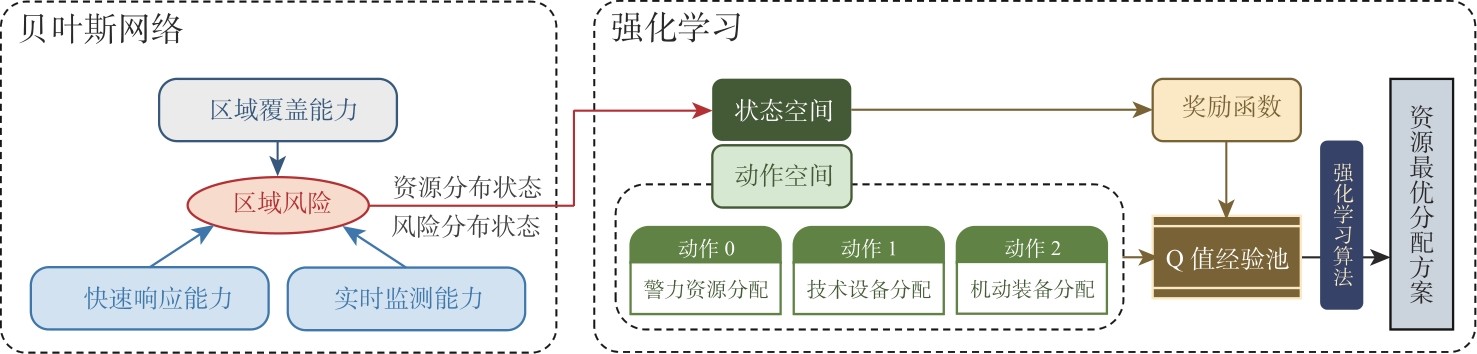
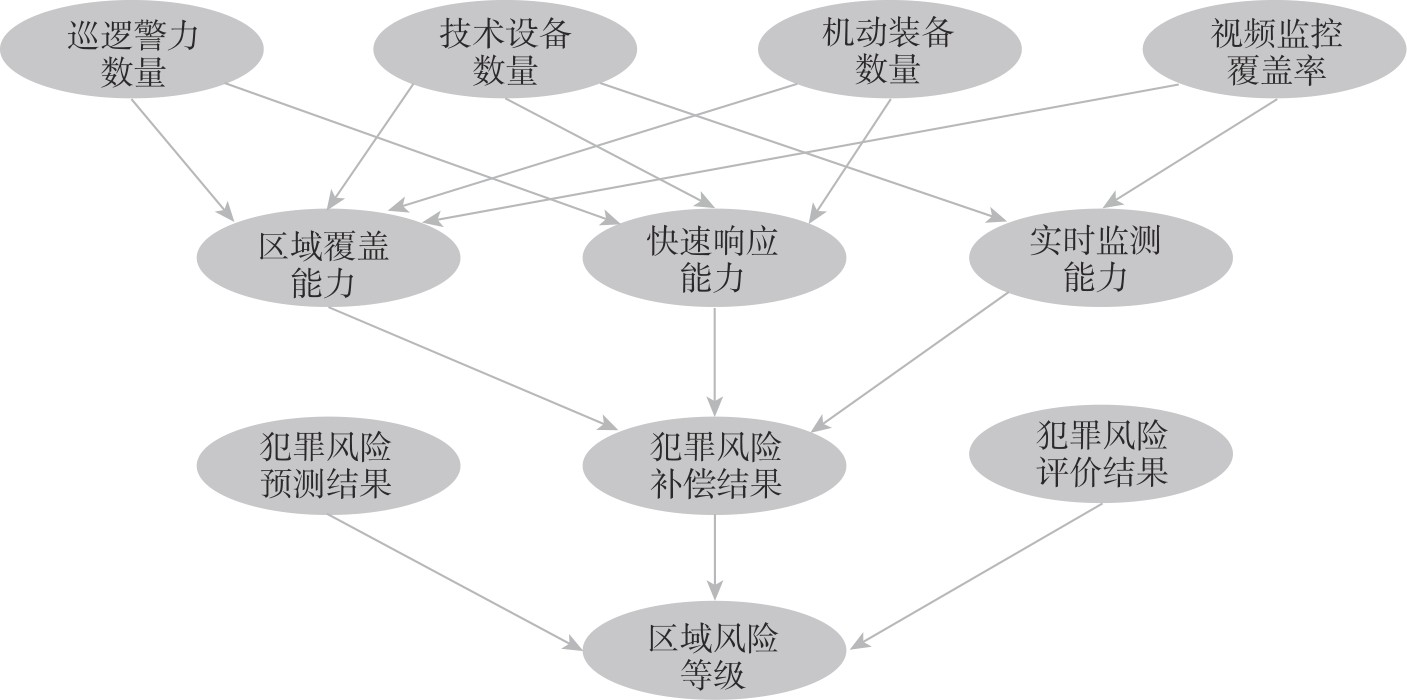
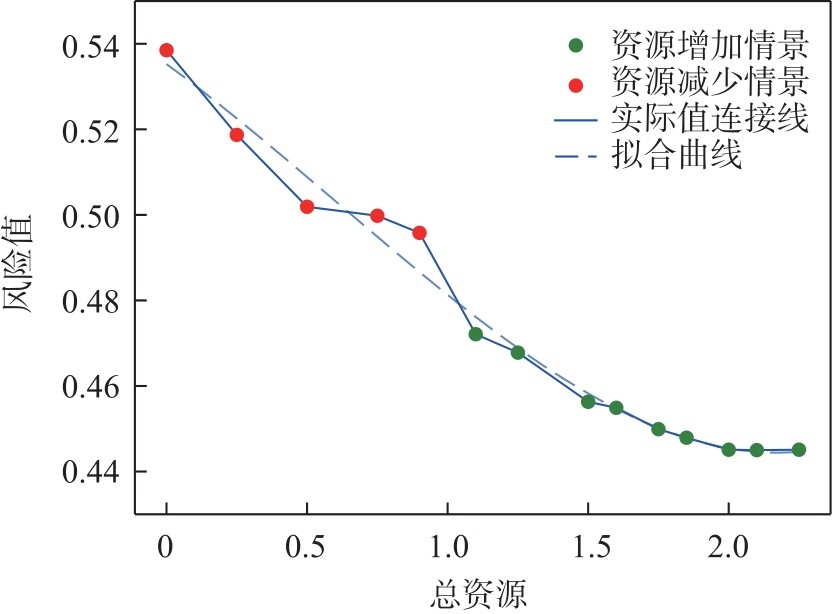
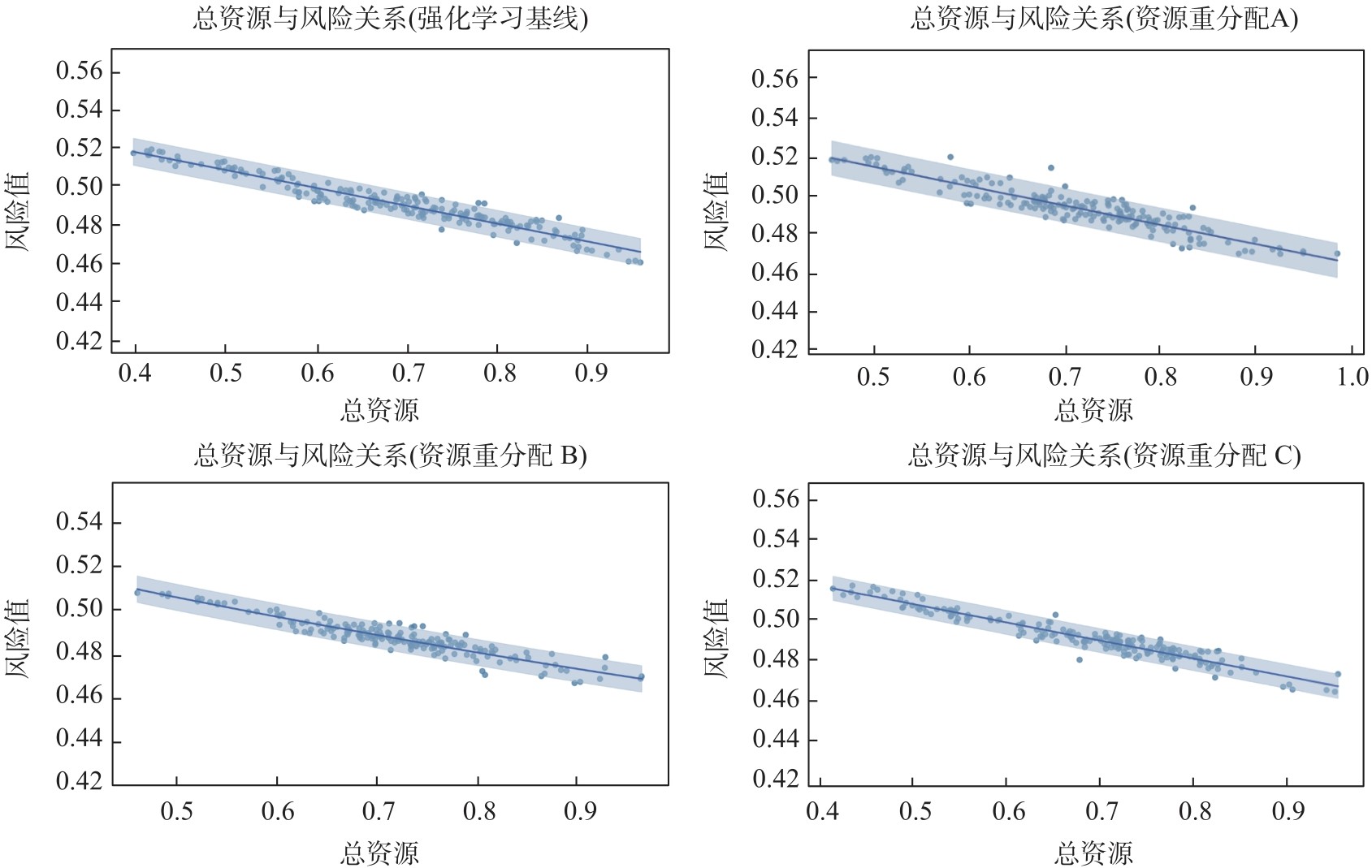
| [1] |
WANG Z, ZHANG H. Construction, detection, and interpretation of crime patterns over space and time[J]. ISPRS International Journal of Geo-Information, 2020, 9(6): 339.
doi: 10.3390/ijgi9060339
|
| [2] |
LEE J, LEITNER M, PAULUS G. Spatiotemporal analysis of nighttime crimes in vienna, austria[J]. ISPRS International Journal of Geo-Information, 2024, 13(7): 247.
doi: 10.3390/ijgi13070247
|
| [3] |
FEROOZ F, HASSAN M T, MAHMOOD S, et al. Risk and pattern analysis of pakistani crime data using unsupervised learning techniques[J]. Applied Sciences, 2022, 12(7): 3675.
