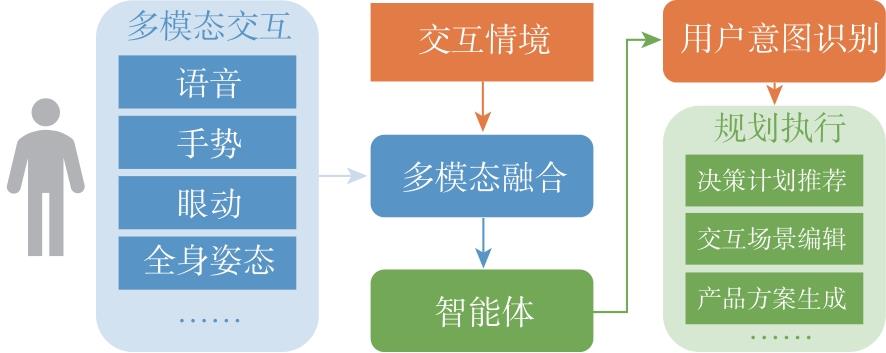
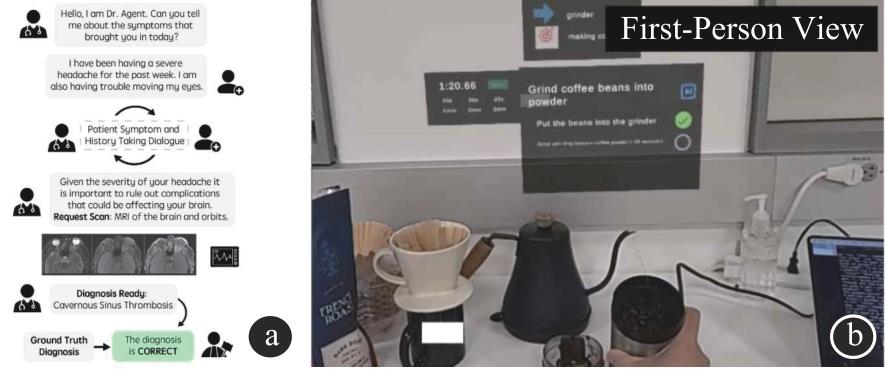
| [1] |
PEARL C. Designing voice user interfaces: Principles of conversational experiences[M]. O’Reilly Media, Inc., 2016:1-278.
|
| [2] |
YASEN M, JUSOH S. A systematic review on hand gesture recognition techniques, challenges and applications[J]. PeerJ Computer Science, 2019, 5: e218.
|
| [3] |
HOLMQVIST K, NYSTRÖM M, ANDERSSON R, et al. Eye tracking: A comprehensive guide to methods and measures[M]. oup Oxford, 2011: 1-560.
|
| [4] |
ACHIAM J, ADLER S, AGARWAL S, et al. Gpt-4 technical report[J]. arXiv preprint arXiv: 2303.08774, 2023.
|
| [5] |
LIU H, LI C, WU Q, et al. Visual instruction tuning[J]. Advances in neural information processing systems, 2023, 36: 34892-34916.
|
| [6] |
LAKOMKIN E, ZAMANI M A, WEBER C, et al. Incorporating end-to-end speech recognition models for sentiment analysis[C]// 2019 International Conference on Robotics and Automation (ICRA), IEEE, 2019: 7976-7982.
|
| [7] |
SCHAFFER S, REITHINGER N. Benefit, design and evaluation of multimodal interaction[C]// Proceedings of the 2016 DSLI Workshop. ACM CHI. 2016:1-6.
|
| [8] |
ACHERKI C, NIGAY L, ROY Q, et al. An Evaluation of Spatial Anchoring to position AR Guidance in Arthroscopic Surgery[C]// Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, 2025: 1-17.
|
| [9] |
RAHMAN Y, ASISH S M, FISHER N P, et al. Exploring eye gaze visualization techniques for identifying distracted students in educational VR[C]// 2020 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), IEEE, 2020: 868-877.
|
| [10] |
CHO H, FASHIMPAUR J, SENDHILNATHAN N, et al. Persistent Assistant: Seamless Everyday AI Interactions via Intent Grounding and Multimodal Feedback[C]// Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, 2025: 1-19.
|
| [11] |
TAO J, WU Y, YU C, et al. 多模态人机交互综述[J]. Journal of Image and Graphics, 2022, 27(6): 1956-1987.
