural Language Based Context Modeling and Reasoning with LLMs: A Tutorial[J]. arXiv Preprint arXiv:2309.15074, 2023. |
| [59] | KIRK R, MEDIRATTA I, NALMPANTIS C, et al. Understanding the Effects of RLHF on LLM Generalisation and Diversity[J]. arXiv Preprint arXiv:2310. 06452, 2023. |
| [60] | GUGGER S, DEBUT L, WOLF T, et al. Accelerate: Training and Inference at Scale Made Simple, Efficient and Adaptable[J]. Journal of Open Source Software, 2022. |
| [61] | WAGENLÄNDER M, LI G, ZHAO B, et al. Tenplex: Dynamic parallelism for deep learning using parallelizable tensor collections[C]. Proceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles (SOSP 2024), 2024: 195-210. |
| [62] | LIAN X, JACOBS S A, KURILENKO L, et al. Universal Checkpointing: Efficient and Flexible Checkpointing for Large Scale Distributed Training[J]. arXiv Preprint arXiv:2406.18820, 2024. |
| [63] | NARAYANAN D, SHOEYBI M, CASPER J, et al. Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM[C]. Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, New York: IEEE/ACM, 2021: 1-15. |
| [64] | ZHU T, QU X, DONG D, et al. Llama-MoE: Building Mixture-of-Experts from Llama with Continual Pre-Training[C]. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Stroudsburg: ACL, 2024: 15913-15923. |
| [65] | FRANTAR E, ALISTARH D. SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot[C]. Proceedings of the 40th International Conference on Machine Learning, New York: PMLR, 2023: 10323-10337. |
| [66] | ZHANG B W, WANG L, LI J, et al. Aquila2 Technical Report[J]. arXiv Preprint arXiv:2408.07410, 2024. |
| [67] | ZHANG S, DIAO L, WU C, et al. HAP: SPMD DNN Training on Heterogeneous GPU Clusters with Automated Program Synthesis[C]. Proceedings of the 19th European Conference on Computer Systems, New York: ACM, 2024: 524-541. |
| [68] | XU S, HUANG Z, ZENG Y, et al. HETHUB: A Distributed Training System with Heterogeneous Cluster for Large-Scale Models[J]. IEEE Transactions on Parallel and Distributed Systems, 2024. |
| [69] | SHOEYBI M, PATWARY M, PURI R, et al. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism[J]. arXiv Preprint arXiv:1909.08053, 2019. |
| [70] | ZHAO Y, GU A, VARMA R, et al. PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel[J]. arXiv Preprint arXiv:2304.11277, 2023. |
| [71] | RASLEY J, RAJBHANDARI S, RUWASE O, et al. DeepSpeed: System Optimizations Enable Training Deep Learning Models with over 100 Billion Parameters[C]. Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, New York: ACM, 2020: 3505-3506. |
| No related articles found! |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||