doi: 10.3390/app12073675
|
| [4] |
YANG M, CHEN Z, ZHOU M, et al. The impact of COVID-19 on crime: a spatial temporal analysis in chicago[J]. ISPRS International Journal of Geo-Information, 2021, 10(3): 152.
doi: 10.3390/ijgi10030152
|
| [5] |
HEYER D G, MITCHELL M, GANESH S, et al. An Econometric Method of Allocating Police Resources[J]. International Journal of Police Science & Management, 2008, 10 (2): 192-213.
|
| [6] |
PARK J K. A study on the optimal police workforce distribution at the patrol division and the police substation: focused on busan city[J]. The Korean Journal of Local Government Studies, 2017, 21(2): 353-378.
doi: 10.20484/klog.21.2.15
|
| [7] |
赵雪峰, 李金林, 罗钦, 等. 基于排队模型的警力人员排班计划[J]. 数学的实践与认识, 2016, 46(11): 132-142.
|
| [8] |
胡正华, 周继彪, 郭旭, 等. 基于排队论的道路交通警力资源配置研究[J]. 中国安全科学学报, 2024, 34(7): 178-185.
doi: 10.16265/j.cnki.issn1003-3033.2024.07.0153
|
| [9] |
刘忠轶, 解易, 高岩, 等. 基于DEA模型的警力资源配置效率研究[J]. 中国人民公安大学学报(社会科学版), 2015, 31(6): 58-64.
|
| [10] |
彭怀军, 秦勇, 张尊栋, 等. 基于遗传算法的二元覆盖模型在交通警力部署中的应用[J]. 公路交通科技, 2016, 33(10): 125-130.
|
| [11] |
景海涛, 原世伟, 李伟. 警力快速响应及其空间布局优化[J]. 测绘工程, 2017, 26(1): 42-46.
|
| [12] |
ZHANG N, HAORAN X, JIANG F, et al. Police resource distribution in China: spatial decision making based on PGIS-MCDA method[J]. Policing: An International Journal, 2022, 45(6): 956-971.