|
| [12] |
苟超, 卓莹, 王康, 等. 眼动跟踪研究进展与展望[J]. 自动化学报, 2022, 48(5): 1173-1192.
|
| [13] |
TANRIVERDI V, JACOB R J K. Interacting with eye movements in virtual environments[C]// Proceedings of the SIGCHI conference on Human Factors in Computing Systems, 2000: 265-272.
|
| [14] |
KHAMIS M, ALT F, BULLING A. The past, present, and future of gaze-enabled handheld mobile devices: Survey and lessons learned[C]// Proceedings of the 20th International Conference on Human-Computer Interaction with Mobile Devices and Services, 2018: 1-17.
|
| [15] |
RAYNER K. Eye movements in reading and information processing: 20 years of research[J]. Psychological bulletin, 1998, 124(3): 372.
doi: 10.1037/0033-2909.124.3.372
pmid: 9849112
|
| [16] |
SHI D, WANG Y, BAI Y, et al. Chartist: Task-driven Eye Movement Control for Chart Reading[J]. arXiv preprint arXiv:2502.03575, 2025.
|
| [17] |
LUGARESI C, TANG J, NASH H, et al. Mediapipe: A framework for building perception pipelines[J]. arXiv preprint arXiv: 1906.08172, 2019.
|
| [18] |
KALANDAR B, DWORAKOWSKI Z. Sign Language Conversation Interpretation Using Wearable Sensors and Machine Learning[J]. arXiv preprint arXiv: 2312.11903, 2023.
|
| [19] |
Y ZHANG, B ENS, K A SATRIADI, et al. TimeTables: Embodied Exploration of Immersive Spatio-Temporal Data[C]. IEEE Conference on Virtual Reality and 3D User Interfaces (VR), 2022: 599-605.
|
| [20] |
WAGNER U, LYSTBÆK M N, MANAKHOV P, et al. A fitts’ law study of gaze-hand alignment for selection in 3d user interfaces[C]// Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, 2023: 1-15.
|
| [21] |
马晗, 唐柔冰, 张义, 等. 语音识别研究综述[J]. 计算机系统应用, 2022, 31(1): 1-10.
|
| [22] |
ZHANG D, ZHANG X, ZHAN J, et al. Speechgpt-gen: Scaling chain-of-information speech generation[J]. arXiv preprint arXiv:2401.13527, 2024.
|
| [23] |
WANG P. Research and design of smart home speech recognition system based on deep learning[C]// 2020 International Conference on Computer Vision, Image and Deep Learning (CVIDL), IEEE, 2020: 218-221.
|
| [24] |
JARADAT G A, ALZUBAIDI M A, OTOOM M. A novel human-vehicle interaction assistive device for Arab drivers using speech recognition[J]. IEEE Access, 2022, 10: 127514-127529.
|
| [25] |
FURTADO J S, LIU H H T, LAI G, et al. Comparative analysis of optitrack motion capture systems[C]// Advances in Motion Sensing and Control for Robotic Applications: Selected Papers from the Symposium on Mechatronics, Robotics, and Control (SMRC’18)-CSME International Congress 2018, May 27-30, 2018 Toronto, Canada, Springer International Publishing, 2019: 15-31.
|
| [26] |
GUO J, LUO J, WEI Z, et al. TelePhantom: A User-Friendly Teleoperation System with Virtual Assistance for Enhanced Effectiveness[J]. arXiv preprint arXiv: 2412.13548, 2024.
|
| [27] |
DONG J, FANG Q, JIANG W, et al. Fast and robust multi-person 3d pose estimation and tracking from multiple views[J]. IEEE transactions on pattern analysis and machine intelligence, 2021, 44(10): 6981-6992.
|
| [28] |
MEHRABAN S, ADELI V, TAATI B. Motionagformer: Enhancing 3d human pose estimation with a transformer-gcnformer network[C]// Proceedings of the IE- EE/CVF winter conference on applications of computer vision, 2024: 6920-6930.
|
| [29] |
YE J, YU Y, WANG Q, et al. CmdVIT: A Voluntary Facial Expression Recognition Model for Complex Mental Disorders[J]. IEEE Transactions on Image Processing, 2025, 34: 3013-3024.
|
| [30] |
ZHU W, MA X, LIU Z, et al. Motionbert: A unified perspective on learning human motion representations[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023: 15085-15099.
