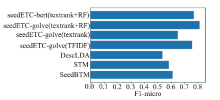
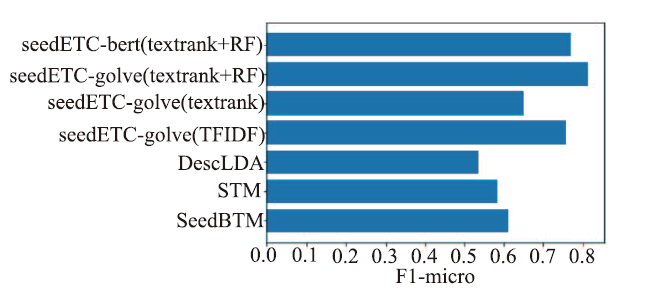
| [1] |
张军泽, 王帅, 赵文武, 刘焱序, 傅伯杰. 可持续发展目标关系研究进展[J]. 生态学报, 2019,39(22):8327-8337.
|
| [2] |
李树深. 数据与计算是科技创新的巨大驱动力[J]. 数据与计算发展前沿, 2019,1(1):1.
|
| [3] |
孙哲南, 张兆翔, 王威, 刘菲, 谭铁牛. 2019年人工智能新态势与新进展[J]. 数据与计算发展前沿, 2019,1(2):1-16.
|
| [4] |
Song J, Hu R, Sun B, et al. Research on News Keyword Extraction Based on TF-IDF and Chinese Features[C]. Huhhot: 2019 2nd International Conference on Financial Management, 2019:344-352.
|
| [5] |
Matsuo Y, Ishizuka M. Keyword Extracyion from a Single Document Using Word Cooccurrence Statistical Informa-tion[J]. International Journal on Artificial Intelligence Tools, 2008,13(1):157-169.
doi: 10.1142/S0218213004001466
|
| [6] |
罗燕, 赵书良, 李晓超, 等. 基于词频统计的文本关键词提取方法[J]. 计算机应用, 2016,36(3):718-725.
|
| [7] |
Barker K, Cornacchia N. Using Noun Phrase Heads to Extract Document Keyphrases[C]. Quebec: Proceedings of the 13th Biennial Conference of the Canadian Society on Computational Studies of Intelligence: 2000: 40-52.
|
| [8] |
Mihalcea R, Tarau P. TextRank: Bringing Order into Texts[C]. Barcelona: Proceedings of Conference on Empirical Methods in Natural Language Processing, 2004: 404-411.
|
| [9] |
Bellaachia, Abdelghani, M. Al-Dhelaan. NE-Rank: A Novel Graph-Based Keyphrase Extraction in Twitter[C]. The ssaloniki: IEEE/WIC/ACM International Conferences on Web Intelligence & Intelligent Agent Technology ACM, 2012(1):372-379.
|
| [10] |
Saroj Kr. Biswas, Monali Bordoloi, Jacob Shreya. A Graph Based Keyword Extraction Model using Collective Node Weight[J]. Expert Systems with Applications, 2017,97(5):51-59.
doi: 10.1016/j.eswa.2017.12.025
|
| [11] |
Thomas Hofmann. Probabilistic latent semantic anal-ysis[C]. San Francisco: Proc of the 15th Annual Conf on Uncertainty in Artificial Intelligence, 1999:289-296.
|
| [12] |
Blei D, Ng A, Jordan M. Latent Dirichlet allocation[J]. Journal of Machine Learning Research, 2003,1(3):993-1022.
|
| [13] |
Le Q V, Mikolov T. Distributed Representatoins of Sen-tences and Documents[C]. Banff: ICML'14: Proceed-ings of the 31st International Conference on International Conference on Machine Learning. 2014,32:1188-1196.
|
| [14] |
石晶, 李万龙. 基于LDA模型的主题词抽取方法[J]. 计算机工程, 2010,36(19):81-83.
|
| [15] |
刘啸剑, 谢飞. 结合主题分布与统计特征的关键词抽取方法[J]. 计算机工程, 2017,043(007):217-222.