doi: 10.1108/PIJPSM-03-2022-0042
|
| [13] |
周昱林, 刘树光, 王柯. 基于改进贝叶斯网络的察打一体无人机使用安全评估[J]. 空军工程大学学报, 2025, 26(3): 86-95.
|
| [14] |
李明轩, 韩宏伟, 刘浩杰, 等. 基于数据分布域变换与贝叶斯神经网络的渗透率预测及不确定性估计[J]. 地球物理学报, 2023, 66(4): 1664-1680.
|
| [15] |
赵佳楠, 胡晓辉, 杜欣欣. 基于近端策略优化算法的车载边缘计算网络频谱资源分配[J]. 数据与计算发展前沿, 2022, 4(4): 142-155.
|
| [16] |
沈林江, 仇树卿, 崔超, 等. “东数西算”下的高效数据流通策略研究[J]. 数据与计算发展前沿, 2023, 5(5): 3-12.
|
| [17] |
WANG T, TAN X, TIAN Y, et al. Risk assessment based on bayesian network for the typhoon-storm surge-flood-dike burst disaster chain: a case study of guangdong, china[J]. Journal of Hydrology: Regional Studies, 2025, 58: 102251.
doi: 10.1016/j.ejrh.2025.102251
|
| [18] |
WANG W, ZHAO J, CHEN Y, et al. Process safety enhancement in maritime operations: a bayesian network-based risk assessment framework for the RCEP region[J]. Process Safety and Environmental Protection, 2025, 194: 1235-1256.
doi: 10.1016/j.psep.2024.12.072
|
| [19] |
ZANGENEHMADAR Z, MOSELHI O. Prioritizing deterioration factors of water pipelines using delphi method[J]. Measurement, 2016, 90: 491-499.
doi: 10.1016/j.measurement.2016.05.001
|
| [20] |
ZHOU Y, LI Y, SHENG A, et al. A nonlinear multi-player non-zero-sum differential game with state constraints and input delay[J]. Nonlinear Dynamics, 2025, 113(6): 5383-5408.
doi: 10.1007/s11071-024-10493-2
|
| [21] |
TAAMS A C, HERBERTS C A, EGBERTS A C G, et al. Uncertainties about the benefit-risk balance of oncology medicines assessed by the european medicines agency[J]. ESMO Open, 2024, 9(12): 103991.
doi: 10.1016/j.esmoop.2024.103991
|
| [22] |
NORTMANN B, SASSANO M, MYLVAGANAM T. Feedback nash equilibria for scalar N-player linear quadratic dynamic games[J]. Automatica, 2025, 174: 112133.
doi: 10.1016/j.automatica.2025.112133
|
| [23] |
张立, 段明达, 万剑雄, 等. 车联网区块链吞吐量优化的深度强化学习方法研究[J]. 计算机科学与探索, 2023, 17 (7): 1708-1718.
doi: 10.3778/j.issn.1673-9418.2205019
|
| [24] |
徐东红, 花旭, 等. 无服务器环境下基于DQN和用户意图的函数放置研究[J]. 计算机应用研究, 2023, 40(12): 3747-3753.
|
| [25] |
时高松, 赵清海, 董鑫, 等. 基于ppo算法的自动驾驶人机交互式强化学习方法[J]. 计算机应用研究, 2024, 41(9): 2732-2736.
|
| [26] |
熊康, 刘思聪, 王宏涛, 等. 面向无人机协同定位的机载深度计算编译优化[J]. 计算机科学与探索, 2025, 19(1): 141-157.
doi: 10.3778/j.issn.1673-9418.2404077
|
| [27] |
ISIK V, KAYAHAN M B, ABUTAHUN I H, et al. Influence of operator’s experience on mechanical properties of nickel-titanium instruments after usage[J]. Australian Endodontic Journal: the Journal of the Australian Society of Endodontology Inc, 2025.
|
| [28] |
胡伟, 郑婷婷, 杜璞良. 基于可迁移深度强化学习的虚拟电厂优化调度问题研究[J]. 工业工程与管理, 2025, 30(4): 1-12.
|
 ),MA Qiuping1,WANG Runsheng2,HU Jinming1,3,HU Xiaofeng1,3,*(
),MA Qiuping1,WANG Runsheng2,HU Jinming1,3,HU Xiaofeng1,3,*(