|
| [31] |
HU Y, ZHANG S, DANG T, et al. Exploring large-scale language models to evaluate eeg-based multimodal data for mental health[C]// Companion of the 2024 on ACM International Joint Conference on Pervasive and Ubiquitous Computing, 2024: 412-417.
|
| [32] |
KUANG B, LI X, LI X, et al. The effect of eye gaze direction on emotional mimicry: A multimodal study with electromyography and electroencephalography[J]. NeuroImage, 2021, 226: 117604.
|
| [33] |
WANG Y, HUANG W, SUN F, et al. Deep multimodal fusion by channel exchanging[J]. Advances in neural information processing systems, 2020, 33: 4835-4845.
|
| [34] |
DEBIE E, ROJAS R F, FIDOCK J, et al. Multimodal fusion for objective assessment of cognitive workload: A review[J]. IEEE transactions on cybernetics, 2019, 51(3): 1542-1555.
|
| [35] |
VERE S, BICKMORE T. A basic agent[J]. Computational intelligence, 1990, 6(1): 41-60.
|
| [36] |
GRANTER S R, BECK A H, PAPKE JR D J. AlphaGo, deep learning, and the future of the human microscopist[J]. Archives of pathology & laboratory medicine, 2017, 141(5): 619-621.
|
| [37] |
LIU A, FENG B, XUE B, et al. Deepseek-v3 technical report[J]. arXiv preprint arXiv: 2412.19437, 2024.
|
| [38] |
GONG R, HUANG Q, MA X, et al. Mindagent: Emergent gaming interaction[J]. arXiv preprint arXiv:2309.09971, 2023.
|
| [39] |
YU J, WANG X, TU S, et al. Kola: Carefully benchmarking world knowledge of large language models[J]. arXiv preprint arXiv:2306.09296, 2023.
|
| [40] |
DURANTE Z, HUANG Q, WAKE N, et al. Agent ai: Surveying the horizons of multimodal interaction[J]. arXiv preprint arXiv: 2401.03568, 2024.
|
| [41] |
WU Q, BANSAL G, ZHANG J, et al. Autogen: Enabling next-gen llm applications via multi-agent conversation[J]. arXiv preprint arXiv:2308.08155, 2023.
|
| [42] |
QIAN C, LIU W, LIU H, et al. Chatdev: Communicative agents for software development[J]. arXiv preprint arXiv: 2307.07924, 2023.
|
| [43] |
HONG S, ZHENG X, CHEN J, et al. Metagpt: Meta programming for multi-agent collaborative framework[J]. arXiv preprint arXiv:2308.00352, 2023, 3(4): 6.
|
| [44] |
HONG Y, ZHEN H, CHEN P, et al. 3d-llm: Injecting the 3d world into large language models[J]. Advances in Neural Information Processing Systems, 2023, 36: 20482-20494.
|
| [45] |
JATAVALLABHULA K M, SARYAZDI S, IYER G, et al. gradSLAM: Automagically differentiable SLAM[J]. arXiv preprint arXiv:1910.10672, 2019.
|
| [46] |
MILDENHALL B, SRINIVASAN P P, TANCIK M, et al. Nerf: Representing scenes as neural radiance fields for view synthesis[J]. Communications of the ACM, 2021, 65(1): 99-106.
|
| [47] |
CAO Y, JIANG P, XIA H. Generative and Malleable User Interfaces with Generative and Evolving Task-Driven Data Model[J]. arXiv preprint arXiv:2503.04084, 2025.
|
| [48] |
ZHAO Z, CHAI W, WANG X, et al. See and think: Embodied agent in virtual environment[C]// European Conference on Computer Vision, Springer, Cham, 2025: 187-204.
|
| [49] |
KIRCHNER E A, FAIRCLOUGH S H, KIRCHNER F. Embedded multimodal interfaces in robotics: applications, future trends, and societal implications[M]// The Handbook of Multimodal-Multisensor Interfaces: Language Processing, Software, Commercialization, and Emerging Directions-Volume 3, 2019: 523-576.
|
| [50] |
尤明辉, 殷亚凤, 谢磊, 等. 基于行为感知的用户画像技术[J]. 浙江大学学报 (工学版), 2021, 55(4): 608-614.