|
| [16] |
Druck G, Mann G, Mccallum A. Learning from labeled features using generalized expectation criteria[C]. Sing-apore: Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Infor-mation Retrieval, 2008:595-602.
|
| [17] |
M Chang, L. Ratinov, D. Roth, V. Srikumar. Importance of semantic representation: Dataless classification[C]. Proceedings of the 23rd national conference on Artificial intelligence, 2008,830-835.
|
| [18] |
Y Song and D. Roth. On dataless hierarchical text classi-fication[C]. Quebec: Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, 2014:1579-1585.
|
| [19] |
Yunqing Xia, Peng Jin, Xingyuan Chen, et al. Dataless Text Classification with Descriptive LDA[C]. Austin: Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, 2015:2224-2231.
|
| [20] |
Li C, Xing J, Sun A, et al. Effective Document Labeling with Very Few Seed Words: A Topic Model Approach[C]. Indianapolis: Proceedings of the 25th ACM International on Conference on Information and Knowledge Manag-ement, 2016:85-94.
|
| [21] |
Yang Y, Wang H, Zhu J, et al. Dataless Short Text Classifi-cation Based on Biterm Topic Model and Word Embed-dings[C]. Yokohama: Twenty-Ninth International Joint Conference on Artificial Intelligence and Seventeenth Pa-cific Rim International Conference on Artificial Intelligence, 2020:3969-3975.
|
| [22] |
张博锋, 白冰, 苏金树. 基于自训练算法的半监督文本分类[J]. 国防科技大学学报, 2007,29(6):65-69.
|
| [23] |
陈涛, 安俊秀. 基于特征融合的微博短文本情感分类研究[J]. 数据与计算发展前沿, 2020,2(6):21-29.
|
| [24] |
Deerwesster S, Dumais S T, Furnas G W, et al. Indexing by latent semantic analysis[J]. Journal of the American Society for Information Science, 1990,41(6):391-407.
doi: 10.1002/(ISSN)1097-4571
|
| [25] |
Mikolov T, Chen K, Corrado G, et al. Efficient Estimation of Word Representations in Vector Space[J]. Advances in Neural Information Processing Systems, 2013,1(26):3111-3119.
|
| [26] |
Pennington J, Socher R, Manning CD. GloVe: Global vectorsfor word representation[C]. Doha: Proceedings of 2014 Conference on Empirical Methods in Natural Lan-guage Processing. 2014:1532-1543.
|
| [27] |
Devlin J, Chang M W, Lee K, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Unders-tanding[J/OL]. 2018. https://arxiv.org/pdf/1810.04805.pdf .
|
| [28] |
Peter J Rousseeuw. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis[J]. Journal of Computational & Applied Mathematics, 1987,1(20):53-65.
|
| [29] |
姜震, 詹永照. 半监督分类中的噪声控制及相关算法[J]. 江苏大学学报自然科学版, 2015,36(4):435-438.
|
| [30] |
United Nations. SDG Indicators Metadata repository[EB/OL]. [2020-10-01]. https://unstats.un.org/sdgs/metadata/ .
|
| [31] |
United Nations. SDG indicators : United Nations Global SDG Database[EB/OL]. [2021-03-01]. https://unstats.un.org/sdgs/indicators/database/ .
|
| [32] |
Wagner R B W. Natural Language Processing with Py-thon, Analyzing Text with the Natural Language Toolkit by Steven Bird; Ewan Klein; Edward Loper[J]. Language Resources and Evaluation, 2010,44(4):421-424.
doi: 10.1007/s10579-010-9124-x
|
| [33] |
Stanfordnlp. GloVe: Global Vectors for Word Represen-tation[EB/OL]. [2015-10-01]. https://nlp.stanford.edu/data/wordvecs/glove.6B.zip .
|
| [34] |
Google research. Bert[EB/OL].[2020-03-11]. https://storage.googleapis.com/bert_models/2020_02_20/unca-sed_L-4_H-256_A-4.zip .
|
 ),LI Jianhui1,*(
),LI Jianhui1,*(