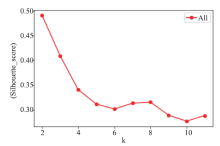
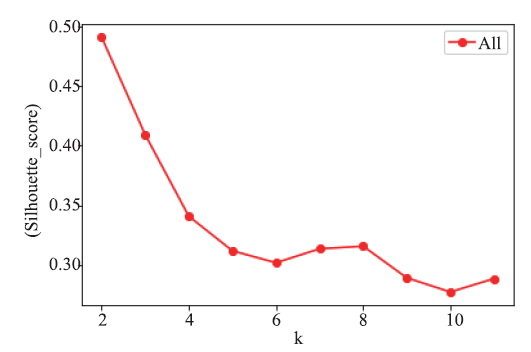
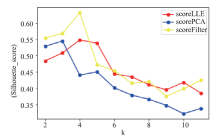
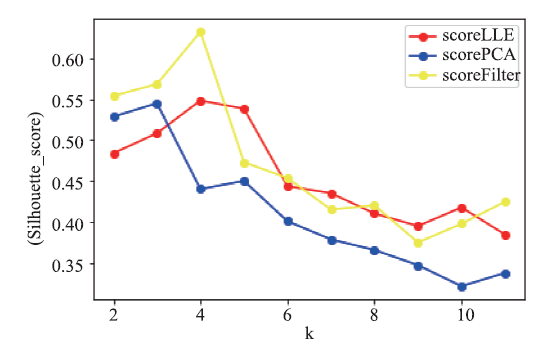
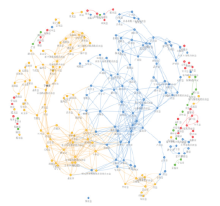
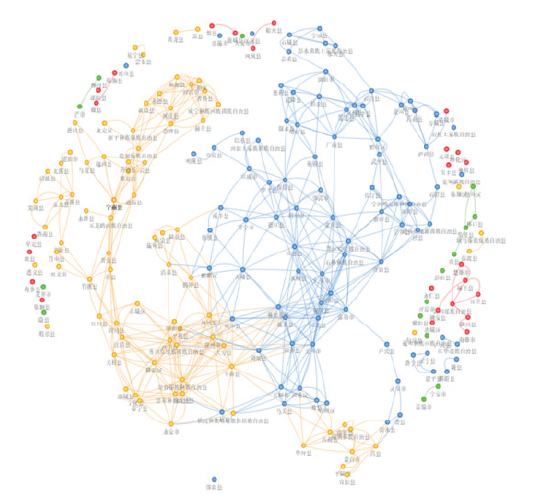
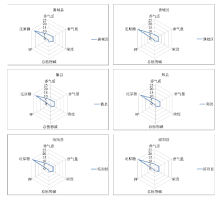
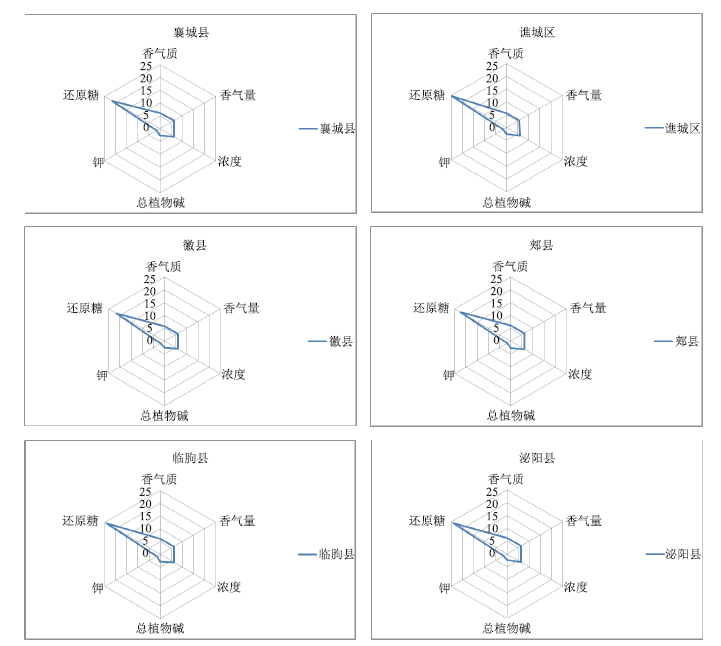
Frontiers of Data and Computing ›› 2021, Vol. 3 ›› Issue (1): 112-121.
doi: 10.11871/jfdc.issn.2096-742X.2021.01.009
• Technology and Applicaton • Previous Articles
ZHAI Qingchen1,3( ),ZHOU Yuanchun1(),SONG Qiucheng1(),WANG Jianwei2(),MENG Zhen1,*(),ZHANG Yanling2,*()
),ZHOU Yuanchun1(),SONG Qiucheng1(),WANG Jianwei2(),MENG Zhen1,*(),ZHANG Yanling2,*()