|
| [51] |
QIAN C, HE B, ZHUANG Z, et al. Tell me more! towards implicit user intention understanding of language model driven agents[J]. arXiv preprint arXiv:2402.09205, 2024.
|
| [52] |
TRICK S, KOERT D, PETERS J, et al. Multimodal uncertainty reduction for intention recognition in human-robot interaction[C]// 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, 2019: 7009-7016.
|
| [53] |
GÖLDI A, RIETSCHE R, UNGAR L. Efficient Management of LLM-Based Coaching Agents’ Reasoning While Maintaining Interaction Quality and Speed[C]// Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, 2025: 1-18.
|
| [54] |
PERERA M, ANANTHANARAYAN S, GONCU C, et al. The Sky is the Limit: Understanding How Generative AI can Enhance Screen Reader Users’ Experience with Productivity Applications[C]// Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, 2025: 1-17.
|
| [55] |
SAAB K, TU T, WENG W H, et al. Capabilities of gemini models in medicine[J]. arXiv preprint arXiv:2404.18416, 2024.
|
| [56] |
LI B, YAN T, PAN Y, et al. Mmedagent: Learning to use medical tools with multi-modal agent[J]. arXiv preprint arXiv: 2407.02483, 2024.
|
| [57] |
SCHMIDGALL S, ZIAEI R, HARRIS C, et al. AgentClinic: a multimodal agent benchmark to evaluate AI in simulated clinical environments[J]. arXiv preprint arXiv: 2405.07960, 2024.
|
| [58] |
TSAI H R, CHIU S K, WANG B. GazeNoter: Co-Piloted AR Note-Taking via Gaze Selection of LLM Suggestions to Match Users’ Intentions[J]. arXiv preprint arXiv:2407.01161, 2024.
|
| [59] |
WANG R, ZHOU X, QIU L, et al. Social-RAG: Retrieving from Group Interactions to Socially Ground AI Generation[C]// Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, 2025: 1-25.
|
| [60] |
PICKERING M, WILLIAMS H, GAN A, et al. How Humans Communicate Programming Tasks in Natural Language and Implications For End-User Programming with LLMs[C]// Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, 2025: 1-34.
|
| [61] |
CAO Y, JIANG P, XIA H. Generative and Malleable User Interfaces with Generative and Evolving Task-Driven Data Model[J]. arXiv preprint arXiv:2503.04084, 2025.
|
| [62] |
DE LA TORRE F, FANG C M, HUANG H, et al. Llmr: Real-time prompting of interactive worlds using large language models[C]// Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems, 2024: 1-22.
|
| [63] |
PENG X, KOCH J, MACKAY W E. FusAIn: Composing Generative AI Visual Prompts Using Pen-based Interaction[C]// Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, 2025: 1-20.
|
| [64] |
ZHANG T, AU YEUNG C, AURELIA E, et al. Prompting an Embodied AI Agent: How Embodiment and Multimodal Signaling Affects Prompting Behaviour[C]// Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, 2025: 1-25.
|
| [65] |
ZHANG C, YANG Z, LIU J, et al. Appagent: Multimodal agents as smartphone users[C]// Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, 2025: 1-20.
|
| [66] |
LI C, WU G, CHAN G Y Y, et al. Satori 悟り: Towards Proactive AR Assistant with Belief-Desire-Intention User Modeling[C]// Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, 2025: 1-24.
|
| [67] |
CHO H, FASHIMPAUR J, SENDHILNATHAN N, et al. Persistent Assistant: Seamless Everyday AI Interactions via Intent Grounding and Multimodal Feedback[C]// Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, 2025: 1-19.
|
| [68] |
QIN Y, HU S, LIN Y, et al. Tool learning with foundation models[J]. ACM Computing Surveys, 2024, 57(4): 1-40.
|
| [69] |
ZUO H, LIU R, ZHAO J, et al. Exploiting modality-invariant feature for robust multimodal emotion recognition with missing modalities[C]// ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2023: 1-5.
|
| [70] |
LI M, ZHAO S, WANG Q, et al. Embodied agent interface: Benchmarking llms for embodied decision making[J]. Advances in Neural Information Processing Systems, 2024, 37: 100428-100534.
|
 ),TIAN Dong1,2,DONG Yu1,2,QIAO Na3,SHAN Guihua1,2,*(
),TIAN Dong1,2,DONG Yu1,2,QIAO Na3,SHAN Guihua1,2,*(